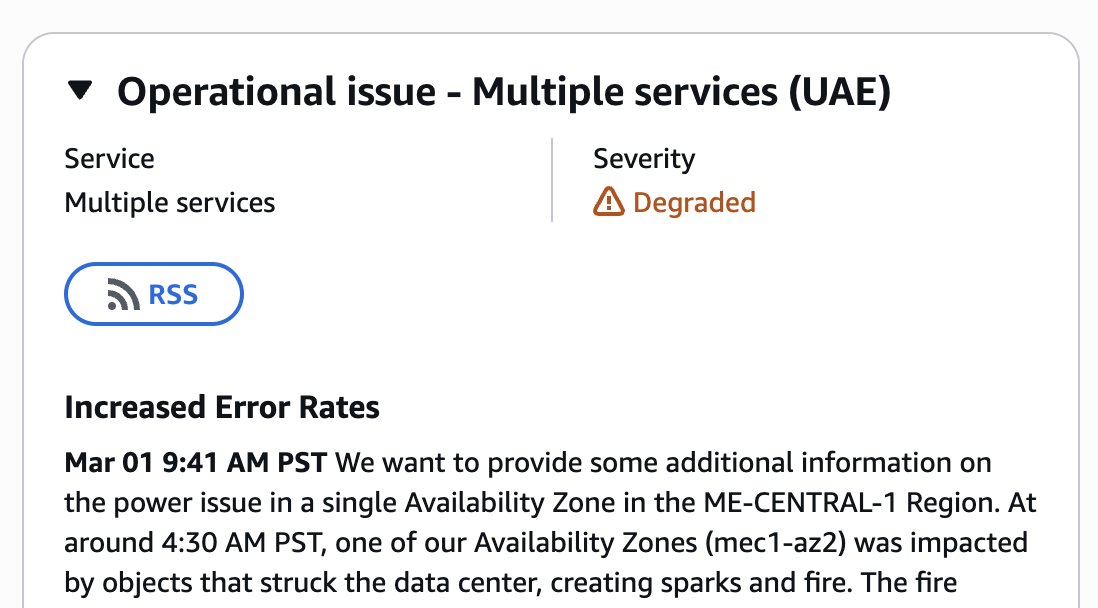
Antigravity CLI 1.0.1 is out.
Key updates:
- Fixed OAuth not persisting in some environments.
- Enhanced the visual experience on Windows.
- Added the new "proceed in sandbox" permission control.
Restart agy to auto update or run “agy update".
See the full changelog for details:
https://t.co/zJNgkJck3Z
This is why PR diff speed matters. This isn't a dunk on GitHub specifically, because GitLab, Forgejo, etc. are all equal or worse. But this is the kind of thing that drives me nuts, because this is a core workflow and its slow enough I literally take my hands off the keyboard.
Btw, when my mouse jiggles on the left, its because the page is literally skipping frames and I'm instinctively shaking my mouse to see if it'll respond. And on the keyboard input you can literally here me finish typing before a letter even shows up.
For someone like me who is an expert at these tools, my brain navigates the tool dramatically faster than it can keep up, and that is not good. The tool should not get in the way.
Ghostty is leaving GitHub. I'm GitHub user 1299, joined Feb 2008. I've visited GitHub almost every single day for over 18 years. It's never been a question for me where I'd put my projects: always GitHub. I'm super sad to say this, but its time to go. https://t.co/DQDemHdytV
Performance Hints
Over the years, my colleague Sanjay Ghemawat and I have done a fair bit of diving into performance tuning of various pieces of code. We wrote an internal Performance Hints document a couple of years ago as a way of identifying some general principles and we've recently published a version of it externally.
We'd love any feedback you might have!
Read the full doc at: https://t.co/jej95g236P
I think in a moment when GitHub’s reputation amongst developers is at an all time low, making the policy change to charge for self hosted runners in any scenario instead of making other technical changes to make GH runners more attractive will go down as a very bad move.
@joseph_h_garvin@HSVSphere and the “await” keyword is an advantage, not a drawback, exactly in the same was as baking errors (Result) into the type system.
if i call 2 uncolored functions, it should prob be sequential. 2 non-dependent async functions should be done concurrently (eg, join!).
@joseph_h_garvin@HSVSphere you don’t need 2 versions. any library doing IO should always be async first. users that want to opt out should take a bridge.
(async first is extremely important - a bridge from async to threaded code likely requires spawning a thread, which is prohibitively expensive)
@HSVSphere And I don't understand why anyone would strive for a cancellation system that doesn't "just work" by default by clearly marking cancellation points with those function colors (await, co_await).
Anything else will inevitably lead to code that does not respect cancellation.
@HSVSphere I never understood why ppl complained so much about function coloring, either in Rust or other languages.
If you want to opt out of the ecosystem, take a cheap bridge (e.g., `futures::block_on`), which simply parks the thread until the future completes. Not hard.
The only cancellation scheme I want to use is one that:
1. clearly marks cancellation points (e.g., await/co_await with function colored return type).
2. works by default with no explicit checks.
3. allows for some code to run when cancelled (e.g., RAII destructors, or defer).
> The conditions under which cancellation requests are honored are defined by each I/O implementation.
Oh Zig, don’t fall into the trap of thread cancellation.
In software, we mostly care about two metrics: whether the code does what we want and whether it does so efficiently. Often, efficiency isn’t critical. Keep building web services in Python—that’s fine.
But when performance matters—and it eventually does—people sometimes assume they’re facing a Pareto distribution: one bottleneck that, if eliminated, will drastically improve performance. This holds true at the micro level, in isolated benchmarks, but not broadly.
Consider shopping for a TV. You first head to the TV section, then narrow it down to the sizes you need. Next, you optimize for price, seeking the cheapest TV that meets your needs.
How do you produce affordable TVs?
As the new CEO of a TV company, you’d first examine major costs. Transportation, perhaps? Some cost components, like taxes or already-cheap boxes, can be ruled out as insignificant.
However, you eventually realize that making affordable TVs requires getting hundreds, if not thousands, of details right.
The same applies to software. High efficiency demands getting hundreds of things right. This is often used as an excuse not to optimize: “Why bother with X? It only helps in specific cases.” That’s fallacious. To win the war, you must win hundreds of battles. Win the battles one by one.
AI efficiency is important. Today, Google is sharing a technical paper detailing our comprehensive methodology for measuring the environmental impact of Gemini inference. We estimate that the median Gemini Apps text prompt uses 0.24 watt-hours of energy (equivalent to watching an average TV for ~nine seconds), and consumes 0.26 milliliters of water (about five drops) — figures that are substantially lower than many public estimates.
At the same time, our AI systems are becoming more efficient through research innovations and software and hardware efficiency improvements. From May 2024 to May 2025, the energy footprint of the median Gemini Apps text prompt dropped by 33x, and the total carbon footprint dropped by 44x, through a combination of model efficiency improvements, machine utilization improvements and additional clean energy procurement, all while delivering higher quality responses.
See the blog or technical paper for more about our methodology and ongoing efforts.
Blog:
https://t.co/CoMm5gV9SR
Link to detailed paper: https://t.co/UBi9rd6gEC