Last week, @carlbaumann & I had the honour of chatting w/ @FintechTvGlobal about the challenges created by #distributedwork at the iconic @NYSE trading floor. Truly humbling experience & testament to all of @panagenda’s hard work, read more: https://t.co/NF80UXKwoq
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
BREAKING: MIT just analyzed 300 AI deployments worth $40 billion & the results are devastating.
Turns out, 95% of enterprise AI projects deliver zero measurable business impact.
Here's what the data revealed:
(hint: the pattern matches every major technology bubble we've seen)
Proof of life: still alive and kicking, and so happy for my past life in #lotusnotes helping me with 100+ lines of VB macros in a monster excel sheet today revamping our pricing strategy across 10+ criss-crossing product & services offerings.
Missing my designer client though 🥹
I’m wondering if other businesses also struggle with facebook auth for apps. The sudden privacy reviews come with an insane level of scrutiny, nitpicking, and zero support (https://t.co/eciQHOVDht only) Also starting to see apps removing fb auth - anyone else? #facebooksupport
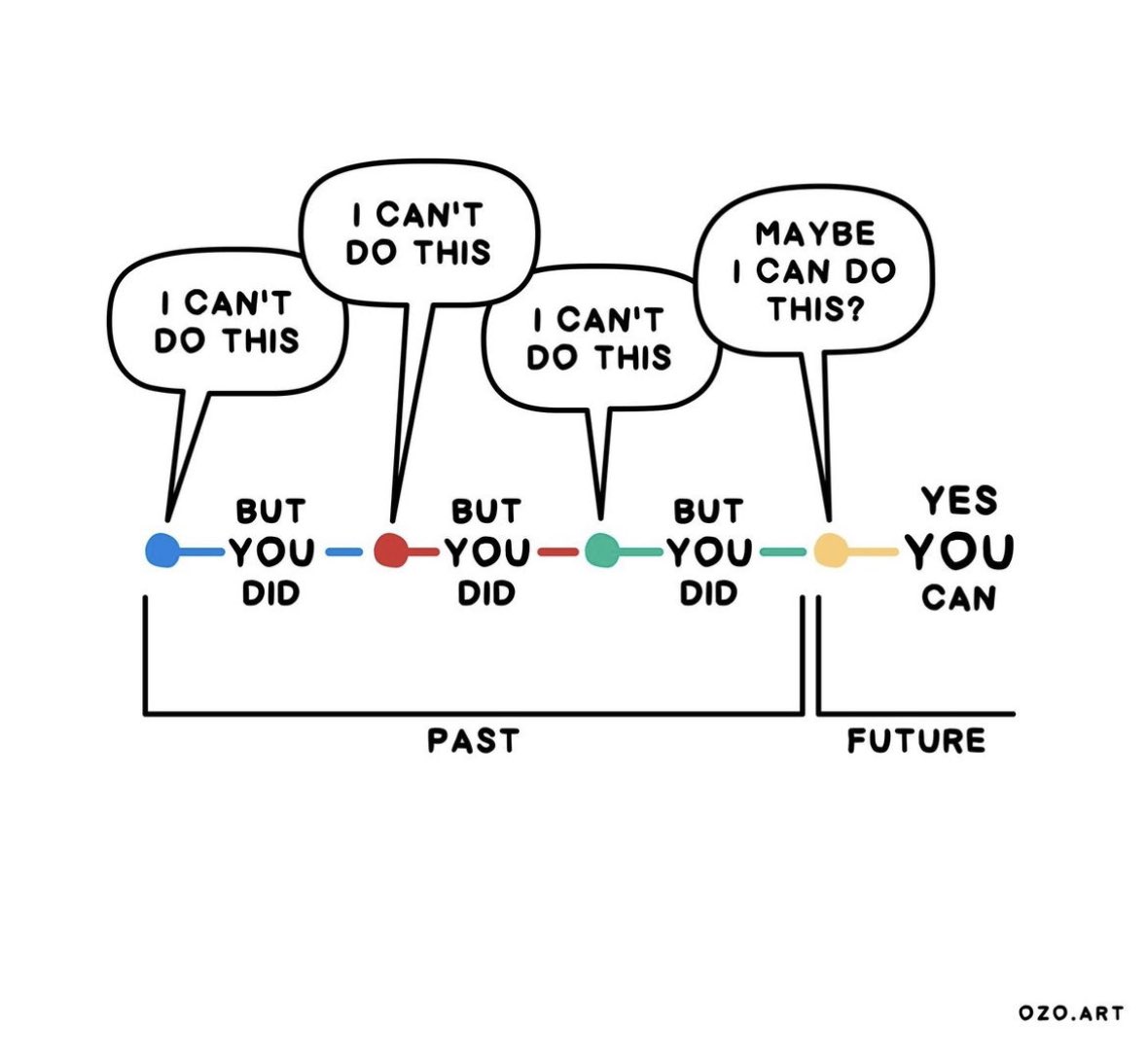
Confidence doesn't always come from believing in yourself today. It often stems from recalling the obstacles you overcame yesterday.
