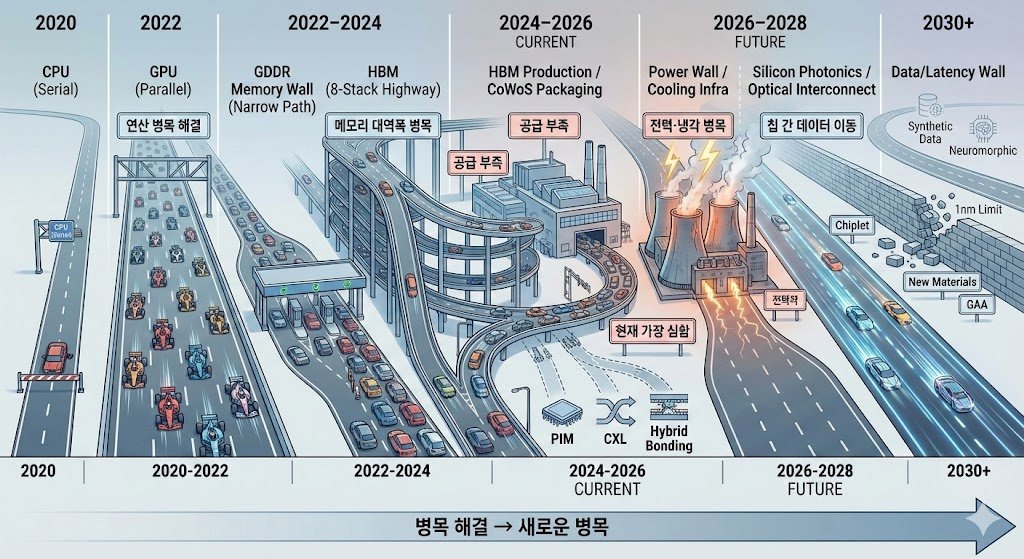
데이터센터/반도체 병목 타임라인 정리
대 AI시대에 꼭 알고 있어야 합니다!!
공부해야됩니다 여러분!!!!
1. CPU → GPU 전환 (연산 병목)시기: 2020~2022년
왜 병목 됐나?
딥러닝은 수천 개의 간단한 계산(행렬 곱셈)을 동시에 해야 함. CPU는 "하나씩 순서대로" 잘하지만 병렬이 약함.
GPU는 수천 개 코어가 동시에 일해서 AI 학습 속도가 10~100배 빨라짐.
AlexNet(2012)부터 GPU가 필수 됐고, ChatGPT급 모델 나오면서 완전 전환.
🔸쉬운 설명
CPU는 서울에서 출발해서 대전, 광주, 대구,부산,강원도 가는데 차례대로 들렀다 감, GPU는 서울에서 차 여러대로 동시에 출발해버림.
CPU는 똑똑한 한 명이 책상에서 계산기 두드리는 거라면, GPU는 수천 명의 단순 노동자가 손으로 계산하는 거임.
계산기는 복잡한거 계산 잘하지만 AI학습은 단순한거 동시에 빨리하는게 최고임.
🔸결과/영향
딥러닝 연구자들이 CPU로 훈련하다가 GPU(Hopper 이전 세대)로 바꾸니까 하루 걸리던 게 몇 시간으로 줄음.
Nvidia가 ��걸 CUDA 소프트웨어로 독점적으로 밀어서 시장 잡음.
🔸2026년 현재 상태
이미 해결. 이제 GPU가 기본, 모두가 GPU 클러스터로 훈련함.
단일 GPU 중심 → 현재: 전체 시스템 orchestration으로 병목 이동
2. 메모리 대역폭 부족 (Memory Wall)시기: 2022~2024년
왜 병목 됐나?
GPU 연산 속도는 빨라졌는데, 메모리에서 데이터 가져오는 속도가 못 따라감.
일반 GDDR 메모리는 "좁은 길"이라 빨리 못감.
AI 모델 파라미터가 수억수조 개라 데이터 이동이 엄청나게 필요함. (엔비디아가 "메모리 대역폭이 성능의 80% 결정한다"고 할 정도)
🔸쉬운 설명
GDDR 메모리는 1차로의 단일 도로, HBM 메모리는 8층짜리 복합도로
🔸결과/영향
HBM이 필수로 부상. 개발자들이 모델 키울 때마다 메모리부터 채움.
🔸2026년 현재 상태
HBM으로 넘어갔지만 여전히 핵심.
모델이 커질수록 "메모리 월" 계속 존재.
3. HBM 공급 부족시기: 2024~2026 (현재 가장 심함)
왜 병목 됐나?
하나의 AI GPU에 HBM 80~200GB 필요.
모델(예: GPT-4급)이 커지면서 HBM 수요 폭발.
생산이 복잡해서 SK하이닉스·삼성·Micron이 따라가지 못함. 가격 70~100% 폭등.
