Microsoft internal documents obtained by 404 Media reveal plans for Scout, its new always-on AI assistant.
The strategy explicitly starts with “Make people addicted” to build deep engagement before turning it into a full agentic platform. For customers, this raises real questions about workflow habits, productivity expectations, and future AI spending.
This engagement-first + metering model is quickly becoming the roadmap for every major AI vendor, especially frontier labs racing to offset massive compute costs. Microsoft is raising Microsoft 365 prices ~16% in July 2026 while bundling more Copilot features; Anthropic just separated agent usage from flat-rate plans with metered credits. Similar hybrid and usage-based shifts are rolling out at GitHub Copilot and beyond.
Yet recent assessments from NVIDIA and independent researchers add an important counterpoint: humans remain—and will likely stay—cheaper than AI for most tasks. NVIDIA’s Bryan Catanzaro noted compute costs already exceed employee costs for many teams, while an MIT study found AI economically viable in only 23% of vision-heavy roles.
Far from shrinking headcount, wider AI adoption is expected to increase demand for human oversight, prompt engineering, and edge-case handling.
#AI #Microsoft #FutureOfWork #TechStrategy
https://t.co/sm8fLqxMjX
Enjoy!
"SignalTrace is designed to help law enforcement identify people of interest by the signals emitted from their electronic devices they travel with, such as fitness trackers, smartwatches, RFID tags, and local signals from their mobile phones...
meta gave their AI support agent the ability to modify your instagram account. no identity verification. people figured this out and accounts are being taken over right now
We have detected a Red Hat GitHub credential and session cookie in infostealer logs on April 13 and May 15, 2026 - potentially linked to the Miasma supply chain attack. While we cannot confirm a direct connection, the timing is notably suspicious.
https://t.co/X4XnqibkPR
Pushing this narrative -at this time- points to an amazing level of ignorance. It is contributing to the acceleration of AI pushing post peak on the hype cycle.
I don’t know what happened between Microsoft and #NightmareEclipse behind closed doors
Maybe Nightmare Eclipse was unreasonable. Maybe Microsoft was. Maybe both.
But I think Microsoft badly misjudged this situation.
When you’re the largest software vendor on the planet, you don’t get to behave like an angry individual in an internet argument.
You have to be the adult in the room.
Deleting repositories, talking about criminal investigations and turning the whole thing into a public fight was a mistake. The damage from that goes far beyond this one researcher.
What surprised me most is how quickly people started sharing their own MSRC stories afterwards.
- Months without responses
- “Working as intended”
- Bounty disputes
- Reports that went nowhere
People don’t suddenly start telling those stories for no reason. I think Microsoft broke a lot of porcelain here.
And for what exactly?
I don’t see much upside.
Rough week for the "AI is taking our jobs" narrative.
> Amazon just axed its AI leaderboard as costs soared with no clear payoff
> Starbucks' AI can't even count coffee cups right
> Uber burning a $3.4B AI budget in just 4 months with nothing to show for it
WE ARE SO BACK.
The AI numbers are starting to look very ugly.
Even under "best case" assumptions, FT's own data shows Microsoft AI ROI at -9%, Google at -15%, Meta at -28%, Oracle at -35%. Only Amazon barely comes out positive.
This is exactly why I keep comparing this to the dot-com era. Incredible technology does not automatically mean sustainable economics. The internet survived. Most internet companies didn't.
Right now hyperscalers are spending trillions hoping future demand catches up to present capex. That's not certainty. That's a leveraged bet.
Sadly the amount of security advice like this increases: "How do I solve hard cyber problem X?" -- "Ah, use your magic wand!" -- "What? I don't have one!" -- "Well, sucks to be you!" #funny#PatchFaster
This is what we've been seeing with every company we work with.
Try justifying spending 100k on token spend when only 18k even makes it to a stable prod feature.
In the rush to maximize AI token spend, companies are wasting over 44% on bug fixes
Heads up if your CI pipelines are failing right now! 🚨 OSV seems to be experiencing a major wave of false positives over the last few hours, incorrectly flagging massive, highly-trusted packages as malicious.
A few of the biggest casualties so far:
• npm @tanstack/start-storage-context (1.167.4)
• PyPI fastapi (0.136.3)
• PyPI strawberry-graphql (0.315.6)
• npm @nx/key (5.0.7)
If your deployment is bricked, verify manually before panicking. Automation is a tool, not a judge.
With as much detail as I can share, from top down we are taking Mythos/AI acceleration of cyber threats seriously — by doubling-down on security fundamentals. Sandbagging attack paths using considerable levers of control we already have, w/ AI as our business justification.
🚨This could be the next big attack even though Microsoft just released an out-of-band patch
CVE-2026-45659: Deserialization of untrusted data in Microsoft Office SharePoint allows an authorized attacker to execute code over a network.
