Introducing RelayKing.
https://t.co/D55uuCv6mX
Blog: https://t.co/usrPECsVno
Automatically identify relay attack paths. No longer will you be left to manually detect a comprehensive inventory of all the relaying vectors on your engagements.
It will detect signing/EPA settings on all protocols you specify, NTLM reflection CVEs, and WebDav WebClient presence. Then, produce a comprehensive report of the relaying vectors on the network in your preferred output format. This ensures that you report ALL vulnerable instances easily, without the need for manual patching together of results from various tools.
Ideal usage is with a set of low-privilege AD credentials, but it also supports unauthenticated scanning (with far less coverage). See GitHub and the blog post for more details.
Please note that there ARE bugs. The LDAP(S) detection has been annoying but SHOULD be mostly solid. If you get suspicious results from it, please report an issue on GitHub with the config RelayKing reported, versus the actual one.
Enjoy!
ANTHROPIC JUST KILLED THE DEMO AGENT ERA.
Their Agents team showed exactly what production grade looks like.
Not theory. Not a tutorial. A four layer framework for multi agent systems built to actually work in the real world.
30 minutes.
This is the video I wish existed 6 months ago.
A guy in Karachi rebuilt GPT-4 in one Jupyter notebook.
OpenAI spent over $100 million to train the real one. He put the entire recipe on GitHub for free.
His README still says "I am looking for a PhD position in AI."
It's called Train LLM From Scratch. A working guide that walks you through building your own 2-billion-parameter language model on a single GPU.
OpenAI vs this repo:
- Training cost: $100M+ → Single A100 or RTX 4090 (you can rent for $1/hr)
- Code access: Closed → Open, MIT license
- Data: Secret → The Pile (open dataset, 825GB)
- Walkthrough: None → Every line of code explained, top to bottom
- Output quality: GPT-4 → A small model that writes broken English (but it's yours)
The whole thing fits in one notebook. No paid course. No paywall. No "Pro" tier.
What you actually learn:
→ How a transformer works, end to end
→ How to download and tokenize the Pile dataset
→ How to build multi-head attention from scratch in PyTorch
→ How to train on a single GPU without running out of memory
→ How to generate text from your trained model
→ How to scale from 13 million parameters to 2 billion
774 stars. 135 forks. MIT license. The full theory paper-to-code in one place.
One honest note: this is a learning repo, not a production model. Your output will be small and rough. But you will understand exactly how GPT-4 works after reading it.
Fareed Khan built this from Karachi, Pakistan. He has 1,780 GitHub followers. He's still looking for a PhD position. The recipe to billion-dollar AI is sitting on his profile, free.
This is what open AI was supposed to mean.
(Link in the comments)
Let me tell you about a tool that turns any codebase into an interactive knowledge graph you can explore, search, and ask questions about.
It's called Understand Anything.
Here's what actually happens when you run it:
Six agents analyze your project in parallel. A knowledge graph gets built of every file, function, class, and dependency. An interactive dashboard opens, color-coded by architectural layer, fully searchable, every node clickable with plain-English explanations.
Then you get:
→ /understand-chat - ask anything about the codebase in plain English
→ /understand-diff - see what your changes affect before committing
→ /understand-explain - deep dive into any specific file or function
→ /understand-onboard - generate an onboarding guide for new team members
→ /understand-domain - extract business domain knowledge as a horizontal graph
→ /understand-knowledge - analyze a wiki and surface implicit relationships as a navigable idea graph
The persona-adaptive UI is a detail I hadn't seen before, the dashboard adjusts its detail level depending on whether you're a junior dev, PM, or power user.
It supports multilingual output too. Run /understand --language zh and the entire dashboard generates in Chinese.
It works with Claude Code, Cursor, Copilot, Gemini CLI, Codex, OpenCode, Vibe CLI, Cline, KIMI CLI.
Here's the GitHub Repo: https://t.co/J1cN92k7rj
This leaked quant research paper is the exact 12-step methodology hedge funds use before every trade
Every step
Every formula
Full Python code
Pass it to Claude and you have a working Polymarket system tonight
Full breakdown in the article below
andrej karpathy spent two hours teaching one thing: tokens are the atom of llms. tokenization is at the heart of every llm weirdness you've ever debugged.
[watch the 15-min clip below. then run the 7-day playbook]
↓ save this before everyone copies it
learn how the tokenizer works. understand how your llm actually consumes input. then run the engineering roadmap that took one production agent from $4,800/mo to $620/mo in 7 days.
87% reduction. no model swap. no framework migration. no quality drop on the eval set.
token cost in 2026 is an engineering discipline. every line of your system prompt is rent you pay forever.
what was eating the budget:
→ a single forgotten cron job ate 47% of one team's bill. they turned it off on a tuesday and the bill dropped before they wrote any optimization code.
→ anthropic ships a 90% discount on cache reads. one config line, cache_control ephemeral, break-even after one hit. most teams cache the volatile parts of the prompt and watch their hit rate sit at 12%.
→ one production agent went from 14,500 tokens of context overhead per turn to 850. a 94% drop. output quality held within 2% of the uncompressed baseline.
→ 60% of agent calls are haiku-tier work running on opus rates. classify the task first. pick the model second.
