In our pretraining, we mix egocentric human video with robot data, and Being-H0.7 is designed to support that joint pretraining setup. We do see some zero-shot ability already from the pretrained model. But if the goal is to push a downstream task as far as possible, we still do a very small second-stage finetuning on task-specific robot data. That said, human video is still the largest part of the whole training.
We believe human video is the most important path for robots to understand and interact with the physical world. Today we are introducing Being-H0.7, BeingBeyond’s third-generation flagship model. Being-H0.7 advances a new paradigm for world models built on latent-space reasoning, and scales pretraining to 200,000 hours of egocentric video. Check more about our work👇
Blog: https://t.co/2jXlYKWQUW
Paper: https://t.co/gWYA9nTR5d
Introducing BeingBeyond U1, the world’s first Real DexUMI.
U1 brings embodiment-agnostic dexterous hand data collection to real-world manipulation, taking a major step toward general-purpose dexterous manipulation models.
From data collection to transfer, deployment, and execution, U1 pushes UMI beyond the gripper era and into the age of dexterous hands.
Big month at BeingBeyond 🎉 We’re excited to share that in the past month we’ve had 8 papers accepted across top conferences and journals: CVPR’26 ×5, ICLR’26 ×1, ICRA’26 ×1, RAL ×1. Check our papers below👇
[CVPR'26] DemoFunGrasp: Universal Dexterous Functional Grasping via Demonstration-Editing Reinforcement Learning
https://t.co/DWtN5H8bnU
https://t.co/dSWcBq9Y2N
[CVPR'26] End-to-End Language-Action Model for Humanoid Whole Body Control
https://t.co/PixLZ3cn2p
[CVPR'26] Joint-Aligned Latent Action: Towards Scalable VLA Pretraining in the Wild
(To appear)
[CVPR'26] OpenT2M: No-frill Motion Generation with Open-source, Large-scale, High-quality Data
(To appear)
[CVPR'26] Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos
https://t.co/jjbQO30PZi
https://t.co/M0IrByuUvf
[ICLR'26] DemoGrasp: Universal Dexterous Grasping from a Single Demonstration
https://t.co/7WP3C6Z4eZ
https://t.co/fUJiXjWYOB
[ICRA'26] Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
https://t.co/qHfuoB63i5
[RAL] DemoHLM: From One Demonstration to Generalizable Humanoid Loco-Manipulation
https://t.co/ORrDeI8T3Z
https://t.co/v6wCTcmRYn
We’ll keep focusing on VLA models, Dexterous Manipulation, and Whole-Body Control. BeingBeyond looks forward to seeing everyone at the venues!🥳
Thx @_akhaliq for sharing our work!🚀🚀We’re actively continuing to open-source the Being-H series. Weights and training scripts are already out, and we’ll be gradually releasing the training data soon. Hope this brings more value to the VLA community!
@_akhaliq Thx @_akhaliq for sharing our work!🚀📷We’re actively continuing to open-source the Being-H series. Weights and training scripts are already out, and we’ll be gradually releasing the training data soon. Hope this brings more value to the VLA community!
8/8
For more details, please check out our blog and paper. We've also open-sourced the training code and model weights, and we’ll continue releasing the training data over time, stay tuned. 👇
Blog🏠: https://t.co/L5lTXuyVpm
Paper📑: https://t.co/32FpsIR3Lb
Github💻: https://t.co/lEUsSZfwxH
Hugging Face🤗: https://t.co/nsnFLdHOBs
(thread 1/8) We're releasing Being-H0.5🔥🔥🔥: a foundation VLA model aimed at one big goal — cross-embodiment generalization. Instead of training a new brain for every robot, we want a single model to carry skills across bodies (arms, humanoids, dexterous hands). Here's an overview of Being-H0.5 👇
7/8
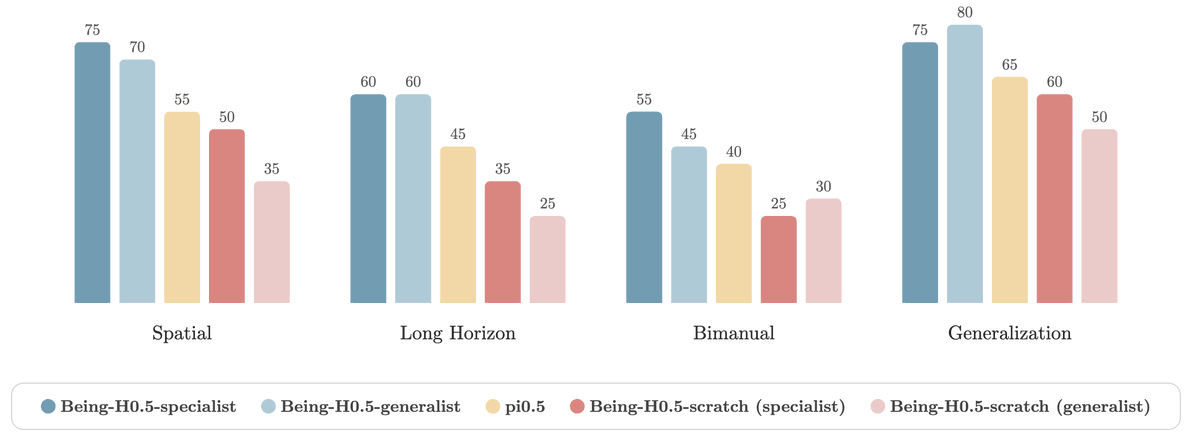
We deploy and evaluate across five very different real robots (upper-body humanoid, dexterous arm/hand, legged humanoid + hand, etc.). Across task suites (spatial / long-horizon / bimanual / generalization), Being-H0.5 performs strongly, with both specialist and single-checkpoint generalist variants. And we saw a surprising behavior we didn't want to oversell but couldn't ignore: embodiment-level zero-shot — the generalist checkpoint sometimes initiates qualitatively correct multi-step structure on previously unseen task–embodiment pairs in resembling environments.