CVSS: 8.8
The vulnerability has been fixed in:
▪️SharePoint Server Subscription Edition, build number 16.0.19725.20280
▪️SharePoint Server 2019, build number 16.0.10417.20128
▪️SharePoint Enterprise Server 2016, build number 16.0.5552.1002.
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
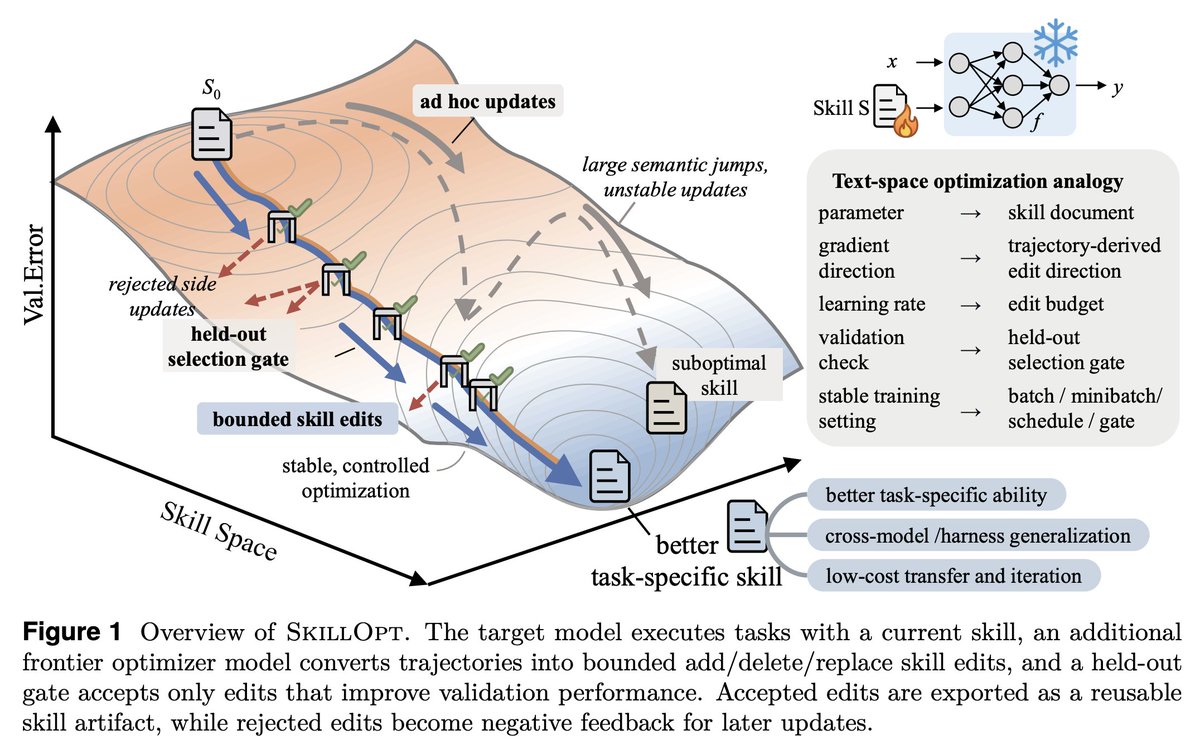
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
This is exactly what is happening. With many companies now in stage 3 and 4, AI is now post peak hype.
I’d expect that the fall will be as steep or steeper than the meteoric rise, especially as architectural (not technical !) debt is creating massive security backlogs.
I think AI coding hype follows roughly four stages:
1. Amazement
You try it and can’t believe how much code it generates from a few prompts.
2. Expansion
You start more and more projects because shipping suddenly feels cheap and fast.
This is also the phase where people start convincing everyone around them:
- coworkers
- management
- friends in other companies
because nobody wants to “fall behind” in 6–12 months.
That creates a massive snowball/FOMO effect.
3. The grind phase
You realize the generated code has architectural issues, sloppy mistakes, weird abstractions, duplicated logic, broken edge cases, etc.
So you start:
- re-prompting
- switching models
- increasing reasoning effort
- reviewing fixes
- generating fixes for previous fixes
And suddenly you spend your days reviewing AI-generated pull requests instead of building software.
4. Realization
You realize AI coding increases output much faster than it increases certainty.
The code still needs:
- review
- testing
- ownership
- architectural understanding
- long-term maintenance
Usually by expensive senior engineers.
And the interesting thing is:
this whole cycle can take many months or even more than a year because people become socially and professionally invested in the narrative themselves.
Once teams, managers, and entire companies have been convinced that this is the future, it becomes psychologically and politically very hard to later say:
“Actually, the ROI is much lower than we expected.”