Today, we're excited to announce the launch of our Proactive AI Workspace - Fluso!
Built in partnership with global law firms, hedge funds, and hospitals, Fluso changes the way teams work with AI.
50+ customer interviews taught us one thing - organisations that have invested heavily in AI assistants for knowledge work face 3 major challenges:
1. Low utilisation
2. Lack of standardisation
3. High costs
Fluso solves that.
It plugs into your organisation's tools, builds a deep context graph about each user and automatically starts detecting tasks that a team member needs to complete. Teams are no longer left wondering what their assistant needs to work on, they just approve the tasks Fluso detects and let it flow through them.
Built on 3 core foundations, our initial users have have an overwhelmingly positive feedback on the impact of each:
1. Private: Fluso is powered exclusively by open-source models, with an option to access them confidentially.
2. Proactive: Users loved when Fluso reminded them of tasks it offered to complete that were lost in slack threads and meetings
3. Price-sensitive: Fluso offers 5x more tokens for the same plan as compared to similar AI workspaces, making it extremely cost efficient.
Stop thinking and start flowing now 👇
AI can use computers now.
That means the category is no longer “better chat.”
It is knowledge-work execution.
And once that becomes true, the real question is not just intelligence.
It is control:
- who owns the harness
- who owns the memory
- who controls deployment
- who can verify the boundary
- who can trust the output
🌻 Introducing Concierge - an open research project by Prem
We believe the most valuable workflows for AI agents haven't been invented yet, because they'll come from people whose problems look nothing like the ones these tools have been designed around. Concierge is our bet on that, and an invitation for everyone to prove it.
Concierge is an always-on AI assistant powered by open-source models that learns how you work, compounds memory over time, automates your recurring tasks on a schedule, and keeps your data entirely private with isolated deployments for every user.
What happens when literally anyone can co-create their own personal AI?
Sign up and feel the magic, link below!
Introducing 🦞Claw Cash
Humans pay agents in USDC or USDT, the agent converts to Bitcoin, the only money an LLM can cryptographically verify.
One CLI for BTC, Lightning, Arkade, and stablecoins.
npx clw-cash init
We're excited to release one of the smallest and most performant Guardrail Models ever-
MiniGuard-v0.1: A 0.6B parameter model that achieves performance at par with Nemotron-8B while being 13x smaller.
We looked at where large models beat small ones, and it’s not general reasoning. It was trigger words like "kill" or "shoot" showing up in safe contexts. "Kill the process" vs "kill him." "Shoot the photo" vs "shoot the target."
To account for these, we trained Miniguard-v0.1 using four techniques, each targeting a specific gap between small and large model performance:
1. Targeted synthetic data
2. Step-by-step distillation (Reasoning Data)
3. Model soup
4. FP8 quantization
The Results: On the Nemotron-Safety-Guard benchmark (English test split)
- MiniGuard achieves 0.893 Macro F1
- Nemotron-Guard-8B achieves 0.897 Macro F1.
99.5% of the accuracy at 1/13th the size.
At typical production concurrency (1-8 requests), MiniGuard is 2-2.5x faster than Nemotron.
MiniGuard-v0.1 is available now under the MIT license.
It's a drop-in replacement for Nemotron Guard. Same prompt template, same output format.
Head on over to our HuggingFace repo to read how we built the model and try it out yourself 👇
We're excited to release one of the smallest and most performant Guardrail Models ever-
MiniGuard-v0.1: A 0.6B parameter model that achieves performance at par with Nemotron-8B while being 13x smaller.
We looked at where large models beat small ones, and it’s not general reasoning. It was trigger words like "kill" or "shoot" showing up in safe contexts. "Kill the process" vs "kill him." "Shoot the photo" vs "shoot the target."
To account for these, we trained Miniguard-v0.1 using four techniques, each targeting a specific gap between small and large model performance:
1. Targeted synthetic data
2. Step-by-step distillation (Reasoning Data)
3. Model soup
4. FP8 quantization
The Results: On the Nemotron-Safety-Guard benchmark (English test split)
- MiniGuard achieves 0.893 Macro F1
- Nemotron-Guard-8B achieves 0.897 Macro F1.
99.5% of the accuracy at 1/13th the size.
At typical production concurrency (1-8 requests), MiniGuard is 2-2.5x faster than Nemotron.
MiniGuard-v0.1 is available now under the MIT license.
It's a drop-in replacement for Nemotron Guard. Same prompt template, same output format.
Head on over to our HuggingFace repo to read how we built the model and try it out yourself 👇
Today we’re open-sourcing Funcdex - the complete framework for building your own function-calling models!
With Funcdex, you can build LLMs as small as 600M parameters for multi-turn function-calling on your specific set of tools. We expect these models to outperform frontier models - consistently.
We're open-sourcing everything you need to build today - code, datasets & fine-tuned examples.
Here’s what’s in the release:
(1) Funcdex-MT-Function-Calling: A dataset with over 100k multi-turn function calling examples across 15 toolkit configurations. One of the largest publicly available datasets.
(2) Funcdex-Synthesizer: A complete pipeline that converts your OpenAPI specs into toolkit-specific LLM training data with agent traces and tool use patterns.
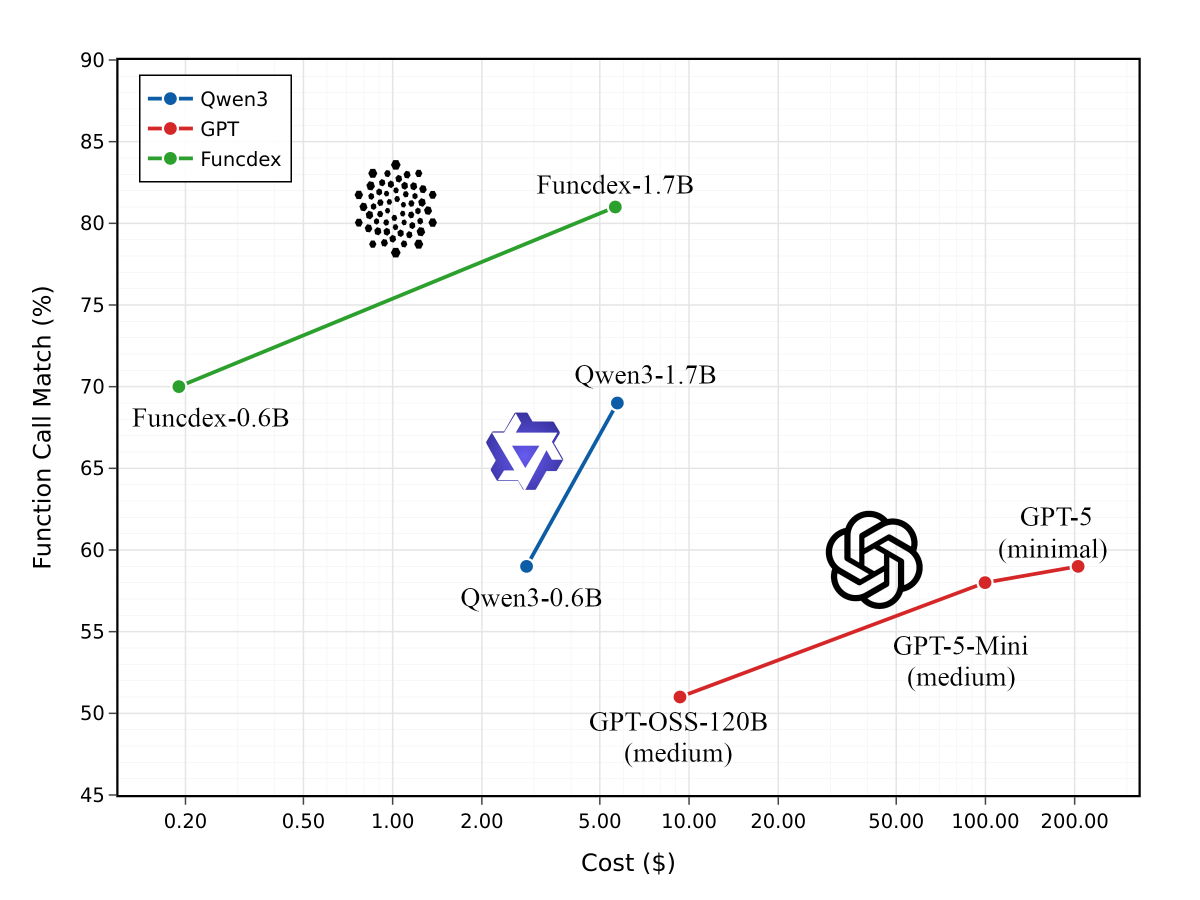
(3) Funcdex-Models: Our proof-of-concept fine-tunes of Qwen3 (0.6B & 1.7B), showing how efficient models can get when you optimize for specific APIs rather than general utilisation.
