🌉 FriendliAI is officially open in San Francisco.
We just opened a new 7,000 sq ft office at 20 Hawthorne Street in SoMa — right around the corner from SFMOMA and Moscone, inside the historic Crown Point Press building. 🏛️
Why expand now? Because inference is the bottleneck.
⚡ AI agents consume 5–30× more tokens per task than chatbots
🧠 Open-weight models (GLM-5.1, Kimi K2.6, DeepSeek V4, Nemotron 3) now rival closed frontier models
🎯 Custom fine-tunes align even more tightly with real enterprise use cases
Production-grade inference is where AI economics are won or lost — and that's exactly what FriendliAI’s Frontier AI Inference Cloud is built for. 🚀
The new space puts us closer to the customers, partners, and developers shaping what comes next. It's also purpose-built as a hub for the AI builder community — expect developer meetups, hackathons, executive briefings, and afterparties on the horizon. 🎉
🤝 We're hiring across go-to-market, partnerships, and engineering. Come build with us.
Read the blog https://t.co/tzFTEaFPXt
𝗚𝗲𝗺𝗺𝗮-𝟰-𝟯𝟭𝗕-𝗶𝘁 is live on 𝗙𝗿𝗶𝗲𝗻𝗱𝗹𝗶 𝗠𝗼𝗱𝗲𝗹 𝗔𝗣𝗜𝘀 and 𝗗𝗲𝗱𝗶𝗰𝗮𝘁𝗲𝗱 𝗘𝗻𝗱𝗽𝗼𝗶𝗻𝘁𝘀 with the best performance of any inference provider. ⚡
The largest open-weight model in @GoogleDeepMind's Gemma 4 family, 𝗚𝗲𝗺𝗺𝗮-𝟰-𝟯𝟭𝗕-𝗶 is a dense, instruction-tuned, and multimodal VLM. 👁️
FriendliAI's 𝗚𝗲𝗺𝗺𝗮-𝟰-𝟯𝟭𝗕-𝗶𝘁 Model API is #1 on @ArtificialAnlys for output speed, time-to-first-token, and end-to-end response times.
𝗚𝗲𝗺𝗺𝗮-𝟰-𝟯𝟭𝗕-𝗶𝘁 is equipped with configurable thinking and native function calling for coding, agentic workflows, document extraction, and question answering.
Benchmarks worth flexing:
🏆 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗰𝗼𝗱𝗶𝗻𝗴: 2,150 Codeforces ELO and 80.0% on LiveCodeBench v6
🧠 𝗠𝗮𝘁𝗵 & 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴: 89.2% AIME 2026, 84.3% GPQA Diamond
📄 𝗗𝗼𝗰𝘂𝗺𝗲𝗻𝘁 𝘂𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱𝗶𝗻𝗴: 76.9% MMMU Pro, 85.6% MATH-Vision
Run it serverless on 𝗠𝗼𝗱𝗲𝗹 𝗔𝗣𝗜𝘀, or deploy with 1 click on 𝗗𝗲𝗱𝗶𝗰𝗮𝘁𝗲𝗱 𝗘𝗻𝗱𝗽𝗼𝗶𝗻𝘁𝘀.
🔗 𝗧𝗿𝘆 𝗶𝘁: https://t.co/TiEItRu0cr
🔗 𝗟𝗲𝗮𝗿𝗻 𝗺𝗼𝗿𝗲: https://t.co/7T4lxdFRXb
Introducing GLM-5.1: The Next Level of Open Source
- Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo.
- Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations.
Blog: https://t.co/hmyDe4Nel3
Weights: https://t.co/CuUjXcPKJD
API: https://t.co/fz6reja4fb
Coding Plan: https://t.co/Nk8Y98HNhU
Coming to https://t.co/WCqWT0qCQb in the next few days.
Huge achievement by the GLM-5 team. Highly recommend reading the technical report.
Architecture isn’t the moat. Data quality and the training recipe are where the real differentiation happens.
