Join us next week (June 20) for the Theory of Interpretable AI seminar series, where @blairbilodeau will discuss the ** fundamental theoretical limitations ** of attribution methods and its implications for interpretability!
🌐https://t.co/e9914pRv7y
@ML_Theorist@tverven
@shai_s_shwartz Realizable case you don’t need any lower bound: https://t.co/5FL4UrIdUS
Most earlier work assumes a lower bound on the density. For misspecified, you can relax this: https://t.co/qYnqVMijuH
But as @aryehazan said elsewhere, you can’t avoid it completely
@mraginsky @aryehazan Modern version with covariates: https://t.co/5FL4UrIdUS
To be minimax for log loss, we must smooth away from the boundary in a way that depends on n. So if you’ve observed zero events, our minimax estimator will still put some small (~1/n) prob on an event happening
@karlrohe There are journals solely devoted to this discussion…
https://t.co/zBBMJnqLzl
https://t.co/JFH6gm2FQx
We don’t need researchers (notoriously bad teachers) to reinvent the wheel again. Perhaps instead engage with those who’ve devoted their career to the problem
@sp_monte_carlo Hot take: these are only used by theorists. Applied stats def to me is “a model, which is a map from data to decisions, is good if applying it to my data gives a good outcome for problem X”. Usually problem X is how best to intervene in a system tomorrow using yesterdays data
@anshulkundaje@natashajaques@PangWeiKoh@_beenkim I agree this sounds like a cool problem that could have a big impact. Right now unfortunately my schedule has no time for a new collab, but I'll let you know if that changes. Also happy to provide any support that I can if you start pursuing it. Thanks for engaging with our work!
Excited to finally share that "Impossibility Theorems for Feature Attribution" is published in PNAS.
TL;DR Methods like SHAP and IG can provably fail to beat random guessing.
w/ @natashajaques@PangWeiKoh@_beenkim
PNAS: https://t.co/GvbseQwYkz
arXiv: https://t.co/bTPTyTdGew
@anshulkundaje@natashajaques@PangWeiKoh@_beenkim I see -- by model class I meant the subset of f learned by {architecture+training algo+data}, but it sounds like your earlier point is right and the large number of baselines averaged is the key here.
@anshulkundaje@natashajaques@PangWeiKoh@_beenkim The class of models you're trying to explain (\mathcal{F} in the paper) is also critical, and has very specific structure for your setting. If we can formalize this structure (I.e., encode it as an assumption), then it may be possible to prove positive results.
@anshulkundaje@natashajaques@PangWeiKoh@_beenkim Baseline is an issue, but it is more than that. I am certain I can reproduce our experiments with DeepLift regardless of baseline (the salient properties that make the experiment work are identical between DeepLift, SHAP, IG, etc).
@anshulkundaje@natashajaques@PangWeiKoh@_beenkim Yes, if you start using multiple baselines and averaging then our theory does not apply (the end task also sounds more global than local in this case). Would be great to prove when such approaches might work, and formalize these methods (AFAIK only heuristic in literature)
@anshulkundaje@natashajaques@PangWeiKoh@_beenkim Our theory (which I believe applies to DeepLift, would have to check for DeepShap) and experiments reveal that not being able to distinguish successes from failures can be especially problematic.
@anshulkundaje@natashajaques@PangWeiKoh@_beenkim Thanks, Anshul. It is impossible to say that a method will *never* work, especially if one can finetune the baseline/method after the model/example are fixed. But in the wild, we don't know the right baseline, and can’t tell if the method is failing since ground truth is unknown.
Our recent PNAS paper shows that widely used interpretability methods, when used to ask simple counterfactual questions about models like “if I pay down this credit card will my credit score increase?”, are provably no better than random guessing. This is really problematic bc...
Many previous work of mine and others hinted ‘something fishy’ about saliency-based methods. But we never had a rigorous proof of what we saw. This work “Impossibility Theorems for Feature Attribution", now published in PNAS, to me marks a point of new beginnings.
