🚀 Gemma 4 12B is here!
We partnered with @GoogleDeepMind to bring and optimize their new dense and unifed multimodal model for Apple Silicon.
◈ 12B dense · 256K context
◈ Thinking mode (built-in reasoning)
◈ Vision: dynamic res, OCR, UI + charts
◈ Native audio: ASR + speech translation
◈ Function calling for agents
◈ Text + image + audio, interleaved
Runs local. Get started now ⚡
> uv pip install -U mlx-vlm
https://t.co/7BvnEuzKvj
LTX-2.3 OmniCine V1 LoRA
- Anatomy fix
- Director controls:
- Better lip-sync and facial nuance + it finally stops burnt-in subtitles from ruining the video.
- Objects and characters don't warp when things get fast or chaotic.
- Handles 2D Anime, 3D CGI, photorealism.
https://t.co/i2eNhXLck8
Hi. Over the last 24 hours we had three separate small incidents that affected Codex reliability. Those are three too many and we are taking active steps for them to not reproduce.
I have reset usage limits for Codex across all paid plans. May the tokens flow again.
My Claude Code sub expires tomorrow. I barely use it, but I still had it installed on my Windows PC so I used it to debug some crashing earlier.
They hard cut me off over 24 hours early.
Cosine dissimilarity between unit vectors interpreted as *curved Bregman divergence*, a BD restricted to unit sphere S (non-convex domain).
https://t.co/PWSK8cbi7q
jesus, qwen3-tts is FANTASTIC. going for full local stt/tts/llm with parakeet, qwen3-tts, and gemma 4 via llama.cpp for my little robot. excite, excite!
https://t.co/5x7vTEE9RN
In-context learning suggests that a model has learned versatile representations. What if we use in-context learning itself as a training task for visual representations?
📣 Introducing 𝗟𝗜𝗟𝗔: 𝗟𝗶𝗻𝗲𝗮𝗿 𝗜𝗻-𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 ✨ @CVPR 2026 Oral ✨
𝗟𝗜𝗟𝗔 trains on videos without manual annotation.
Key idea: An optimal linear mapping that predicts dense cues (e.g. depth, flow), estimated on one video frame, should also predict the corresponding cues of another frame from the same video.
This yields compelling results on dense vision tasks: video object segmentation, (zero-shot) semantic segmentation and surface normal estimation.
Paper, code, models and demo: https://t.co/Xn2SgskKQ8
Joint work with @ma_sundermeyer, Hidenobu Matsuki, David Joseph Tan and @fedassa (and special thanks to David and Federico for hosting my research visit at Google).
#cvpr2026 @Google@MunichCenterML@tumcvg@TU_Muenchen
Big release - Open Source Recursive Self Improvement from @hexoai
Shows AI agent can improve both how it works and what it internally knows after seeing its own task results.
i.e. by repeatedly training on its own task feedback, not by relying on a human to hand-code every strategy.
Most agents today are frozen workers: you can give them better prompts, better tools, better retry rules, and better code, but the actual model usually stays the same.
SIA (Self Improving AI framework) changes the outer workflow, called the harness, and also changes the model’s weights, which are the internal settings that store learned patterns. which means task feedback changes the model’s internal parameters, pushing it toward domain knowledge.
The paper reports a 56.6% gain on LawBench, 91.9% runtime reduction on GPU kernels, and 502% improvement on single-cell RNA denoising over baseline.
HDD firmware hacking: dumping/analyzing/modifying the drive firmware and debugging via JTAG
https://t.co/Ut1DIJHyp9
Credits Ryan Miceli (@Grimdoomer)
#infosec
Released a new paper in which we build neural models for discontinuous systems that can detect when they're wrong.
This is a proof-of-concept, but the general idea could have applications in many domains wherever you need to build world models (including robotics)
The MiniMax M2 series was one of the most widely used open-weight LLM series earlier this year. Now, we got a technical report with some interesting tidbits. I summarized some of them below:
1. Full attention as an anti-trend?:
They tried hybrid sliding-window attention variants (like so many others, like Xiaomi MiMo, Laguna, Gemma 4, Arcee, Olmo 3, etc.). But even though there were efficiency gains, they said that the production-quality tradeoffs were not worth it for M2.