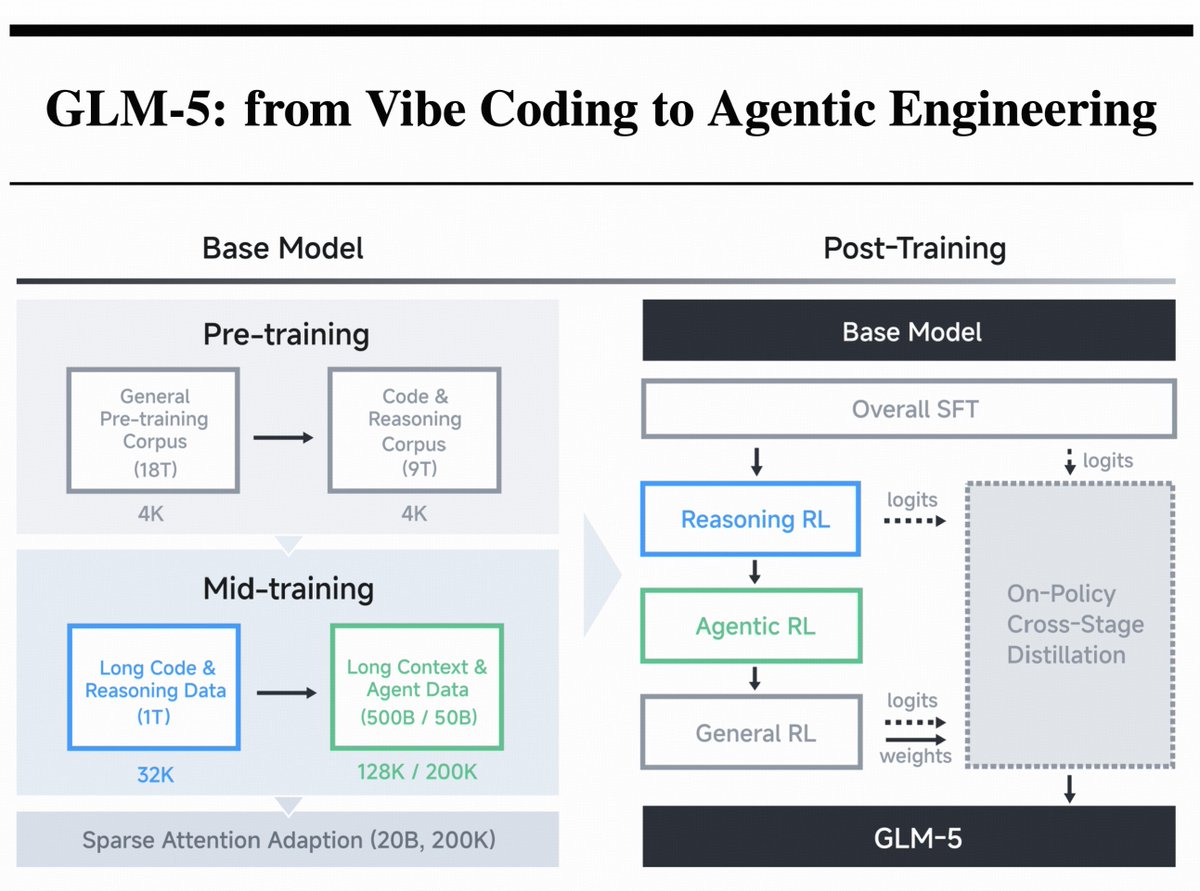
Presenting the GLM-5 Technical Report!
https://t.co/CGjxEISvFK
After the launch of GLM-5, we’re pulling back the curtain on how it was built. Key innovations include:
- DSA Adoption: Significantly reduces training and inference costs while preserving long-context fidelity
- Asynchronous RL Infrastructure: Drastically improves post-training efficiency by decoupling generation from training
- Agent RL Algorithms: Enables the model to learn from complex, long-horizon interactions more effectively
Through these innovations, GLM-5 achieves SOTA performance among open-source models, with particularly strong results in real-world software engineering tasks.
Scaling agentic AI starts with solving inference.
Mixture-of-Experts (MoE) is central to this shift, enabling more efficient, specialized LLMs. The latest 2025 MoE models aren’t just about bigger parameter counts, they focus on smarter routing, targeted compute, and practical deployment.
Key takeaways from the latest MoE landscape:
🔷 MoE routes queries to specialized “experts,” cutting compute and enabling larger models at lower cost.
🔷 The challenge is inference efficiency: routing overhead, expert sparsity, and load balancing. Not model size are the bottlenecks.
🔷 Benchmarks: well-tuned MoE can beat dense on throughput and cost, but only with routing/expert selection tuned for real workloads.
🔷 Open questions remain on reliability, reproducibility, and operational complexity. No single MoE is a silver bullet.
Link to the full blog in the comments!
Grateful to @_cspartners, @Sierra_Ventures, @alumniventures, KDB, KB Securities for backing the next phase of FriendliAI.
We’re focused on translating this support into customer value, faster deployments, lower costs, and production reliability.
#VentureCapital#AI#Inference #EnterpriseSoftware #ScalingAI
We are thrilled to announce our $20 million seed extension round. This milestone is a major step forward in our mission to make high-performance AI inference accessible, scalable, and cost-effective for teams around the world.
This funding comes at a pivotal time as AI rapidly shifts from experimentation to enterprise deployment. FriendliAI is leading this evolution with an inference platform that delivers up to 90% GPU cost savings without compromising performance.
This investment will help us accelerate:
✔️ Global expansion of our cost-effective AI inference platform.
✔️ Further development to help enterprises scale their AI solutions.
✔️ Our mission to make high-performance AI accessible to everyone.
With the enterprise adoption of AI exploding, we are proving that the next wave of innovation will be defined by both performance and efficiency.
#FriendliAI #SeedExtension #CapstonePartners #SierraVentures #AlumniVentures #KDB #KBSecurities #AI #Inference #LLM #MLOps #StartupFunding #EnterpriseAI
FriendliAI secures $20M in Seed-Extension Funding!
This round was led by Capstone Partners with participation from SIERRA Ventures, Alumni Ventures, Korea Development Bank, and KB Securities.
As AI inference adoption accelerates globally, this funding positions us to power startups and enterprises with high-performance, cost-efficient AI inference at scale.
Read the full article 🔗 https://t.co/DIZcdSUsXi
The @friendliai team has an incredible early preview for the Friendli Agent and really awesome $10k startup launch credits to share! https://t.co/Vshts22PDp
OpenAI gave us early access to GPT-5: our independent benchmarks verify a new high for AI intelligence. We have tested all four GPT-5 reasoning effort levels, revealing 23x differences in token usage and cost between the ‘high’ and ‘minimal’ options and substantial differences in intelligence
We have run our full suite of eight evaluations independently across all reasoning effort configurations of GPT-5 and are reporting benchmark results for intelligence, token usage, and end-to-end latency.
What @OpenAI released: OpenAI has released a single endpoint for GPT-5, but different reasoning efforts offer vastly different intelligence. GPT-5 with reasoning effort “High” reaches a new intelligence frontier, while “Minimal” is near GPT-4.1 level (but more token efficient).
Takeaways from our independent benchmarks:
⚙️ Reasoning effort configuration: GPT-5 offers four reasoning effort configurations: high, medium, low, and minimal. Reasoning effort options steer the model to “think” more or less hard for each query, driving large differences in intelligence, token usage, speed, and cost.
