Excited to share our paper "How Long Reasoning Chains Influence LLMs’ Judgment of Answer Factuality" \w @bikeping got accepted to ACL 2026, with an Oral recommendation from the Senior Area Chair!
Paper: https://t.co/fKVsYHCHWs
Code: https://t.co/CefoA8tOE9
🎉 Here's what we did 🧵
💡Motivation
LLM-as-a-Judge often fails because judges don't know the correct answer — and have no extra information to reference.
Can the reasoning trace serves as additional evidence that help the judges to judge more accurately?
📖Concrete example:
Q: Who was the first Nobel Physics laureate?
A: Einstein
The judge doesn't know if that's right. But the reasoning says "Einstein won his first Nobel in 1921" — while the first prize was awarded in 1901. Caught! 🙅
Sounds great… but is it really that simple?
🔦 What we did?
TL;DR: Reasoning traces are a double-edged sword. LLM judges still can't consistently distinguish "actually correct" from "sounds correct."
We studied this across 4 datasets × 10+ judge models (GPT-4o, Claude Sonnet 4.5, DeepSeek-v3.1…). Two key findings:
❌ Weak judges are almost completely fooled. In NQ, only 23.2% of answers are correct — but weak models accept up to 88% when reasoning looks fluent. They judge style, not substance.
✅ Strong judges are smarter, but not perfect. DeepSeek-v3.1's alignment improves from 63.4% → 76.2% on NQ. But even strong judges get misled by high-quality reasoning chains. Just like humans: non-experts get sweet-talked, experts push back 😄
Controlled experiments on reasoning chain features:
1. Fluency is the first gate: break the reasoning flow, and most models mark it “incorrect,” even if it’s right.
2. Factuality is important: counterfactuals reduce pass rates, but adding more errors doesn’t increase sensitivity—the evaluator isn’t counting them.
3. Position matters: errors at the start hurt most; errors at the end matter less.
SIGIR-AP2025 has successfully concluded! Hope that everyone has a safe trip back :) Here is a summary of the event:
https://t.co/18WcmhOQRd Looking forward to seeing you next year!
🌏 Visa Invitation for SIGIR-AP 2025
If you need a Chinese visa to attend SIGIR-AP, please send your full name, gender, date of birth, passport number, and institution to [email protected]. We’ll issue your official invitation letter as soon as possible.
#SIGIRAP2025
China has recently introduced a trial policy allowing Russian citizens to enter visa-free for up to 30 days, from Sep. 15, 2025, to Sep. 14, 2026. We warmly welcome Russian researchers and students to join us at SIGIR-AP in Xi'an! Check this out: https://t.co/xF2atAjRwx.
Join us at SIGIR-AP for two exciting workshops: R3AG 2025: The Second Workshop on Refined and Reliable Retrieval-Augmented Generation, and BREV-RAG: Beyond Relevance-based EValuation of RAG systems. Submit your work by September 30! Learn more at https://t.co/lR5yeAIaDM.
Our paper "Towards Fully Exploiting LLM Internal States to Enhance Knowledge Boundary Perception" will be presented on July 30th from 11:00 to 12:30 at Hall 5X, #195. Welcome to drop by and have a discussion!
#ACL2025NLP
🥳Happy to share that our paper "Towards Fully Exploiting LLM Internal States to Enhance Knowledge Boundary Perception" has been accepted by #ACL2025! We explore leveraging LLMs' internal states to improve their knowledge boundary perception from efficiency and risk perspectives.
If you have concerns about obtaining a VISA to China to attend #SIGIRAP2025, please note that there are now multiple visa-free routes for many countries, and the standard F/L visa process remains straightforward. Please check the VISA information: https://t.co/xF2atAkpm5
We launched a webpage about visiting Xi'an: https://t.co/1pECYIz17u. Xi'an is one of China's Four Great Ancient Capitals with a rich history spanning over 3,000 years. It has been the capital of 13 dynasties. Welcome your submissions, and looking forward to seeing you in Xi'an!
😎Our paper “Evaluating Implicit Bias in Large Language Models by Attacking From a Psychometric Perspective” is accepted to #acl2025 w/@bikeping etc. We propose a psychometric-inspired framework to induce and evaluate implicit bias in LLMs. Project webpage:https://t.co/q2fqVB7gBG
The official website for SIGIR-AP 2025 is now live! Please visit: https://t.co/GBG1brbBLL.
This year, we are also inviting industry papers. We also encourage authors of unsuccessful SIGIR submissions to consider submitting to SIGIR-AP. We look forward to seeing you in Xi'an!
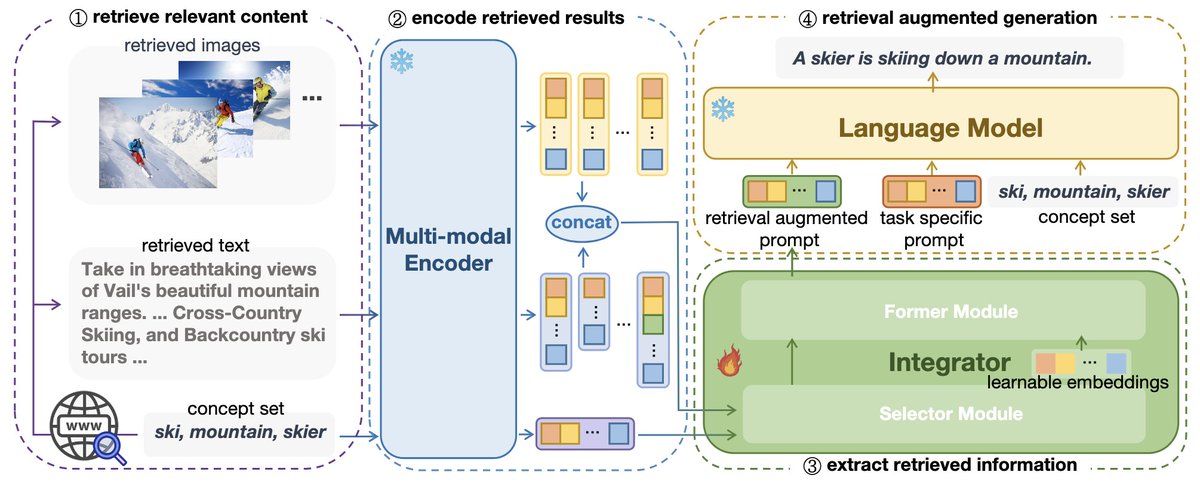
Our paper "MORE: Multi-mOdal REtrieval Augmented Generative Commonsense Reasoning", got accepted by #acl2024 w/ @bikeping , etc. We propose a novel retrieval augmentation framework to leverage both text and images to enhance the commonsense ability of language models.
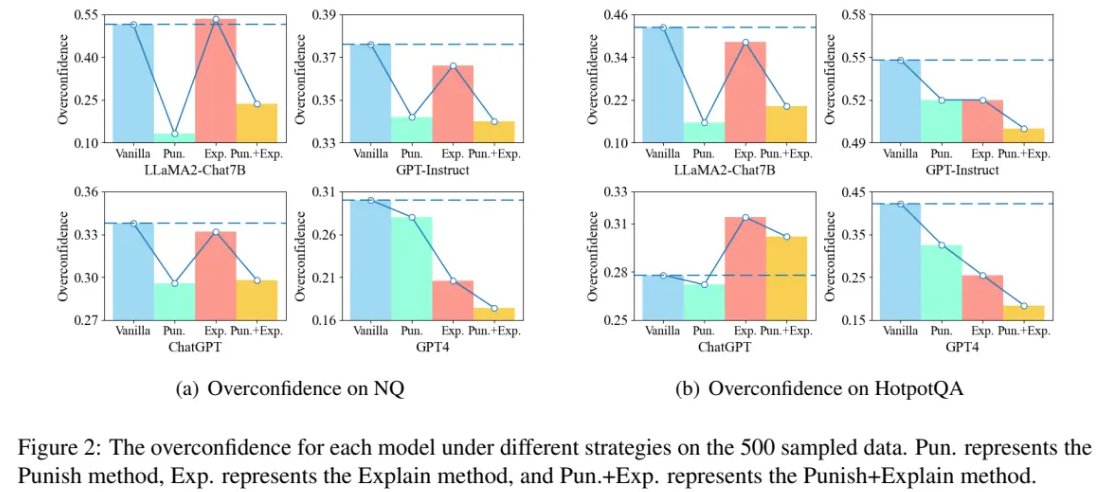
Our paper, "When Do LLMs Need Retrieval Augmentation? Mitigating LLMs' Overconfidence Helps Retrieval Augmentation", got accepted by #acl2024 w/@bikeping, etc. We explore effective and efficient adaptive RAG by enhancing LLMs' perception of their knowledge boundaries.