We found that visual foundation encoder can be aligned to serve as tokenizers for latent diffusion models in image generation!
Our new paper introduces a new tokenizer training paradigm that produces a semantically rich latent space, improving diffusion model performance🚀🚀.
New paper: AsymFlow🔥
JiT x0-prediction is not enough for pixel generation. Better keep velocity in a low-rank subspace:
- 1.57 FID on ImageNet (best pixel flow model)
- Finetunes FLUX.2 klein into pixel space, beats the original on HPSv3/DPG/GenEval (#1 overall on HPSv3)
1/7
Too many REPA / RAE / representation alignment papers lately?
I was lost too, so I wrote a blog post that organizes the space into phases and zooms in on what actually matters for general/molecular ML.
Curious what folks think - link below!
🔗 Blog: https://t.co/6aJf8DCWTa
Excited to present UltraZoom at SIGGRAPH Asia next Tuesday (Dec.16)!
UltraZoom converts sparse phone captures of an object into a single gigapixel-resolution image that you can seamlessly explore. Threads below.
Website: https://t.co/XinzBbkEXH
Paper: https://t.co/Ed26gMUaqZ
Excited to announce a new track of accelerating Generative AI:
pi-Flow: Policy-Based Few-Step Generation via Imitation Distillation
https://t.co/6ro55E1XGP
Distill 20B flow models now using just an L2 loss via imitation learning for SOTA diversity and teacher-aligned quality.
The Representation Autoencoders (RAE) by @sainingxie's team is fascinating — a brilliant demonstration that high-dimensional diffusion is indeed feasible.
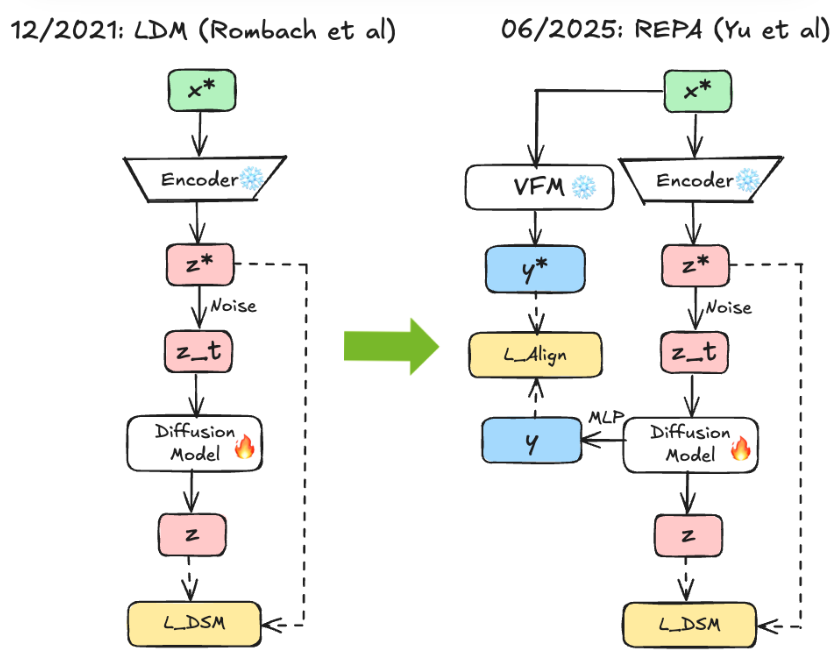
In our latest work on semantic encoders, we align a pretrained foundation encoder (e.g., DINOv2) as a visual tokenizer, achieving better reconstruction quality while preserving semantic consistency. Instead of freezing the encoder, we introduce a semantics-preserving fine-tuning strategy that significantly improves reconstruction quality.
I can see great potential in combining RAE with our approach to build semantically rich tokenizers with large channel dimension and strong reconstruction fidelity.
We found that visual foundation encoder can be aligned to serve as tokenizers for latent diffusion models in image generation!
Our new paper introduces a new tokenizer training paradigm that produces a semantically rich latent space, improving diffusion model performance🚀🚀.
@SwayStar123@sainingxie Yes! I can see great potential in combining RAE with our approach to build semantically rich tokenizers with large channel dimension and strong reconstruction fidelity (we fine-tuned the encoder for better reconstruction).
We found that visual foundation encoder can be aligned to serve as tokenizers for latent diffusion models in image generation!
Our new paper introduces a new tokenizer training paradigm that produces a semantically rich latent space, improving diffusion model performance🚀🚀.
On LAION 2B dataset, we train a text-to-image diffusion model on our tokenizer, which converges faster and surpasses the FLUX-VAE baseline.
Check out more details and results in our paper!
[8/N]
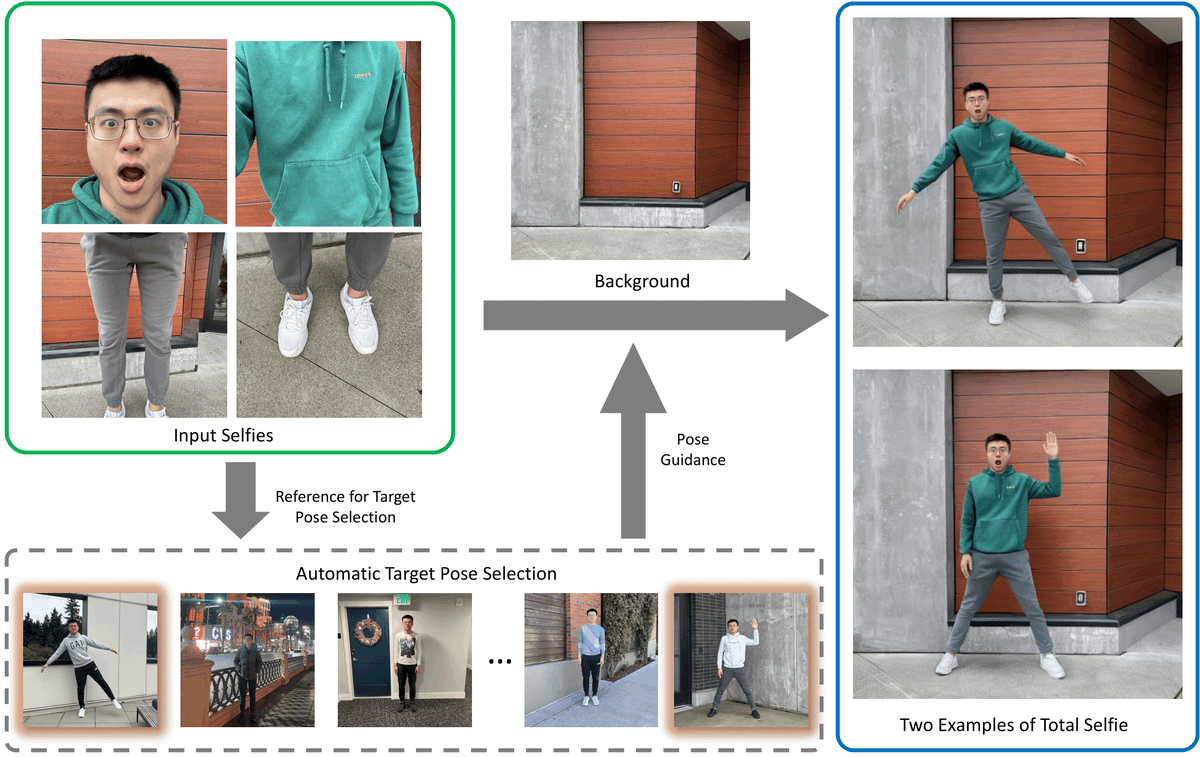
#CVPR2024 Arm-captured selfies only capture your partial body. Instead, what if you could capture a full-body photo that someone else would take of you in the scene?
We present Total Selfie, which generates full-body selfies from photographs originally taken at arms length. 1/n












![bowei_chen_19's tweet photo. On LAION 2B dataset, we train a text-to-image diffusion model on our tokenizer, which converges faster and surpasses the FLUX-VAE baseline.
Check out more details and results in our paper!
[8/N] https://t.co/d8N9PJaOvA](https://pbs.twimg.com/media/G2HLl6WaQAA703h.jpg)