🧠 Intelligence achieved ranges from frontier to GPT-4.1 level: GPT-5 sets a new standard with a score of 68 on our Artificial Analysis Intelligence Index (MMLU-Pro, GPQA Diamond, Humanity’s Last Exam, LiveCodeBench, SciCode, AIME, IFBench & AA-LCR) at High reasoning effort. Medium (67) is close to o3, Low (64) sits between DeepSeek R1 and o3, and Minimal (44) is close to GPT-4.1. While High sets a new standard, the increase over o3 is not comparable to the jump from GPT-3 to GPT-4 or GPT-4o to o1.
💬 Token usage varies 23x between reasoning efforts: GPT-5 with High reasoning effort used more tokens than o3 (82M vs. 50M) to complete our Index, but still fewer than Gemini 2.5 Pro (98M) and DeepSeek R1 0528 (99M). However, Minimal reasoning effort used only 3.5M tokens which is substantially less than GPT-4.1, making GPT-5 Minimal significantly more token-efficient for similar intelligence.
📖 Long Context Reasoning: We released our own Long Context Reasoning (AA-LCR) benchmark earlier this week to test the reasoning capabilities of models across long sequence lengths (sets of documents ~100k tokens in total). GPT-5 stands out for its performance in AA-LCR, with GPT-5 in both High and Medium reasoning efforts topping the benchmark.
🤖 Agentic Capabilities: OpenAI also commented on improvements across capabilities increasingly important to how AI models are used, including agents (long horizon tool calling). We recently added IFBench to our Intelligence Index to cover instruction following and will be adding further evals to cover agentic tool calling to independently test these capabilities.
📡 Vibe checks: We’re testing the personality of the model through MicroEvals on our website which supports running the same prompt across models and comparing results. It’s free to use, we’ll provide an update with our perspective shortly but feel free to share your own!
See below for further analysis:
@friendliai 에서 사용자가 AI 모델을 블라인드로 비교하는 WBA (World Best AI, 와바) 플랫폼 https://t.co/h8z7hs772O 을 출시하였습니다! 벤치마크 기반의 평가는 알고 있는 문제를 잘 푸는 평가입니다. WBA는 사용자가 어떤 모델들이 잘하는지 직접 평가합니다! 최근에 선정된 K-AI 기업들(@LG_AI_Research, @upstageai, @SKtelecom, NAVER Corp)의 모델들과 글로벌 OpenAI, Google, Anthropic 등 빅테크 기업들의 모델들을 평가해 보세요.
#wba #friendliai #kai #와바
We're thrilled to share that the @LG_AI_Research-led consortium, with @friendliai playing a key role, has been selected as one of the five K-AI teams to lead the development of Korea’s own foundation model.
At @friendliai , we're committed to making frontier models truly accessible—fast, easy to use, and affordable—for everyone. Our cutting-edge AI inference technology lies at the heart of this mission, enabling scalable and efficient deployment of large models across real-world applications.
Congratulations to all five selected K-AI teams! We're especially excited that four of them—@LG_AI_Research, @upstageai, @SKtelecom, and NC AI—have been working with FriendliAI. We look forward to continued collaboration across the K-AI ecosystem.
