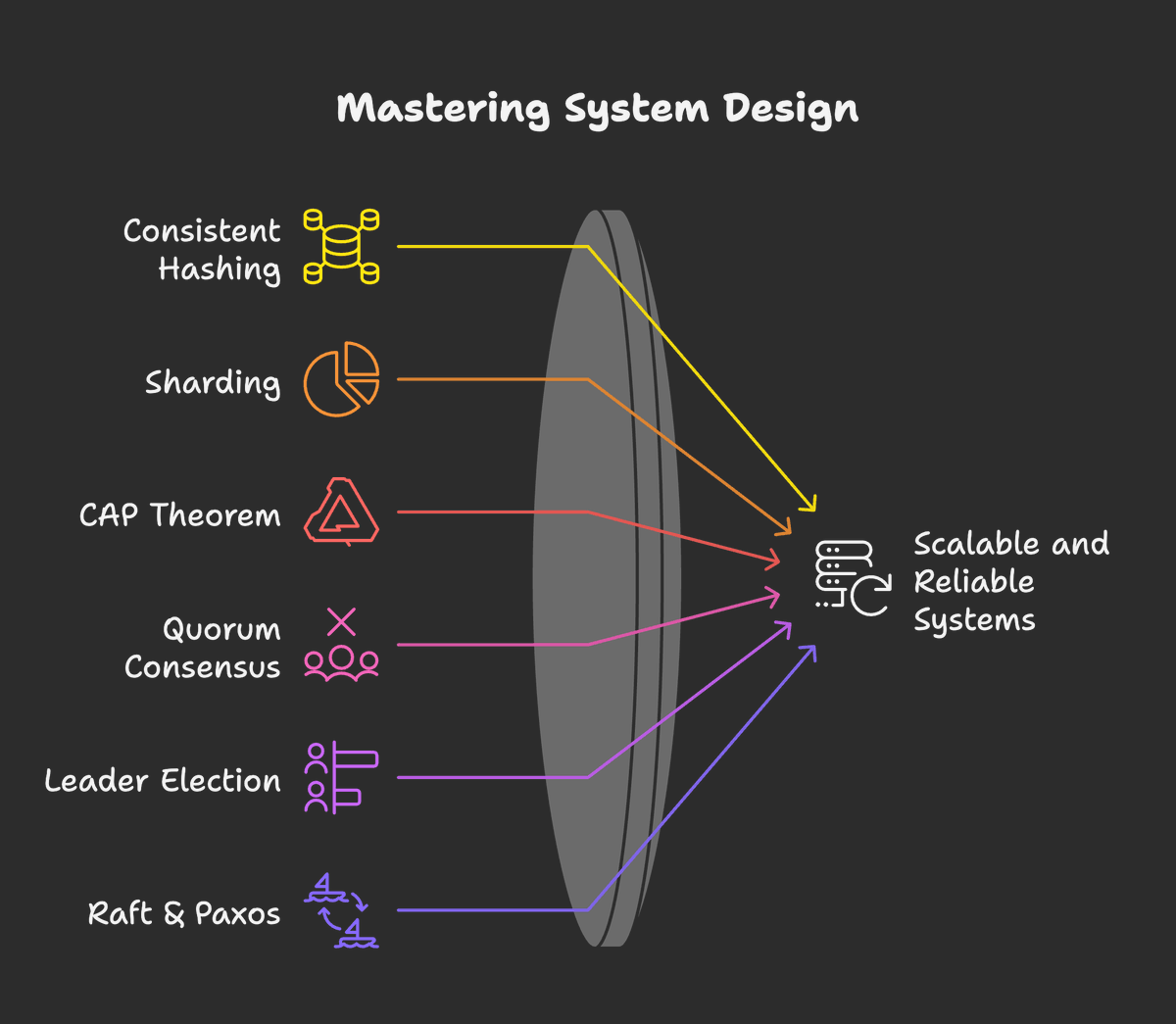
I wrote a new book that has been in the works for years. It is called Root Cause, and it is for those who enjoy the art of backend engineering.