A history of resilience can silence self-doubt. Challenges conquered are clues to hidden strengths.
Past progress is proof of future potential.
Great attending #NRF2024 last week in NYC to learn about all the innovation in retail. While AI is obv. all the buzz, interesting to see trends around traffic analytics, BLE & RFID tags at stores, smart camera/sentiment analysis software all on quest to understand buyer behavior
I get that I procrastinate from time to time, but getting an overdue reminder for a #LotusNotes 8.5 client upgrade demonstration over 14 years, and 3+ employers later still cracks me up
Absolutely crazy how I ended up working, and doing a new corporate photoshoot at the very same office building (albeit on the roof this time 😎) I’ve worked at for 8 years starting 12+ years ago #NewProfilePic
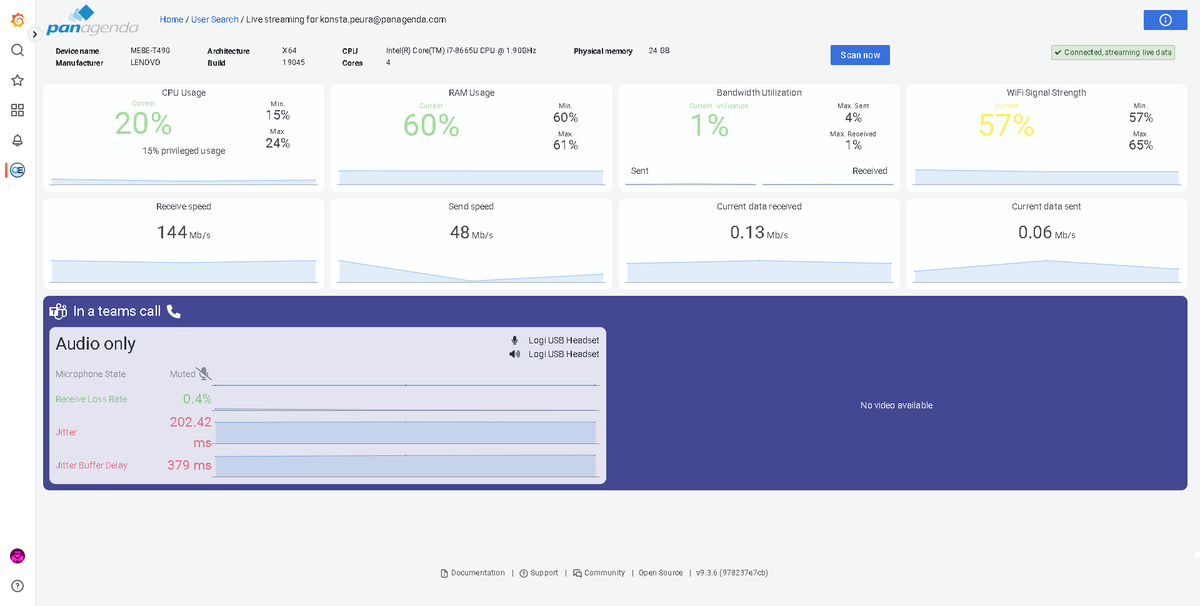
I just love pulling up real-time metrics when I'm struggling w/ audio in a #MicrosoftTeams meeting. Instead of blaming the speaker, I now see that this meeting room is no good. Time to move back to my seat/switch to my cell hotspot. @panagenda#TrueDEM to the rescue! #DEX#DEM
panagendians @BenMenesi and @carlbaumann were recently interviewed by @VinceMolinari of @FintechTvGlobal on the floor of the @NYSE.😎They got to discuss the post-pandemic challenges for IT operations and the need for improved digital experience monitoring. https://t.co/JWYKVz4eN8
Just one week to go! Come see a #MicrosoftMVP & MCM in a karaoke battle! Wait....maybe it's a technical battle royale? Luckily, #MicrosoftTeams has music mode, and @jaywynn is at the #mvpsummit. Obviously, he's singing every night. I'll bet his karaoke game will be tight 🤯!
.@Panagenda is supporting the #digital transformation for enterprise organizations around the globe with its software solutions.
@BenMenesi, VP of Products & Innovation, tells us about the benefits its #TrueDEM product provides for large enterprise companies. #NYSEFloorTalk
panagenda on the #NYSE floor today. Wow, just wow. If pictures say 1000 words, these pictures clearly say OfficeExpert TrueDEM delivers the best ROI for your #DEM and #EUEM needs on #Microsoft365 and #MicrosoftTeams. But...um, you guys forgot to bring me.