#kai #friendliai #lgairesearch #upstage #skt #ncai #aiinference #inference
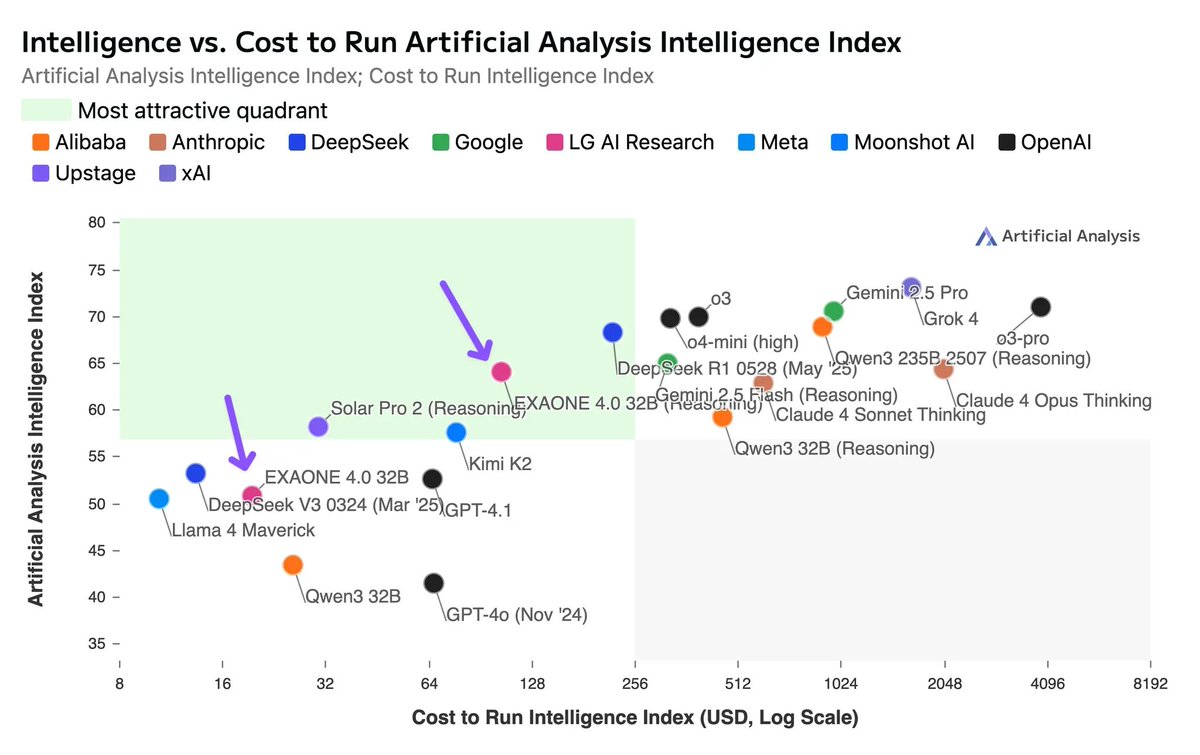
🇰🇷 LG recently launched EXAONE 4.0 32B - it scores 62 on Artificial Analysis Intelligence Index, the highest score for a 32B model yet
@LG_AI_Research's EXAONE 4.0 is released in two variants: the 32B hybrid reasoning model we’re reporting benchmarking results for here, and a smaller 1.2B model designed for on-device applications that we have not benchmarked yet.
Alongside Upstage's recent Solar Pro 2 release, it's exciting to see Korean AI labs join the US and China near the top of the intelligence charts.
Key results:
➤ 🧠 EXAONE 4.0 32B (Reasoning): In reasoning mode, EXAONE 4.0 scores 62 on the Artificial Analysis Intelligence Index. This matches Claude 4 Opus and the new Llama Nemotron Super 49B v1.5 from NVIDIA, and sits only 1 point behind Gemini 2.5 Flash
➤ ⚡ EXAONE 4.0 32B (Non-Reasoning): In non-reasoning mode, EXAONE 4.0 scores 51 on the Artificial Analysis Intelligence Index. It matches Llama 4 Maverick in intelligence despite having only ~1/4th total parameters (although has ~2x the active parameters)
➤ ⚙️ Output tokens and verbosity: In reasoning mode, EXAONE 4.0 used 100M output tokens for the Artificial Analysis Intelligence Index. This is higher than some other frontier models, but aligns with recent trends of reasoning models using more output tokens to 'think more' - similar to Llama Nemotron Super 49B v1.5, Grok 4, and Qwen3 235B 2507 Reasoning. In non-reasoning mode, EXAONE 4.0 used 15M tokens - high for a non-reasoner, but not as high as Kimi K2’s 30M.
Key details:
➤ Hybrid reasoning: The model offers optionality between 'reasoning' mode and 'non-reasoning' mode
➤ Availability: Hosted by @friendliai currently, and competitively priced (especially compared to proprietary options) by FriendliAI at $1 per 1M input and output tokens
➤ Open weights: EXAONE 4.0 is an open weights model available under the EXAONE AI Model License Agreement 1.2. The license limits commercial use.