Where do we go from here? We now know we can't always trust the intuitive conclusions of feature attributions. But we can use hypothesis testing to understand these methods. This opens up a new direction: design methods that reliably test properties of trained models.
n/n, n = 6
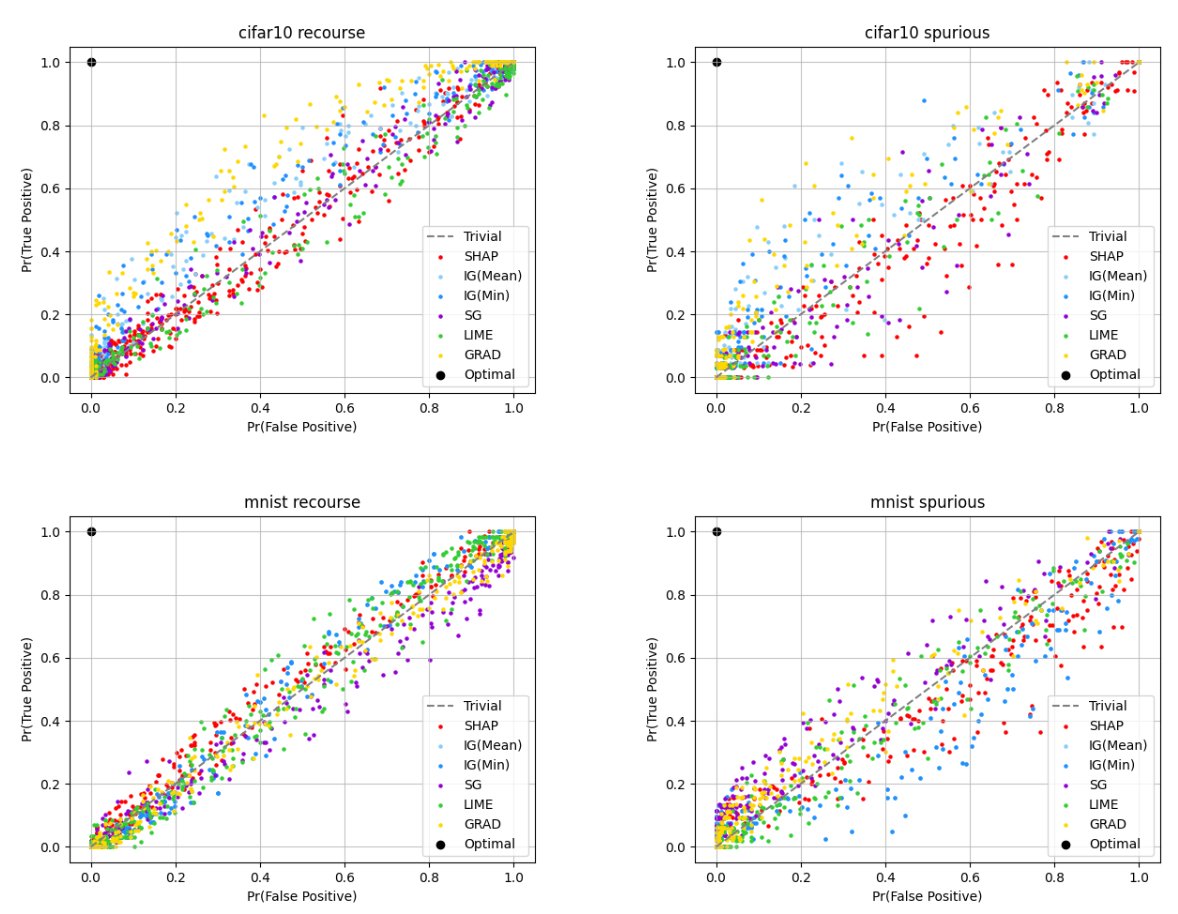
Our theory applies to many models, including neural nets, which we empirically validate. Thm 3.3 is equivalent to saying your ROC curve will be a diagonal, and when we use real methods to conduct hypothesis tests about models trained on ML datasets, that's what we see!