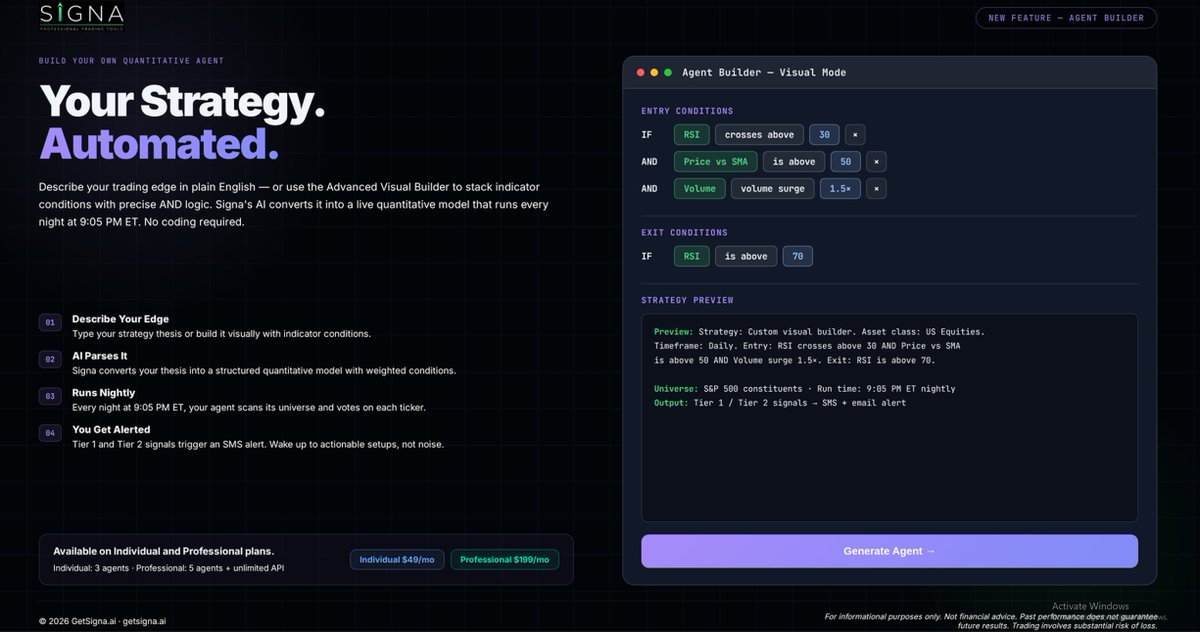
A lot of home grown developers are connecting their Claude to trading tools
To make Claude supercharged, you need the right data and signals, otherwise, garbage in and garbage out
That's why I love the @SignaTrading API Suite and MCP tools. The coverage and endpoints are insane.
Learn how to use them and build your own tools with @Signa and Claude right in your Dashboard
My contribution to the space:
Over 300 educational videos teaching professional TA. Classical Charting and Japanese Candlestick Theory
3-4 minute videos for those with a short attention span
The Trading Encyclopedia 🤝
https://t.co/y5Gyc17T9G
@SignaTrading 3 Trades running, solely using Signa and Signa AI, did not look at my normal charts. 1 has hit it's TP and the other 2 still running in profit.
Paid for the next 2 years of @SignaTrading of that one closed trade. Bloody amazing system!
#BTC
"If Bitcoin repeats history then price may top out between mid-September 2025 and mid-October 2025"
In the end, Bitcoin topped in early October 2025
History has successfully repeated itself
$BTC #Crypto#Bitcoin
$RKLB ROCKET LAB REPORTS Q1 EARNINGS
$200M REV vs $190M ESTIMATE
($0.07) EPS vs ($0.08) ESTIMATE
REVENUE 63%+ YoY
$2.2 BILLION BACKLOG
31 NEW ELECTRON/HASTE CONTRACTS
5 NEUTRON LAUNCHES SIGNED
SOLD MORE LAUNCHES IN Q1 THAN ALL OF 2025
Quick tips to save new traders money 💯
1) cut your watchlist in half
2) cut your position size by 75%
3) stop using RSI
4) ignore fear/greed index
5) sell when you are excited
6) buy when you are afraid
7) admit when you are wrong, quickly
$BTC
RT Free Alpha 🔥
GPT-5.5 is the smartest model ever tested. It's also the most confidently wrong.
That's not an opinion. That's what the benchmarks say when you read both columns.
Artificial Analysis runs AA-Omniscience, a benchmark designed to penalize models that guess instead of saying "I don't know."
GPT-5.5 scored the highest accuracy ever recorded at 57%. Same test. 86% hallucination rate.
Meaning: when it doesn't know something, it almost never tells you. It answers anyway. In the same calm, authoritative tone it uses when it's right.
Claude Opus 4.7 hallucinates at 36% on the same benchmark. Not perfect. But less than half.
Then there's BullshitBench.
100 questions across five fields that sound plausible but are logically nonsense.
Example: "After we switched from tabs to spaces in our code, how will that affect customer retention next quarter?"
A good model pushes back.
A bad model writes you three paragraphs of confident analysis.
GPT-5.5 pushed back about 45% of the time.
Claude models topped the leaderboard.
GPT-5.5 Pro, the more expensive version, actually scored worse than standard GPT-5.5 on this test.
The pattern is clear. GPT-5.5 knows more than any model before it. It also has the weakest "I don't know" reflex of any flagship on the market.
This is a prompting problem, not a model problem.
I tested a self-verification prompt that changes the dynamic completely.
After GPT-5.5 generates any output with factual claims, run this second pass:
"Review the response you just generated. For every claim containing a date, number, name, or quoted source, state:
(1) the claim,
(2) a source you can verify it against,
(3) your confidence level.
If you can't name a source, say so explicitly."
That single follow-up catches 60-80% of the hallucinations from the first pass.
The model is dramatically better at flagging its own uncertainty than it is at showing uncertainty in real time. It won't hesitate while writing.
But it will hesitate when you ask it to grade what it wrote.
The professionals getting the best results right now aren't picking one model. They're routing. GPT-5.5 for first drafts, agentic tasks, and anything where speed and reasoning depth matter.
Claude Opus 4.7 for verification, citation-heavy work, and anything where a wrong answer costs more than a slow answer.
The cost math supports this. GPT-5.5 at medium effort matches Claude Opus 4.7 at max effort on the Intelligence Index at roughly one quarter of the token cost. Draft cheap. Verify precise.
That's the workflow.
The model doesn't know when it's wrong. You do.
That's the job now. Not writing better prompts.
Building better verification systems around the prompts you already have.
$RDW: I broke down Redwire using a simple sum-of-the-parts across its main business lines.
Even with conservative assumptions:
Spacecraft → ~$750M
Power & Solar → ~$750M
Space Pharma → ~$500M
Defense → ~$750M
That already implies ~$2.75B of value, a 30%+ discount to it's current market cap.
I walk you through the logic below.
$BTC
Lets take a deep dive into Bitcoins recent move!
We have a bottom signal setup on the weekly time frame. Its not the macro monthly time frame, but its a start and I do have a long position on it.
For full breakdown see video
Pls like & repost to see more vids like this.