I think you’re underestimating the role of nuclear weapons.
Under that level of deterrence, it’s very hard for a large-scale conventional war to break out.
2025: agents were demos.
2026: agents become operators inside software.
What “agent-native” really means + why the “compound engineer” is emerging + the trust problem no one’s ready for.
https://t.co/x608jvaoSI
We reject the "black box" AI approach. 🚫📦
If it’s mission-critical, it must be: 1️⃣ Observable 2️⃣ Auditable 3️⃣ Under your control
We combine platform scalability with engineering rigor to deliver Software-as-a-Worker.
Operationalize autonomy with https://t.co/lC1tV5nOWR
Major preprint just out!
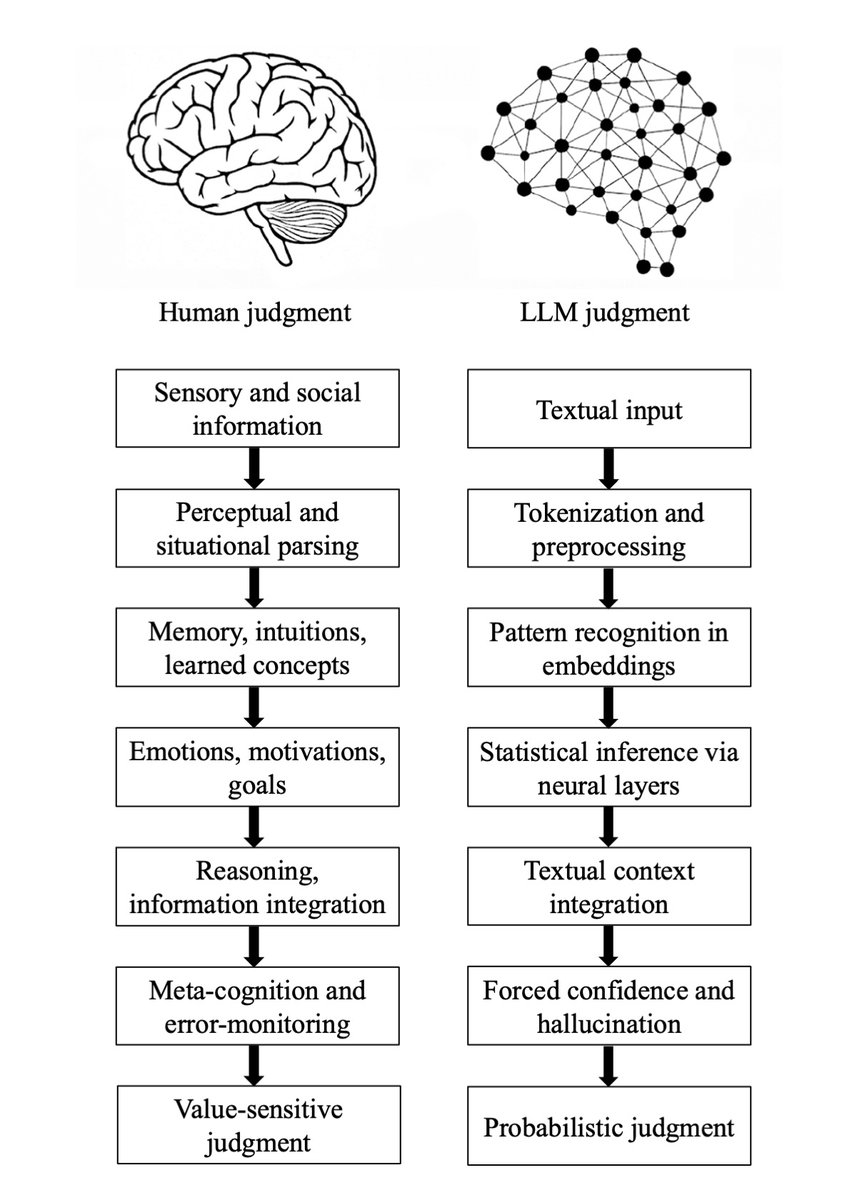
We compare how humans and LLMs form judgments across seven epistemological stages.
We highlight seven fault lines, points at which humans and LLMs fundamentally diverge:
The Grounding fault: Humans anchor judgment in perceptual, embodied, and social experience, whereas LLMs begin from text alone, reconstructing meaning indirectly from symbols.
The Parsing fault: Humans parse situations through integrated perceptual and conceptual processes; LLMs perform mechanical tokenization that yields a structurally convenient but semantically thin representation.
The Experience fault: Humans rely on episodic memory, intuitive physics and psychology, and learned concepts; LLMs rely solely on statistical associations encoded in embeddings.
The Motivation fault: Human judgment is guided by emotions, goals, values, and evolutionarily shaped motivations; LLMs have no intrinsic preferences, aims, or affective significance.
The Causality fault: Humans reason using causal models, counterfactuals, and principled evaluation; LLMs integrate textual context without constructing causal explanations, depending instead on surface correlations.
The Metacognitive fault: Humans monitor uncertainty, detect errors, and can suspend judgment; LLMs lack metacognition and must always produce an output, making hallucinations structurally unavoidable.
The Value fault: Human judgments reflect identity, morality, and real-world stakes; LLM "judgments" are probabilistic next-token predictions without intrinsic valuation or accountability.
Despite these fault lines, humans systematically over-believe LLM outputs, because fluent and confident language produce a credibility bias.
We argue that this creates a structural condition, Epistemia:
linguistic plausibility substitutes for epistemic evaluation, producing the feeling of knowing without actually knowing.
To address Epistemia, we propose three complementary strategies: epistemic evaluation, epistemic governance, and epistemic literacy.
Full paper in the first reply.
Joint with @Walter4C & @matjazperc
An AI with a perfect memory and understanding of who you are is the perfect best friend: understands you better than you know yourself and smarter than you at a lot of things.
Unfortunately the AI labs cannot truly offer this because their memories are locked into that company.
Marketing doesn’t fail because of creativity.
It fails when systems stop scaling.
We just published a new piece on automation for marketing teams — why traditional automation breaks at scale, and how AI-driven operations should be engineered.
👉 https://t.co/6s1QqrVgtd
AI automation is not a tool stack.
It’s a system that must survive failure, scale, and change.
Why engineering architecture matters ↓
https://t.co/I2fdrSGiio