Early in my career, 20 years ago, I built backend and database applications without fully grasping their inner mechanics. Performance issues, race conditions, bugs, and even data corruption often left me lost.
Since that day, I resolved to truly understand how systems work. From networking protocols and intermediary proxies to backend services and various database engines. I made it a habit to follow every request on its journey through the dark alleys of the network, down to the bowels of the database engine, meanwhile interacting with various kernel data structures in the process at every hop, and back.
I became obsessed with understanding what happens behind the scenes in software. Not just what breaks, and how but also why and what was the source of the bleed.
Root Cause is a collection of the most interesting bugs I encountered, ranging from performance bottlenecks and non-deterministic crashes to subtle data inconsistencies and incorrect results.
This book is for anyone curious about how production backend systems really behave under pressure, and how to debug them when they don’t. Even when you don’t have access to the source code.
Root cause consists of 15 chapters, each is a story about a backend bug, with investigation, diagrams, a section of a fundamental concept until the root cause is revealed.
Grab your copy here paperback or kindle ebook on amazon
https://t.co/AgYMX4sWTQ
the engineer who built Claude Code just dropped a 28-minute video on how to write prompts that actually work
I've seen $300 courses that don't cover what he shows in the first 10 minutes
CLAUDE.md files, memory shortcuts, parallel sessions, prompting patterns
all in one video and completely free
works whether you're a developer, a beginner, or someone who's been using Claude for months
based on this, I put together 18 things you can copy and use in Claude today
full guide in the article below
Why we don’t store images/videos to DB and need specialised storage like S3 for this ?
At first, storing images and videos directly inside a database sounds convenient. Everything stays in one place - user data, posts, media, metadata.
But in real-world large scale systems, this quickly becomes a major performance and scalability problem. That is why modern architectures store media files in object storage systems like Amazon S3 or Google Cloud Storage, while the database only stores metadata and file URLs.
User uploads media through the frontend application. The backend server receives the request, but instead of inserting the actual image or video binary into the database, it uploads the media to object storage. The database only stores lightweight information such as the media URL, file type, owner ID, timestamps, captions, and permissions.
The first reason is size. Images and especially videos are extremely large compared to normal database records. A user profile row might be only a few kilobytes, but a single HD video can be hundreds of megabytes or even gigabytes. Databases are optimized for structured transactional data, not for storing massive binary blobs repeatedly. If media files are stored directly in the database, database size grows uncontrollably, backups become huge, replication slows down, and query performance degrades.
The second reason is scalability. Social media and streaming platforms handle billions of media files. Object storage systems are specifically designed for this use case. Systems like Amazon S3 can scale almost infinitely, distribute files globally, and provide high durability automatically. Traditional relational databases are not built to efficiently serve millions of large file downloads simultaneously.
Another major issue is database performance. Databases work best when memory caches can hold frequently accessed indexes and records. Large binary files pollute this cache. Instead of caching useful query data, the system wastes memory handling huge media blobs. This increases latency for normal operations like login, search, or fetching user feeds.
Replication also becomes expensive if media is stored in the database. Distributed databases replicate data across nodes for fault tolerance. Replicating terabytes or petabytes of video data between replicas creates enormous network overhead and storage costs. Object storage systems already solve replication efficiently at the infrastructure layer, so duplicating this work inside databases is unnecessary.
Content delivery is another important factor. Media files are usually served through CDNs (Content Delivery Networks). Object storage integrates naturally with CDNs, allowing users to fetch content from edge servers near their location. This reduces latency and bandwidth usage on backend servers. If media were served directly from databases, databases would become bottlenecks under high traffic.
Then why store URLs in the database at all?
Because applications still need metadata and relationships. The database stores references to the media so the application knows which image belongs to which user, post, or comment.
