Molecular biology 🧬 wet lab iteration for cell therapies implies intense R&D resources.
By leveraging AI, computational biology algorithms and multi-omics assay data @StammBio presents MoNA: a cell representation atlas designed to accelerate bio-innovation cycles. Take a look👇
Bubble-free laminar flow. Multiple independent processes. Simultaneous production. No impellers, no spargers, no shear damage to your cells. Continuous harvesting. The real thing on a benchtop.
We have four days and one machine. If you want a demo, book ahead.
If you work in bioprocess development, cell therapy, or biologics manufacturing, and you've been wondering what continuous, laminar flow-based, shear stress-free bioprocessing actually looks like in practice, this is your chance to see it running.
We're bringing something new to BIO International Convention 2026.
Juan Martin Cabaleiro, Subhadeep Das, Faith Wallace-Gadsden, and Jean-Christophe Quillet will be there representing Stämm and running the first public demos of the HTB: our High-Throughput Bioprocessor live.
Recently, I was teaching the Law of Large Numbers and diversification, so I decided to share this illustration here.
As you average more and more independent, identically noisy copies of an image, the noise cancels out and the original emerges.
Code in the comments.
Amazing news: The @StammBio 's High Throughput Bioprocessor is alive 🧬🧬🧬 .
The automated platform based on continuous laminar flow microfluidics changes the game in scaling bio-manufacturing. Take a look 👇
We’re redefining biomanufacturing. Today, we introduce the High-Throughput Bioprocessor (HTB), Stämm’s new automated platform to rethink biological scaling.
We’re redefining biomanufacturing. Today, we introduce the High-Throughput Bioprocessor (HTB), Stämm’s new automated platform to rethink biological scaling.
my (first!) article, “From the virtual community to ‘Trust and Safety’: eBay (1995–2007) and the rise of platform governance” is out on Big Data & Society! it is a history of content moderation at eBay, where they coined the term Trust and Safety 🌐 link below
can confirm these are the vibes
if you’re questioning whether staying in academia, quant, big tech, or a big lab is how you want to spend the singularity, hit me up
For decades in the biopharmaceutical industry, bigger was better: massive tanks, sprawling facilities, global blockbusters. But rising biosimilar competition and demand for specialized therapies are forcing a shift. The old batch paradigm is giving way to a new way.
Never been a better time to pivot into biology.
The problems are very far from solved. Engineering skills will be extremely important in continuing to push the frontier forward. It's hard, but wildly worthwhile.
Leave B2B SaaS to agents :)
Representation learning is the idea that instead of hand-designing features, algorithms should learn the best way to represent data directly from examples. In probability theory, this corresponds to finding latent variables or transformations that make complex joint distributions simpler and closer to independent, which improves inference and prediction. In statistics, representation learning appears in factor models, principal component analysis, and mixture models, where high-dimensional observations are summarized by a few informative hidden components. In machine learning, deep neural networks, embeddings, and autoencoders learn hierarchical representations that capture edges, shapes, words, meanings, and abstract concepts, enabling powerful performance in vision, language, and recommendation systems. In real life, representation learning allows computers to understand faces, voices, medical scans, and user behavior by converting raw signals into meaningful patterns. By discovering the right internal coordinates of data, representation learning makes learning, generalization, and decision-making possible at scale.
Image: https://t.co/R0w3TI5ika
The video below shows how the full circuit works and what happens inside the cartridge as cells grow in continuous laminar flow. https://t.co/xOUjuaYeJx
A visualization of a flow model that transforms a 1D standard Gaussian into a Gaussian mixture.
The heatmap shows the changing density and the white lines reflect the trajectories of individual samples over time.
Learned something very interesting today!
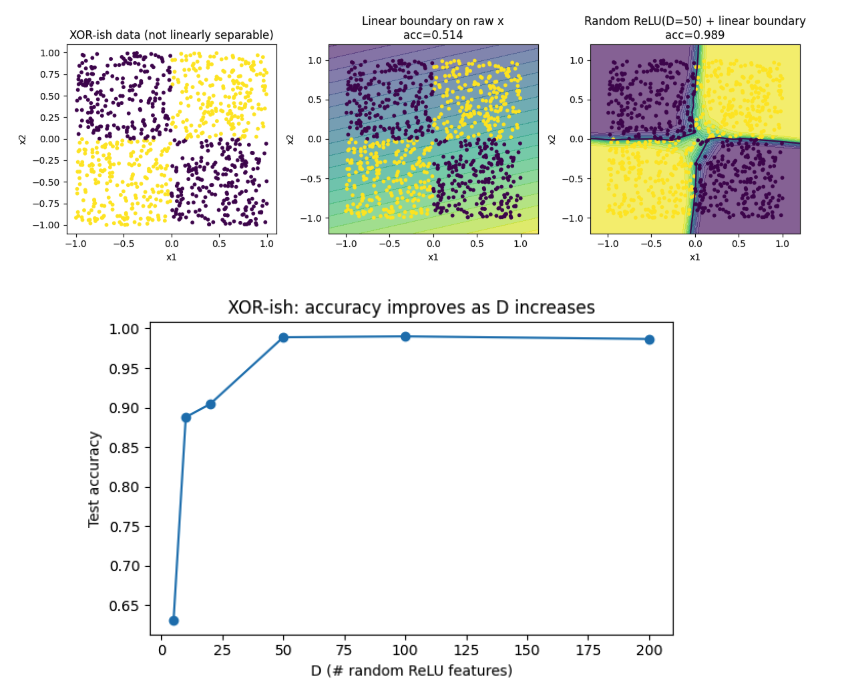
Random projections of a non-linearly separable data onto high dimensional spaces is enough to make it linearly separable.
Consider a dataset like XOR that you can't linearly separate. Now, if you project each 2D point onto a D (=50) dimensional space using *randomly* initialised basis vectors, each direction creates a tiny difference between the classes (e.g. gives 51-52% accuracy) because expectation of two classes differs slightly when randomly projected.
So each randomly projected feature becomes a tiny discriminator and when you aggregate it over 20-50 such discriminators, a linear classifier is able to separate them perfectly by simply learning how much to weigh each feature.
One intriguing possibility of this is that we're able to train deep networks because random projections make most of the data already separable, making the job of gradient descent easy.
Take two large random matrices and linearly interpolate between them at several hundred steps. Compute the eigenvalues for each interpolated matrix, then plot them in the complex plane. The result is shown here.
Made with #python#numpy#matplotlib