VP of Information Design @nomic_ai, building new ways to interpret and shape embedding models. Onetime history/digital humanities prof. @bschmidt.bsky.social
Read and explore this rich interactive of 20 *million* research articles from PubMed, a project we're releasing today with @ritagonmar and @hippopedoid. It's a *beautiful* embedding structure, a fascinating, complete corpus. Some highlights (thread) https://t.co/qzcZd2eKnB
AI systems excel in domains that have abundant coverage in internet data.
Large sectors of the economy are not digital-native. Their data, processes, and workflows are governed by signals that are out of distribution of foundation models.
Introducing the new Nomic Platform
In general I try not to post high-quality original content to this account anymore, and I feel pretty confident that the above post doesn't violate that practice.
Introducing Atlas Analyst: The Data Agent for Data Analytics
Ask questions, get answers with references to your data, and immediately take action based on those insights.
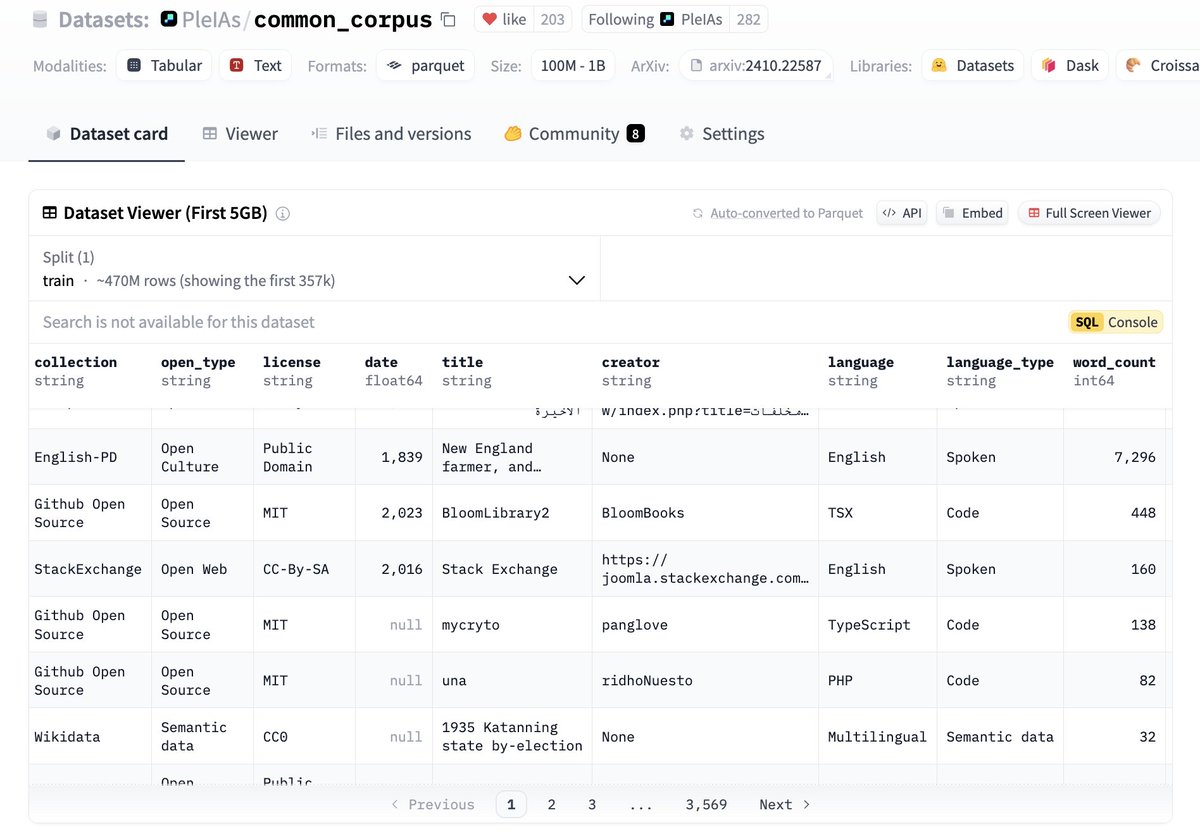
Announcing the release of Common Corpus 2. The largest fully open corpus for pretraining comes back better than ever: 2 trillion tokens with document-level licensing, provenance and language information. https://t.co/sdN6qNJMHW
Hugging Face is the hub for AI datasets and today we bring every dataset to life with Nomic's first-class Hugging Face data connector.
With a few clicks, you can now vector search, curate, and collaborate on any dataset in @huggingface
https://t.co/YT8zu4s7fb
Introducing Open-Source, On-Device Inference-Time Compute in GPT4All
- New : GPT4All Reasoner v1
- Support for Code Interpreter, Tool Calling and Code Sandboxing
Inference-time compute is now available to every laptop in the world.
Comparing ModernBERT and BERT embeddings reveals some nice properties.
The embeddings from the two base architectures show different features for this dataset in terms of class cohesion.
https://t.co/a7C06Ei50n
@Dorialexander which is kinda weird actually given that they did the Bodleian but not BNF -- do you have any sense what library those scans would be from?
@Dorialexander A bit more. Here's the French counts in the second half of the 17C (columns are `year, words, pages, books`) from https://t.co/IZIFVs4e3V
@Dorialexander My guess would be that they occasionally chat with Bob Darnton or something, but they're not interested in the DH people because they figure they have all the computer expertise so they just need to check that against book expertise.
@Dorialexander Still though after those changes what I'm seeing is that GB has high dozens to low hundreds of books annually in the english corpus for the 17C. EEBO is like 10x that, although maybe a lot of EEBO is Latin?
@Dorialexander I don't think they really care? Not sure. I'm kind of amazed on reflection that in the last 15 years I don't think I've never met a single person actually working on Google Books, even though they funded my postdoc.