🔸쉬운 설명
고성능 스포츠카 엔진(GPU)을 만들었는데, 도로가 논길이라 어차피 달리질 못함. 생산해도 어차피 못 쓸거 생산할 필요가 없음;;
🔸결과/영향
Nvidia Blackwell 같은 최신 GPU 생산 지연( HBM 부족으로 초기 생산 지연됐고, 2026년 초에도 여전히 매진 상태. Rubin (2026년 말 예정)도 HBM4 준비 중인데, 공급 부족으로
기다려야 되는 상황.
엔비디아가 SK하이닉스에 선금 주고 예약할 정도임(AI 회사들 HBM 확보 경쟁 치열함)
🔸2026년 현재 상태
여전히 매진. 2026년 하반기부터 용량 확대되면서 조금씩 풀릴 전망.
3-1. 다시 메모리 부족?? (메모리 용량/전력 병목)
이제 도로(HBM)도 넓혔는데, 또 다른 문제가 터짐.
용량의 한���: AI 모델이 커지는 속도가 반도체가 커지는 속도보다 훨씬 빨라 아무리 HBM을 쌓아도 AI 전체 데이터를 다 담기엔 창고(용량)가 부족해짐.
계산기(GPU)가 빨라지면 도로(HBM)가 막히고, 도로를 뚫으면 창고(용량)가 부족해지는 끝없는 꼬리잡기를 하고 있는 상황.
삼성과 하이닉스의 '다음 수'
① PIM (Processor-In-Memory)
메모리는 저장만 해? 아니, 메모리 안에도 작은 계산기를 넣어버리자.
데이터가 밖으로 나가지 않고 메모리 안에서 간단한 계산을 끝내버림.
그럼 GPU로 가는 도로가 훨씬 한산해지겠지?
② CXL (Compute Express Link)
메모리 용량이 부족해? 그럼 여러 대의 컴퓨터 메모리를 하나처럼 연결해서 쓰자.
지금은 칩 하나당 꽂을 수 있는 메모리 용량이 정해져 있는데, CXL을 쓰면 마치 외장 하드를 붙이듯 메모리 용량을 무한대로 확장할 수 있음.
'창고 부족' 문제��� 직접적으로 해결하는 기술.
③ 하이브리드 본딩 (Hybrid Bonding)
HBM 층을 쌓을 때, 중간에 전선을 쓰지 말고 칩끼리 아예 붙여버리자.
압도적인 데이터 전송 속도: 범프(납땜)가 없기 때문에 신호가 지나가는 경로가 짧아짐.
이는 저항을 줄이고 데이터 전송 효율을 극대화.
초고밀도 연결 (I/O 확장): 범프는 크기 때문에 칩 하나에 수천 개 정도만 넣을 수 있지만, 하이브리드 본딩은 구리 패드를 아주 작게 만들 수 있어 수만~수십만 개의 연결 통로를 확보할 수 있음.
4. 고급 패키징 (CoWoS 등)시기: 2025~2026 중반
왜 병목 됐나?
HBM 있어도 GPU 다이 + HBM을 정밀하게 붙이는 "조립" 기술 부족.
보통 메모리는 컴퓨터 메인보드에 따로 꽂는데, HBM은 너무 빨라서 멀리 떨어져 있으면 속도가 안 나. 그래서 아예 GPU 바로 옆에 바짝 붙여서 한 몸처럼 패키징해야됨.
TSMC CoWoS가 90% 점유, Nvidia가 용량 대부분 예약.(용량 60% 차지)
🔸쉬운 설명
엔진과 연료 탱크 다 만들었는데, 그걸 차체에 제대로 붙이는 공장이 꽉 차서 차 완성 못 함. 부품 쌓아놓고 기다리는 꼴.
🔸결과/영향
완성품 출하 지연. AMD·Google 등 다른 회사도 타격.
🔸2026년 현재 상태
전체 AI 칩 출하 지연. 상반기까지 타이트함 . TSMC 확대 투자중이라 하반기부터 완화 예상.
5. 전력·냉각·인프라 (Power Wall)시기: 2025~2027
왜 병목 됐나?
최신 GPU 하나가 700~1000W+ 먹음. 대규모 클러스터(수만 개 GPU)는 원전급 전기 필요.
2026년 AI 데이터센터 전력 수요가 100GW 넘을 예측 (미국 전체 전력 10% 차지 가능). Nvidia 클러스터 하나가 도시 하나 전기 먹음.
🔸쉬운 설명
엔진이 너무 강력해져서 연료(전기) 충전소가 따라가질 못함. 충전소 없으면 차 운행 못하고 세워둬야지.(칩들 다 준비돼도 돌리지 못하는 상태 발생)
🔸결과/영향
데이터센터 건설 지연, 전기 요금 폭등, 일부 지역(미국 버지니아 등) 그리드 포화.
🔸2026년 현재 상태
센터 건설 지연, 전기 요금 폭등.
2026년부터 본격 "파��� 월" 느껴짐.
일론머스크가 우주데이터센터로 갈 수밖에 없다고 하는 이유.
6. 칩 간 / 랙 간 데이터 이동 (Interconnect / Photonics)시기: 2026~2028 예상
왜 병목 됐나?
GPU 수만 개 연결할 때 기존의 구리선으로는 대역폭·지연·전력·열 한계. 빛(광학)으로 바꿔야 함.
🔸쉬운 설명
집 안(칩 안)은 초고속인데, 집 밖 도로(칩 간)가 국도로 막혀서 전체 느려짐. 고속도로(광학) 깔아야 함.
🔸결과/영향
대규모 훈련(예: GPT-5급)에서 칩 간 데이터 이동이 전체 시간 30% 차지.
Nvidia Spectrum-X, TSMC Silicon Photonics 도입 중.
🔸2026년 현재 상태
본격 시작 단계. CPO(Co-Packaged Optics) 상용화 가속.
7. 미세화 한계 + 칩 제조 용량 전체 (1nm 이하)시기: 2027~2030 이후
왜 병목 됐나?
2nm 아래로 가면 양자 효과로 칩 불량 폭발 등 물리 한계. EUV 장비(ASML 독점)·수율 문제.
TSMC 2nm 양산 중이지만 수율 낮음.
Rubin도 이 한계에 부딪힐 가능성 있음.
🔸쉬운 설명
벽돌을 너무 작게 깎다 보니 부서지기 시작. 그냥 작게 만드는 대신 여러 조각(chiplet) 붙이는 방식으로 우회.
🔸결과/영���
단순 미세화로 성능 올리기 어려움
- 새 아키텍처: Chiplet (작은 칩 여러 개 연결) 확대 → AMD·Intel 이미 사용, Nvidia도 도입 중.
- 새 ���료: 2D 물질(MoS2 등), 탄소 나노튜브, Gate-All-Around(GAA) → CFET로 진화.
- 백사이드 전력 공급: 칩 뒤쪽으로 전기 공급(저항은 줄어들고 속도는 빨라짐), (TSMC·Intel 2026~2027 도입).
- 대안 컴퓨팅: 광학·퀀텀 칩 (아직 초기, 2030년대 실용화?).
🔸2026년 현재 상태
성능 증가 둔화. chiplet·새 재료로 대응 중.
아직은 2~3nm 용량 타이트하지만 HBM/CoWoS만큼 심하지 않음.
8. 데이터·지연 벽 (Latency Wall)시기: 장기 (2030년대?)
왜 병목 됐나?
고품질 훈련 데이터 고갈 + 분산 훈련 시 빛 속도 한계(지연).
인터넷 전체 데이터 긁어도 부족. 합성 데이터나 효율 알고리즘 필요.
🔸쉬운 설명
먹을 게 다 떨어짐 (데이터 부족), 분산으로 카바쳐보려 해도 속도가 안나옴
🔸결과/영향
더 큰 모델 만들기 어려움. 합성 데이터·효율 알고리즘 필요.
- 합성 데이터: AI로 가짜 데이터 만들어 학습 (이미 OpenAI 등 사용).
- 효율적 알고리즘: MoE(Mixture of Experts)처럼 필요한 부분만 깨우는 방식 → 전력·데이터 덜 먹음.
- 광학 연결: 칩 간 빛으로 데이터 이동 (Silicon Photonics, 2026~2028 상용화).
- 분산 학습 최적화: 엣지 컴퓨팅 (스마트폰·자동차에서 일부 학습) → 중앙 집중 줄임.
- 장기: 뉴로모픽 칩 (뇌 흉내, 데이터 덜 필요).
🔸2026년 현재 상태
아직 본격적이지 않음. 합성 데이터 사용 증가 중.
이건 "무어의 법칙" 끝나는 시대 대응 전략. 완벽히 해결되진 않지만, 이 방향으로 AI 성장 속도 유지하려 함.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
🎯투자자인 우리는 여기서 순환 싸이클을 생각해서 현재 병목이 뭐고 다음은 뭐가 될지,
그리고 뭐가 개발됐다고 하면 (예,HBM4같이) 그다음은 뭐가 병목이겠구나 생각해야함
그리고 추후에는 뭐가 필요한지 등을 파악해놔야 함
아주 긴시간동안 공부하고 정리했음.
호응이 매우(매우) 좋으면, 각 섹터별로 어떤 기업들이 영향을 미치고 있고, 앞으로 ���떤 기업들이 좋을지도 분석해 보겠음
회사 기획자분이 감사하게도 여기 만화에 나오는 개발자가 나같다고 칭찬해주셨다.. 근데 나도 아무 기획자나 편들어주진 않는데, 보통 내가 편들어주는 기획자분들은 자기 실적 쌓으려고 개발팀에 뭐 시키려는 분들이 아니라 진짜 고객들이 불편해할까봐 걱정하고 기능 추가하려는 분들이다. 구분잘됨