→ retry loops are the silent killer. no MAX_STEPS bound, one bad search query, $14 burned in a single session. one team traced 38% of their bill to this single pattern.
karpathy gave you the atom. the playbook below gives you the harness.
watch the lecture. read the playbook ↓
Claude Code feels completely different once you install this.
Anthropic quietly released an official plugin called claude-code-setup and it basically turns Claude Code from “pretty good” into an actual AI dev environment.
It scans your project and recommends:
→ hooks
→ skills
→ MCP servers
→ subagents
→ automations
Then sets everything up step-by-step for you.
Most people are using Claude Code completely vanilla…
which is why their experience feels messy.
The real power comes from the ecosystem around it.
Install:
/plugin install claude-code-setup@claude-plugins-official
Bookmark this before you forget it.
the engineer who built Claude Code just dropped a 28-minute video on how to write prompts that actually work
I've seen $300 courses that don't cover what he shows in the first 10 minutes
CLAUDE.md files, memory shortcuts, parallel sessions, prompting patterns
all in one video and completely free
works whether you're a developer, a beginner, or someone who's been using Claude for months
based on this, I put together 18 things you can copy and use in Claude today
full guide in the article below
GitHub - affaan-m/everything-claude-code: The agent harness performance optimization system. Skills, instincts, memory, security, and research-first development for Claude Code, Codex, Opencode, Cursor and beyond. · GitHub https://t.co/g6vOlhWxjv
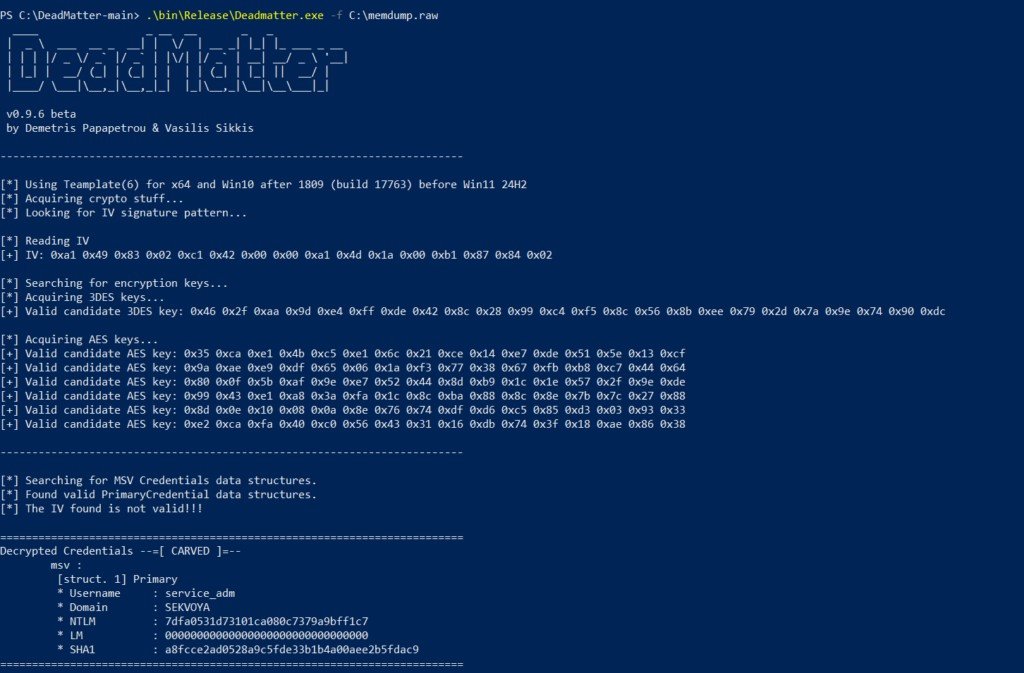
DeadMatter
Extracts LSASS credentials from memory dumps. Lightweight. Can be used to bypass AV/EDR. Usually is paired with DumpIt as both of them don't need GUI.
Tested with Microsoft Defender and Kaspersky
https://t.co/phV5wNPfBZ
@three_cube@_aircorridor#edr#apt #redteam
MSSQLHound runtime is down from 17 minutes to 17 seconds in my lab after rewriting the BloodHound collector in Go with Javier Azofra and added SOCKS proxying, Kerberos and NT hash auth, and pathfinding. Hope this is more useful for ops than PowerShell! Let me know how it goes!
Mozilla says Mythos helped identify 271 vulnerabilities in Firefox 150.
I went through the commits, CVEs, and bug links to see what that number really means.
My takeaway: relax folks.
https://t.co/9LEqL7sXX6
Researchers from the University of California San Diego and the University of Maryland spent three years scanning traffic from 39 GEO satellites visible from California.
Their analysis showed that roughly half of the observed signals carried cleartext IP traffic. The recovered traffic covered an extraordinary range of sectors.
They observed voice calls, SMS messages, in-flight passenger Wi-Fi traffic, utility infrastructure communications, oil and gas platform data, corporate internal messages, retail inventory records, ATM networking data and even military and law-enforcement communications.
In our article we covered their research, showing you the hardware and software they used.
https://t.co/jZL2cX8ym4