You're already logged into the sites you want to automate. Your automation should be too.
The new Browserless CLI reads the login from your own Chrome, Edge, or Brave and turns it into a cloud profile. Set it up once with a single command, and every session after starts already signed in.
Learn more below.
We started as “headless Chrome in the cloud.” That’s still in there, but it's not the whole story.
Browsers as a Service is still the core. Web APIs are the LLM-era layer. The MCP server lets your AI agent drive a real Chrome session, state and all. And all of it runs self-hosted on your hardware if you need it.
Same stealth infra underneath everything. All on the same bill.
Which one didn't you know we shipped?
You pay each time you have to log in on each browser session. Scrapers, agents, internal automation. The login bill adds up.
That’s why we just shipped Authenticated Profiles.
Log in once on Browserless. Reuse that saved login across unlimited parallel sessions.
@sir4K_zen The two params are:
- solveCaptchas=true → turns on our CAPTCHA engine
- integrations=browseruse → bridges pause/resume into Browser Use's watchdog
You just append them to your Browserless WebSocket URL. Full setup here: https://t.co/Z5UNdjjSWp
CAPTCHAs are the #1 reason Browser Use agents fail in production.
Run it on Browserless and that just stops being a problem. Two parameters. Free tier included. Same engine running production automation for thousands of companies → https://t.co/7XvBwBu1YE
One request, multiple formats: HTML, Markdown, links, screenshot, PDF.
We've solved millions of CAPTCHAs over 8 years. Smart Scrape puts all of it behind one endpoint.
Try it: https://t.co/kUaa3BiWdN
Scrape any URL. One endpoint. Zero configuration.
Introducing Smart Scrape API.
The API finds the fastest path to your content, and you only pay for the strategy that works.
How it escalates:
→ Direct fetch first (cheapest)
→ Proxy fallback if blocked
→ Headless Chrome for JS-rendered pages
→ Automatic CAPTCHA solving when needed
Simple pages stay cheap. Tough pages get through.
This is a big deal for browser automation infrastructure. ARM64 Chrome means lower compute costs, fewer Chromium edge cases, and way more flexibility in where you run headless browsers. We're already exploring what this unlocks for Browserless users.
Google is finally bringing Chrome to ARM64 Linux devices. Very exciting for two reasons: better automation capabilities — and much cheaper.
It also means you’ll be able to do a lot more with @browserless and Raspberry Pi. Stuff like:
- Being able to run on many different machines, like AWS arm64 instances.
- Watch and record sites that have mp4 video files.
- Run tests on a variety of new machine types if you’re unit-testing.
Another big plus is that you won’t have to deal with Chromium-related edge cases and automation setbacks like fingerprint differences, missing codecs, etc.
Raspberry Pi is already very popular with home automation tinkerers, so I expect to see some really cool use cases in the near future. Will definitely be keeping an eye out.
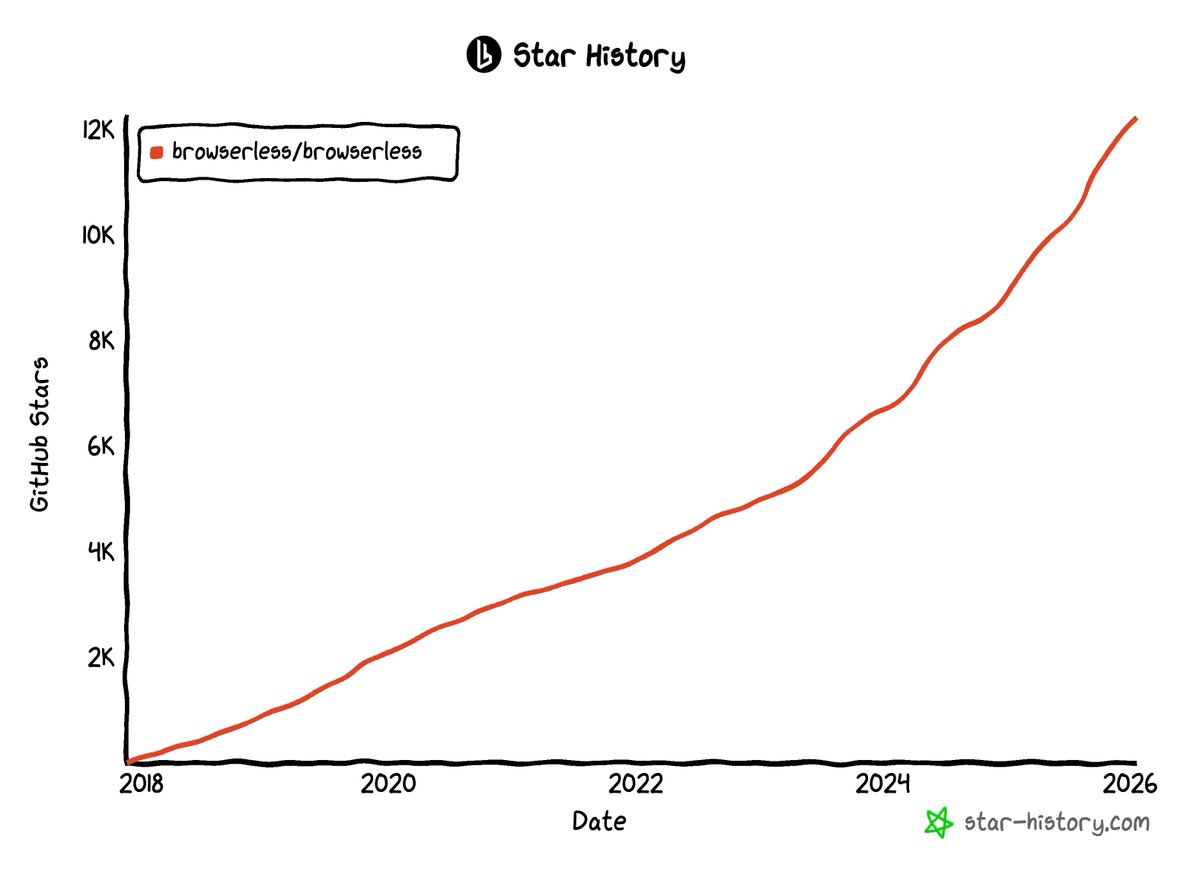
Browserless crossed 12,000 GitHub stars last month.
8 years of commits. 77 contributors. Almost 1,000 forks. Thousands of production environments we will never see.
Here is what open source taught us about building a company:
The fastest way to learn is to let users tell you what you missed.
Most feature requests are noise. The ones that show up three times from three users are signal.