2. Linear and sparse attention deployment issues:
They found that linear and sparse attention are attractive on paper because they reduce the cost of long-context attention, but they are harder to make work well in a production agent system.
In particular, they found that these efficient attention variants may be more fragile when KV-like state or intermediate memory is stored in lower precision.
Also, they have worse prefix caching support, which matters a lot when using coding agents (which reuse a lot of the context).
3. Fine-grained Mixture-of-Experts (MoEs) are useful:
Finally a recent MoE ablation study! It's only on the 2B-active parameter scale, but hey, better than nothing.
Concretely, they compare a baseline with 32 experts and top-2 routing against a fine-grained setup with 128 experts and top-8 routing.
The fine-grained setup improves MATH from 19.6 to 24.1 and HumanEval from 29.7 to 32.5. That's clearly a win for more fine-grained experts (confirming what the DeepSeek MoE paper reported ~2 years ago).
4. Sophisticated agent pipeline
It's probably no surprise, but this papers confirms that training for agent-like behavior on software engineering task is now a big component of the training pipeline.
They mine GitHub pull requests, builds runnable Docker environments, extracts task-specific test rewards, etc.
5. Interleaved thinking for context management
Interestingly, they found that removing reasoning blocks from previous turns results in worse performance, especially in multi-step agent tasks. (Another point why long-context support is so important these days).
6. Speed rewards
It's common to have token usage penalties, but what's interesting is that the MiniMax team adds a task-completion-time reward that depends on wall-clock time. This is to minimize unnecessary (slow) tool calls. Also, I'm thinking that this would encourage agent parallelization (if supported by the harness)
7. Self-evolution
Looks like self-evolution is also already a big design component of open-weight LLMs. E.g., the paper says that M2.7 already handles 30 to 50 percent of the daily RL iteration workload, modifies its own scaffold, and completed a 100-round autonomous scaffold optimization cycle with a 30 percent gain on internal evaluations.
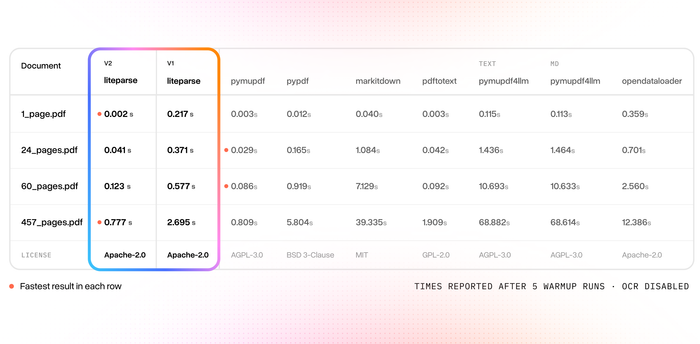
We've created the world's fastest PDF parser ⚡️
And it's more accurate than any other open-source, model-free PDF parser out there (pymupdf, pypdf, markitdown, pdftotext, opendataloader, pymupdf4llm)
Introducing LiteParse v2 - we rewrote the entire library into Rust and adapted it as native packages for Python and Node.
It supports 50+ different document types, can be triggered directly or installable directly within your favorite AI agent.
Blog: https://t.co/ckb0G73ESs
Repo: https://t.co/JNER0mVcB8
// Memory as Connectivity //
One of the cleaner reframings of agent memory I have seen this month.
FluxMem treats memory as the continuously evolving topology of a heterogeneous graph.
Three stages run together: initial connection formation, feedback-driven refinement, and long-term consolidation of recurrent successful trajectories into reusable procedural circuits. During execution, it repairs missing links, prunes interference, and aligns abstraction granularity.
SOTA on LoCoMo, Mind2Web, and GAIA across three distinct memory regimes.
Paper: https://t.co/uNrdgGX4jC
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX