@thePartyPartyUS@ClementDelangue But.. it is way better? Silently degrading is extremely bad, this is just bad. We can admit this is better while not calling it "good"
@latkins yeah this is scary for even open source development, who's to say Fable doesn't consider llama.cpp, VLLM, exllamav3 all to be competing frontier models? And we'll never actually know because the performance is silently automatically nerfed? Seems sketchy, hope they reverse..
@dudeman6790 I mean if it's just being done with the spotlight/perpetual online-ness, I fully support that and more power to them :)
But just hate not knowing if they're okay
Anyone know what happened to Yorkie..?
I guess I'm a bit late to the party, but seems they went and deleted their discord, X, and github :( if you're out there Yorkie, hope you're okay, feel free to DM or email, just to let me know you're alive
Introducing the Trinity Builders Program.
This is a community credit grant that gives developers, researchers, and open-source builders free inference access to Trinity models on our API.
Why we're doing it: Open weights only go so far if you don't have the compute to actually build with them. We want to lower that barrier so you can run experiments, iterate, and ship real systems.
Who this is for:
- Open-source projects
- Research initiatives
- Prototypes and production applications
- Developer tooling
Grants range from < 50M tokens to > 1B tokens, allocated based on your submitted project.
Submitting an application does not guarantee approval. We'll review requests on a best-effort basis, and allocation depends on compute capacity, token budgets, and other operational priorities.
We can't wait to see what the community builds with Trinity.
Learn more and apply here: https://t.co/6IUkVgmZ0E
Today we're releasing Trinity-Large-Thinking.
Available now on the Arcee API, with open weights on Hugging Face under Apache 2.0.
We built it for developers and enterprises that want models they can inspect, post-train, host, distill, and own.
@altryne@AnthropicAI Honestly the thing that surprises me most is that they don't have any kind of "I'm patient" mode, where each individual prompt is slower but only because they're doing aggressive batching to save costs/usage, I'd be more than happy to wait twice as long (sometimes) for more usage
Forgot to update the Qwen 0.8B - 9B models with the F32 ssm_alpha and ssm_beta weights, redoing now :)
If you were getting lower performance, in particular speed-wise, it may do you well to redownload (especially on strix halo apparently?)
Alright, I've added the mean and 99.9% KLD, and the mean and same top P statistics to https://t.co/SH3LZO75OI README
This is more of a one-off, but I will explore doing it more regularly in the future, just gotta figure out how best to handle with my limited GPU compute :)
One (hopefully) final update to the Qwen3.5 model quants..
If you're enjoying the model, don't bother redownloading :)
But basically with inspiration from Aes Sedai and ddh0 and others, I just tweaked the recipe a bit to be much simpler and it seems more stable, will post KLDs
Thinking of another small switch up for my model naming
I want to make a list of "official" model releasers, Qwen, Deepseek, Arcee, Google etc, and when they release a model, I don't include the Author_ naming
Everyone else continues with the Author_ for clarity
Thoughts?
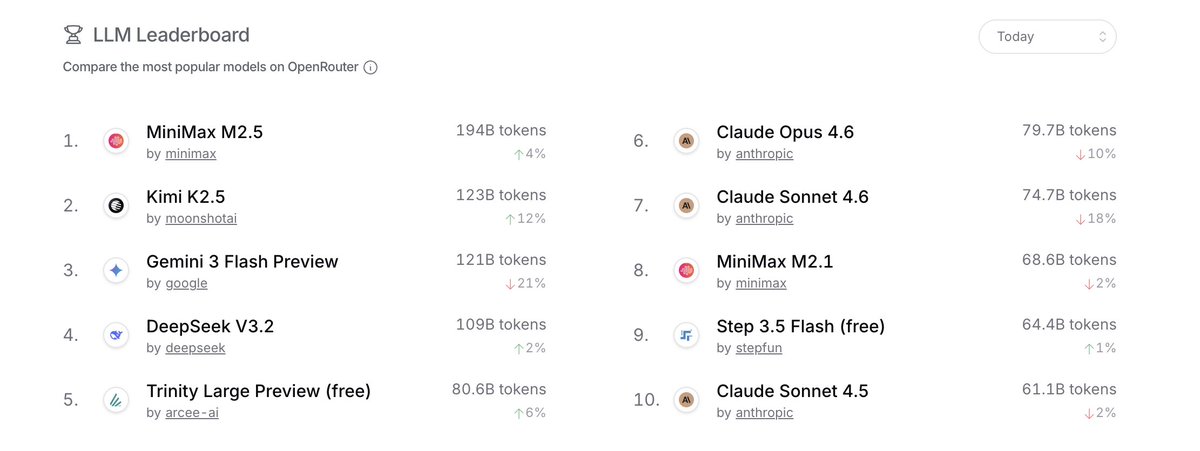
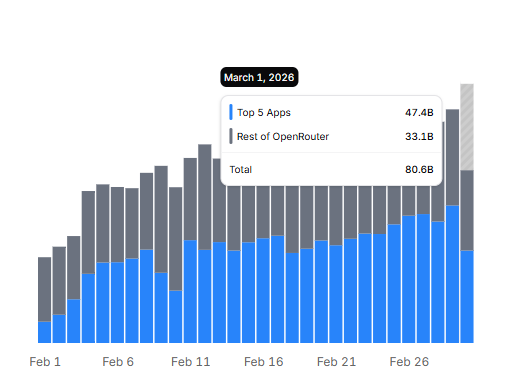
A banner weekend for Arcee as Trinity Large Preview officially entered the Top 5 overall models on @OpenRouter!
After surpassing 80B tokens on Sunday, we are already on pace to break that record again today. As our inference volume consistently tests the upper bound of our current limits, this growth signals a compounding market demand for our frontier-class open weights as we scale far beyond our initial 1T token milestone.
Stay tuned—more exciting news is on the horizon!
@bnjmn_marie out of curiosity, do you have the code you used available anywhere? Would love to run it against some of my own quants to see where I'm lacking
I'm sure I'm missing others who've helped me along the way (throw back to turboderp whose exllamaV2 was the reason I even started quantizing, the OG TheBloke, everyone at /r/localllama), but that just goes to show how great and supportive this community is ❤️
Never thought this day would come, but we've hit 10k followers on @huggingface :') 🤗
Huge thank you to them for their endless storage grants allowing me to upload over 2000 quants these past few years!
Just to name a few unsung heroes who help immensely behind the scenes; ubergarm, ilintar, madison (ddh0), compilade, ngxson, edaddario, yorkie, artus, jukofyork