Object storage also provides lifecycle management features. Old files can automatically move to cheaper cold storage tiers, archives, or backups. Databases are not optimized for such storage tiering mechanisms.
There is also operational simplicity. Backing up a transactional database containing only metadata is much faster and cheaper than backing up enormous multimedia blobs. Disaster recovery becomes simpler because application state and media storage are separated.
Some databases technically support BLOB storage, and for small systems or tiny files it can work. But once systems scale, separating transactional data from media storage becomes almost mandatory.
Happy designing ❤️
How to choose suitable Database for your next project ?
Choosing the right database is not about picking what’s popular, it’s about understanding your application’s behavior and matching it with the database’s strengths.
The biggest mistake people make is starting with a database choice before clearly defining requirements. Instead, start from first thought principles what kind of data do you have, how it is accessed, and how it will scale over time.
The first question to ask is about data structure. If your data is highly structured with clear relationships, like transactions, orders, and users, a relational database like PostgreSQL or MySQL makes sense because it enforces schema and supports joins.
But if your data is flexible, nested, or evolving frequently, a NoSQL database like MongoDB is often a better fit since it allows schema flexibility.
Next comes access patterns, which matter more than data itself. Ask yourself, are you doing heavy reads, heavy writes, or a mix of both?
If your system is read-heavy, caching layers and databases optimized for fast lookups like Redis can drastically improve performance. If you are handling high write throughput, like logging or event ingestion, systems like Apache Cassandra are designed to scale writes horizontally with minimal latency.
Consistency requirements are another critical factor. If your application cannot tolerate inconsistencies, such as in banking or payment systems, you need strong consistency guarantees, which traditional relational databases provide.
But if your system can tolerate slight delays in consistency, like social media feeds or analytics dashboards, eventually consistent systems can give you better scalability and availability.
Scalability is where many decisions change. Vertical scaling (adding more power to a single machine) works well initially and is simpler, but it has limits. Horizontal scaling (adding more machines) requires distributed databases. Systems like Cassandra or DynamoDB are built for this from the ground up, while relational databases can scale horizontally but with more complexity.
Another important dimension is query complexity. If your application relies heavily on complex queries, joins, aggregations, and reporting, relational databases are hard to beat. But if your queries are simple key-value lookups or document retrievals, NoSQL databases will be faster and easier to scale.
Can one database solve everything?
Rarely. Most real-world systems use a combination of databases, known as polyglot persistence. For example, a system might use PostgreSQL for transactions, Redis for caching, and Elasticsearch for search.
Operational complexity also matters. Some databases are easy to set up but hard to scale, while others require more initial effort but handle growth better. You should consider factors like backup, replication, failover, and monitoring. A database that fits your use case but is hard to operate can become a bottleneck later.
Your current scale might not justify a distributed database, but your design should not block you from evolving. Start simple, but choose technologies that allow migration or extension when needed.
There is no “best database,” only the most suitable one for your specific problem. The right decision comes from understanding your data, access patterns, consistency needs, and scalability goals, not from following trends.
Happy designing ❤️
2001: Learn SQL → get a job
2005: SQL + Excel → get a job
2010: SQL + Python + Stats → get a job
2015: SQL + Python + Stats + ML → get a job
2020: SQL + Python + Stats + ML + A/B Testing + Dashboards → get a job
2026:
SQL + Python + Stats + ML + A/B Testing + Dashboards
* Data Engineering
* System Design
* LLMs
* AI Agents
* MLOps
* Cloud (AWS/GCP/Azure)
* Data Pipelines
* Streaming (Kafka/Spark)
* Experimentation Platforms
* Business Understanding
* Communication Skills
* Domain Expertise
* “Ownership mindset”
* “Startup hustle”
* 5 YOE
→ Entry-level role
Somewhere along the way…
“entry-level” stopped meaning entry.
If you’re feeling overwhelmed, you’re not alone.
The bar didn’t just rise…
it multiplied.
System Design Series - Day 8/30
API Gateway Patterns – The Front Door of Your Microservices
API Gateway is the single entry point for all your clients.
Without it:
- Mobile/web clients call 10+ different services directly
- Authentication is duplicated everywhere
- Rate limiting, CORS, logging → repeated in every service
- Services are fully exposed to the internet
With it:
- One clean URL for clients
- Centralized auth, rate limiting, routing, aggregation
- Backend services stay hidden and secure
Here’s everything you need to know about API Gateway patterns.
What is an API Gateway?
Think of it as the hotel front desk
Without a front desk:
- Guests wander around looking for rooms
- No security check
- Housekeeping and room service have no coordination
With a front desk:
- Single check-in point
- Routes guests to correct room
- Handles security, coordination, and requests
API Gateway does exactly that for your microservices.
The Problem It Solves
Before API Gateway:
Mobile app needs user profile + orders:
→ Calls User Service directly
→ Calls Order Service directly
→ Calls Payment Service directly
Problems:
- Client knows internal service URLs
- Multiple network calls (slow on mobile)
- Auth tokens sent to every service
- No centralized rate limiting or logging
- Services exposed to the internet
After API Gateway:
Mobile app calls one URL:
https://api.example. com/profile
Gateway handles everything internally:
- Authenticates once
- Routes and aggregates calls
- Returns combined response
Benefits:
- 1 network call from client
- Services completely hidden (security win)
- Centralized cross-cutting concerns
- Much better client experience
Core Responsibilities:
1. Routing
Maps external URLs to internal services
GET /api/users → User Service
GET /api/orders → Order Service
2. Authentication & Authorization
Validates JWT/OAuth once at the gateway.
Services trust the gateway.
3. Rate Limiting
Prevents abuse (e.g., 100 requests/min per user).
4. Request Aggregation
Combines multiple backend calls into one response for the client.
5. Protocol Translation
Client uses REST → Service uses gRPC (handled at gateway).
Advanced Patterns
- Circuit Breaker → Prevents cascading failures when a service is down
- Request/Response Transformation → Convert old → new API formats
- Caching → Cache frequent responses at the gateway level
- Logging & Monitoring → Centralized observability
When to Use API Gateway
Use it when:
- You have multiple microservices
- External clients (mobile, web, third-party)
- You need centralized auth, rate limiting, or aggregation
Don’t use it when:
- Simple monolith (overkill)
- Only internal service-to-service communication
- Ultra-low latency is critical (extra hop)
Popular Solutions
- Kong (open-source, powerful plugins)
- AWS API Gateway (managed, serverless)
- NGINX + Lua (DIY, lightweight)
- Traefik, Envoy, KrakenD
Summary
API Gateway is not just a proxy.
It is the security layer, traffic manager, and aggregator for your entire backend.
It simplifies client code, hides internal complexity, and centralizes cross-cutting concerns.
Trade-offs:
- Extra network hop (adds latency)
- Becomes a critical component (make it highly available)
Used correctly, it’s one of the most valuable pieces in any microservices architecture.
Tomorrow (Day 9): Inter-Service Communication Patterns
Questions about API Gateway?
Drop them below 👇
#SystemDesign #APIGateway #Microservices #Backend
Don't overthink it.
• Build a Markdown to HTML Converter to learn parsing, text processing, and edge cases
• Build a File Organizer Script to practice filesystem operations and automation logic
• Build a Rate Limiter to understand queues, timing, and control flow
• Build a Chat Server (CLI or basic web) to learn sockets, concurrency, and message flow
• Build a Search Tool (grep-like) to master string matching and performance basics
• Build a Cache System (in-memory + file) to understand eviction policies and data access
• Build a Quiz App with Scoring to practice state, validation, and user interaction
• Build a Backup & Restore Tool to learn file versioning and integrity checks