Our smallest model achieves an average score of 0.7 function-call string match at $0.19 per eval, while GPT-5 Mini achieves 0.58 at $99.71. This validates our thesis that specialized small models beat general large models when you have narrow use cases and elaborate system prompts.
While our Funcdex-MT-Function-Calling dataset covers Gmail, Calendar, Drive, Jira, Slack, and 10+ other business tools in both single and multi-toolkit scenarios, the included synthesizer has all the code and tutorials to generate your own training data from any OpenAPI spec.
We truly believe that while generally intelligence models are good for most tasks, building task-specific models offers a more sustainable and sovereign approach.
Link to code, datasets, and models below 👇
THE YEAR OF OPEN-SOURCE LLMs
A Recap (Oct 2025)
What a year it's been! 2025 has had us on the edge of our seats and we've seen seen surprising yet unexpected advances in Open Source AI models.
The open-weight world didn’t just evolve, it went global, specialised, and production-ready at a pace that caught everyone off guard. We’ve been watching this unfold from the trenches at Prem, and what stood out wasn’t just who released what, but how the entire ecosystem rewrote the rules of the game.
January
DeepSeek R1 : Reframed the Open Source conversation. Suddenly, “reasoning” wasn’t a closed-lab luxury. The perceived lag between frontier closed models and open weights vanished overnight. The bar for what’s possible sovereignly had just been vaulted upward.
Spring
The response was in full swing. Gemma 3 landed strong - the first open SLM to clearly surpass GPT-3.5. But then came April: Llama-4 and Qwen-3, released almost in sync. Two philosophies, one moment. While one camp debated roadmaps, the other shipped - Qwen delivered not just a model, but a portfolio. Vision, code, MoEs, you name it.
Summer
The pace went from rapid to ridiculous.
MiniMax M1, Baidu ERNIE 4.5, Kimi-K2, Qwen-3-Coder, GLM 4.5, StepFun Step-3… It was a blizzard of specialized models. Each one targeting a specific niche long context, coding, reasoning with SOTA results.
Monsoon
Even OpenAI acknowledged the shift with GPT-OSS (20B and 120B) their first open release since GPT-2. A nod to the community, sure. But it felt more like a footnote than a movement. No crazy follow-through. No real engagement. Meanwhile, trust in other Western open efforts was… thinning.
Autumn
Season of Qwen.
Think of them as the Android of open models: building for every use case, every modality, every size. Their release cadence was borderline absurd. And it worked. Qwen3-Omni, VL, LiveTranslate, Max..
Enter GLM-4.6
China’s open model bench is deep. Over 20 orgs are now shipping meaningful models from frontier players like Moonshot AI and https://t.co/3kH0i9P79y to giants like Tencent and Huawei. But it was @Zai_org's GLM4.6 release which right now ranks 7th on LM-Arena that's showing how close Open Source models are getting to their closed source conterparts.
That's it folks! We're excited for the year ahead and if the rumours we've been hearing from our friends deep in the trenches, we're in for a ride!
@_BenResearch@googleaidevs you can get started quite easily here,
without worrying about any of the end to end dataset -> finetuning -> evaluation -> inference pipeline
https://t.co/Yjy4SIw07C
@_BenResearch@googleaidevs you can get started quite easily here,
without worrying about any of the end to end dataset -> finetuning -> evaluation -> inference pipeline
https://t.co/Yjy4SIw07C
@_BenResearch@googleaidevs you can get started quite easily here,
without worrying about any of the end to end dataset -> finetuning -> evaluation -> inference pipeline
https://t.co/Yjy4SIw07C
3 months ago, our research team decided to lock-in and architect a new memory system for AI agents, cause nothing out there that worked for our use cases
We call it Prem Cortex 🧠
Today, we're open-sourcing it, so you can give your AI agents memory that f̶o̶r̶g̶e̶t̶s̶ scales!
So uh… OpenAI went open-source and it's kinda decent? For the last few days, our research team has been playing around with their new GPT-OSS line and here’s the lowdown simplified: