Imagine setting up a #ChatEHR using #FHIR and #CDSHooks in just 15 minutes. Give it a try today, and while you’re there, explore the broader concept of #DHTI https://t.co/Jf95FAqgNh
Elated to share that the Weinstock lab just got its 1st R01!!
We are SO grateful to the hardworking NIH staff for tirelessly pushing to get those last NOAs out
Genomic Tokenizer: Toward a biology-driven tokenization in transformer models for DNA sequences
1. Genomic Tokenizer (GT) introduces a biologically grounded approach to DNA sequence tokenization, aligning with the central dogma of molecular biology by using codons—three-letter nucleotide sequences—as the core unit of tokenization.
2. Unlike traditional character or k-mer tokenizers, GT recognizes start and stop codons, assigns identical tokens to synonymous codons, and treats introns and out-of-frame regions as UNK tokens, reducing vocabulary size while preserving biological relevance.
3. GT is implemented within the HuggingFace tokenizer framework, enabling seamless integration into existing transformer-based DNA analysis pipelines and support for tasks like masked language modeling and sequence classification.
4. The tokenizer supports customizable start/stop codons and intron treatment, making it adaptable for different organisms, including prokaryotes and mitochondrial genomes.
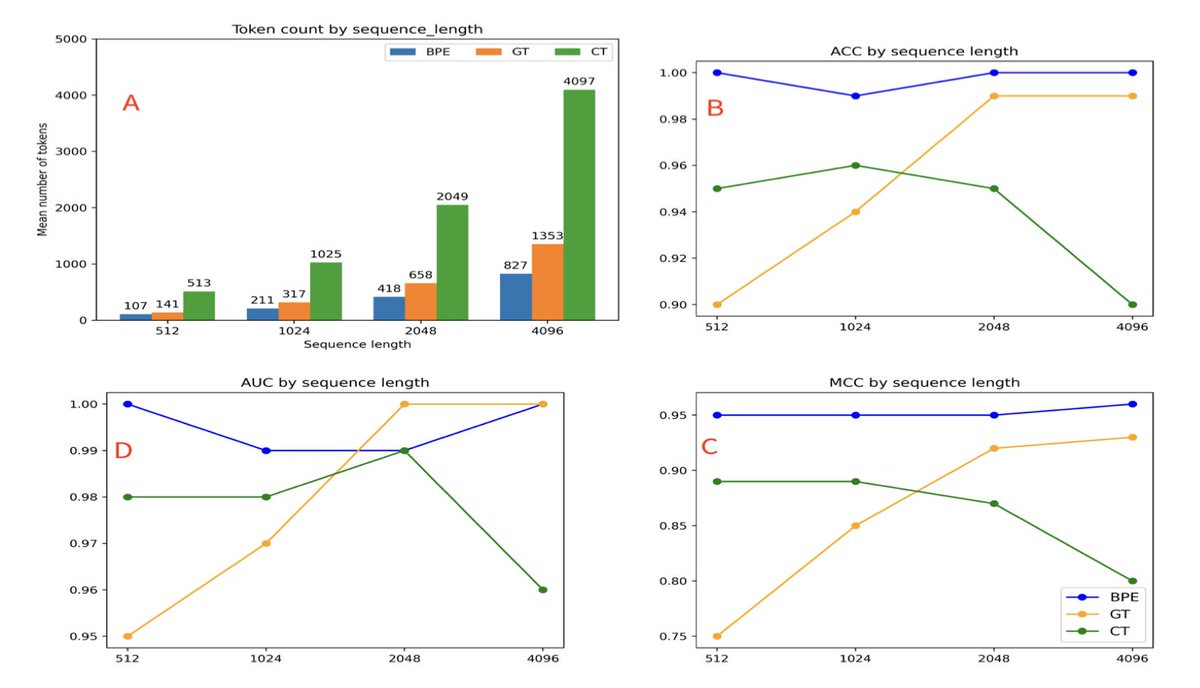
5. In classification experiments using a lung cancer-related variant dataset, GT showed greater robustness to long sequence lengths compared to character tokenization, and outperformed it in longer sequence tasks.
6. While byte-pair encoding (BPE) achieved the highest overall performance, its large vocabulary comes with high computational cost. GT balances biological insight with computational efficiency and a compact vocabulary.
7. GT tokenization avoids issues of redundancy and information leakage in masked language modeling that are common in overlapping k-mer tokenizers, leading to cleaner training signals and potentially better generalization.
8. The biological foundation of GT allows it to better model frame-shift mutations, synonymous substitutions, and stop-gain variations—key features in predicting phenotypic impact from genetic data.
9. Preliminary comparisons highlight GT’s strength in biological modeling and suggest potential advantages for foundational model training across genomics tasks when compared with purely data-driven tokenizers.
10. GT is open-source, installable via PyPI, and encourages broader exploration across genomic datasets and transformer architectures, including long-context models such as HyenaDNA.
💻Code: https://t.co/XNazAyGLlK
📜Paper: https://t.co/oQ5wmVe0Vg
#Genomics #Tokenization #Transformers #Bioinformatics #DNASequence #LLM #Codon #MaskedLanguageModel #DeepLearning #HuggingFace
Cornell Researchers Introduce Graph Mamba Networks (GMNs): A General Framework for a New Class of Graph Neural Networks Based on Selective State Space Models https://t.co/hFYfmxHEdt via @Marktechpost