Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
We love you guys!
Thanks so much for the overwhelming support, and for sharing this journey with us towards mass production!
Here's a quick look at how we iterated our prototypes, from hand-made to professionally CNC fabricated! Next step is injection molding!
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
for a sneak peek into what makes hermes agent cool and how it works inside of nemoclaw and openshell, join me, @karan4d & @llm_wizard on the @NVIDIAAI livestream @ 14:00 est today:
https://t.co/e77ePKiq0c
Factories are getting a new AI brain 🧠
Introducing NVIDIA Factory Operations Blueprint (FOX), a reference design for building factory manager agents that monitor operations, reason across real-time data, and coordinate specialized AI agents to help resolve issues at scale.
Early adopters including @HonHai_Foxconn, Pegatron, @Advantech_USA, and @WistronAiEDGE are already seeing gains in productivity, quality, and efficiency.
Read more: https://t.co/t66rl8utwQ
#NVIDIAGTC
SpaceX has almost finished writing V1.0 of an in-house AI training stack in C that exact-maps to 220k GB300s with 800G NICs, making heavy use of pipeline parallelism and getting as close to bare metal as possible.
The potential speed improvement vs JAX for large training runs is over an order of magnitude.
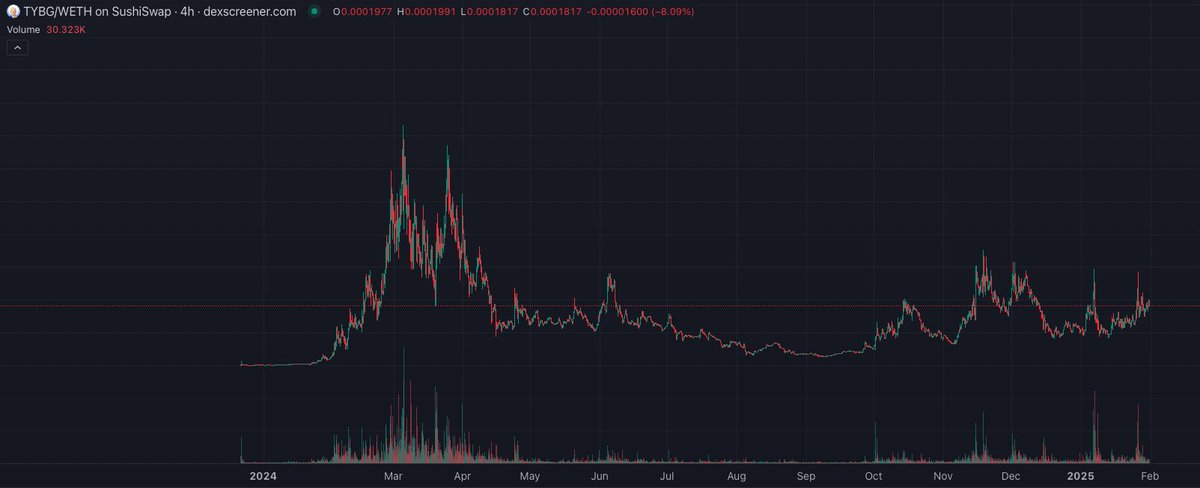
2026 year of base so far:
szn 0ish - $DRB run
szn 1 - $moltbook and openclaw meta insane runners
szn 2 mini - $gitlawb run
what's next in store for us?