➤ Multimodality: Text only input and output
➤ Context window: 131k tokens
➤ Parameters: 32B active and total parameters, available in 16bit and 8bit precision (means the model can be run on a single H100 chip in full precision)
EXAONE 4.0 uses more output tokens than Claude 4 Opus in Thinking mode. However, its lower per-token pricing on FriendliAI makes it much less expensive overall than Claude 4 Opus in Thinking mode
Today at the LG AI Talk Concert 2025, our CEO Byung-Gon Chun took the stage to celebrate our partnership with LG in providing the API for #EXAONE 4.0, LG AI Research’s latest foundation model, on FriendliAI.
With FriendliAI’s high-performance inference service, EXAONE 4.0 is now accessible to global users at scale.
We’re proud to partner with LG AI Research to bring this model to life and make it instantly available through our API.
🌐 Try it here: https://t.co/SHcQAQ2Dn2
👏 Huge congratulations to the LG AI Research team on this incredible milestone! We're just getting started!
Deploying generative AI models just got easier.
W&B Registry now integrates with @friendliai Dedicated Endpoints:
• Auto-deploy live endpoints on alias tagging
• Ensure idempotent rollouts
• Track every version + update with no service disruption
Big News: 370,000+ AI Models Now on FriendliAI!
We’ve just expanded our Models Page to feature over 370K AI models covering language, audio, image, and video.
Instantly deploy any of the 370K+ models from @huggingface with one click and experience FriendliAI’s industry-leading inference speed.
Explore our models page : https://t.co/D5xDl2dfRm
📖 Read more: https://t.co/rsymcDhRJV
#AI #MachineLearning #GenerativeAI #FriendliAI #ModelDeployment #HuggingFace #Milestone #Innovation
Did you know that Friendli TCache—the caching layer of the Friendli infrastructure—supports prefix caching not only for text, but also for images, videos, and more? That means faster and more cost-efficient inference for any multimodal AI application.
From healthcare chatbots to video analysis and e-commerce, Friendli TCache lets you reuse encoded data, reduce redundant computation, and deliver lightning-fast results.
Curious how it works and how it can supercharge your multimodal AI applications? Check out our latest blog post for a deep dive!
🔗 Learn more in our blog: https://t.co/Kh6klrYf9r
#Multimodal #AI #Friendli #FriendliAI #Caching
🔥 Thrilled to announce the Agentic AI Summit 2025—the first summit dedicated to #AgenticAI in the Bay Area, hosted by @BerkeleyRDI@UCBerkeley! 🚀
Building on momentum from our LLM Agents MOOC (23k+ global learners!), we're creating the LARGEST gathering of its kind—1,500+ in-person attendees!—uniting top minds across academia, industry, VC, and policy to explore the frontiers of #AgenticAI.
📅 August 2, 2025
📍 UC Berkeley Campus
✨ Call for Talk Proposals / Papers: Submit your talk proposal on Agentic AI by 5/31!
🚀 Startup Spotlights: Showcase your innovative Agentic AI startup at the Summit—apply by 5/31!
🏆 Don't miss AgentX—the perfect launchpad for your early-stage Agentic AI startup or research project! Selected teams will showcase their breakthrough work live at our exclusive AgentX Demo Day during the Summit. Gain visibility among top VCs (@Accel@BainCapVC@BessemerVP@lightspeedvp@MayfieldFund@NEA) & industry leaders, and access/win valuable resources/prizes, sponsored by @Amazon@huggingface@LambdaAPI@MistralAI@Google@GroqInc@schmidtsciences, and more to be announced.
🎟️ Attendee Registration opens soon. Join the RDI mailing list to stay tuned! Space is limited—secure your spot early.
Join us in Berkeley or via livestream on 8/2 to shape the future of #AI #AgenticAI together! 🌟