Huge! Real-world agentic leaderboard from Arena.
Instead of synthetic benchmarks, it measures how models actually perform when real users put them to work - writing code, debugging projects, researching the web, building apps, analyzing documents.
The methodology is different from anything else out there. Arena uses causal tracing - treating each model as a randomized controlled trial across millions of live sessions. Every session produces signals from two sources: the user (praise, complaints, corrections, task approval) and the environment (shell errors, tool failures, recovery attempts).
Five signals measured: task success, praise vs complaint, steerability, bash error recovery, and tool hallucination. Each has its own leaderboard, and there is also an overall one.
The scale behind this: 300K+ tasks, 2M+ tool calls, 40M lines of code written by agents in a single week.
Current leaderboard:
1. GPT-5.5 (High)
2. Claude Opus 4.7 (Thinking)
3. GLM-5.1
4. Gemini-3.1-Pro
5. Kimi-K2.6
I've shared the full methodology blog in the replies!
Google just dropped Gemma 4 12B!
You can now run it locally on just 8GB RAM using Dynamic GGUF from Unsloth.
The architecture is different from any multimodal model before it. No separate vision encoder, no audio encoder. Both flow directly into the LLM backbone. Vision is handled by a lightweight embedding module - a single matrix multiplication. Audio is projected directly into the same space as text tokens.
This is also the first mid-sized Gemma model with native audio input. Text, images, and audio all handled natively in one model running on your laptop.
Key details:
• Encoder-free architecture: vision and audio inputs flow directly into the LLM
• Text, image, and audio support in one unified model
• Runs on 8GB RAM (4-bit) or 14GB (8-bit)
• 256K context window
• 140+ languages support
• Performance nearing the larger 26B MoE model
• Multi-Token Prediction drafters built in to reduce latency
• Thinking mode with explicit enable/disable control
• Apache 2.0 license
I've shared the Unsloth guide to run it locally in the replies!
AI Engineering Toolkit!
I have curated a list of 100+ libraries and frameworks for training, fine-tuning, building, evaluating and deploying LLMs, RAG, and AI Agents.
Categories of LLM Libraries include:
• Vector Databases – Store and retrieve embeddings efficiently.
• Orchestration & Workflows – Chain tools and LLM calls, manage pipelines.
• Agent Frameworks – Build autonomous and multi-step agents.
• Training & Fine-Tuning – Pretrain, fine-tune, and adapt models.
• Inference & Serving – Run LLMs efficiently on diverse hardware.
• Safety & Security – Guardrails, red-teaming, and policy checks.
• Evaluation & Quality – Test and monitor both LLMs and LLM-powered apps (benchmarks, unit tests, telemetry, feedback).
• Model Management – Versioning, experiment tracking, lineage, and lifecycle management.
• AI App Development – Build UIs and LLM-powered apps quickly with Python-based frameworks.
Link to the repo in the comments!
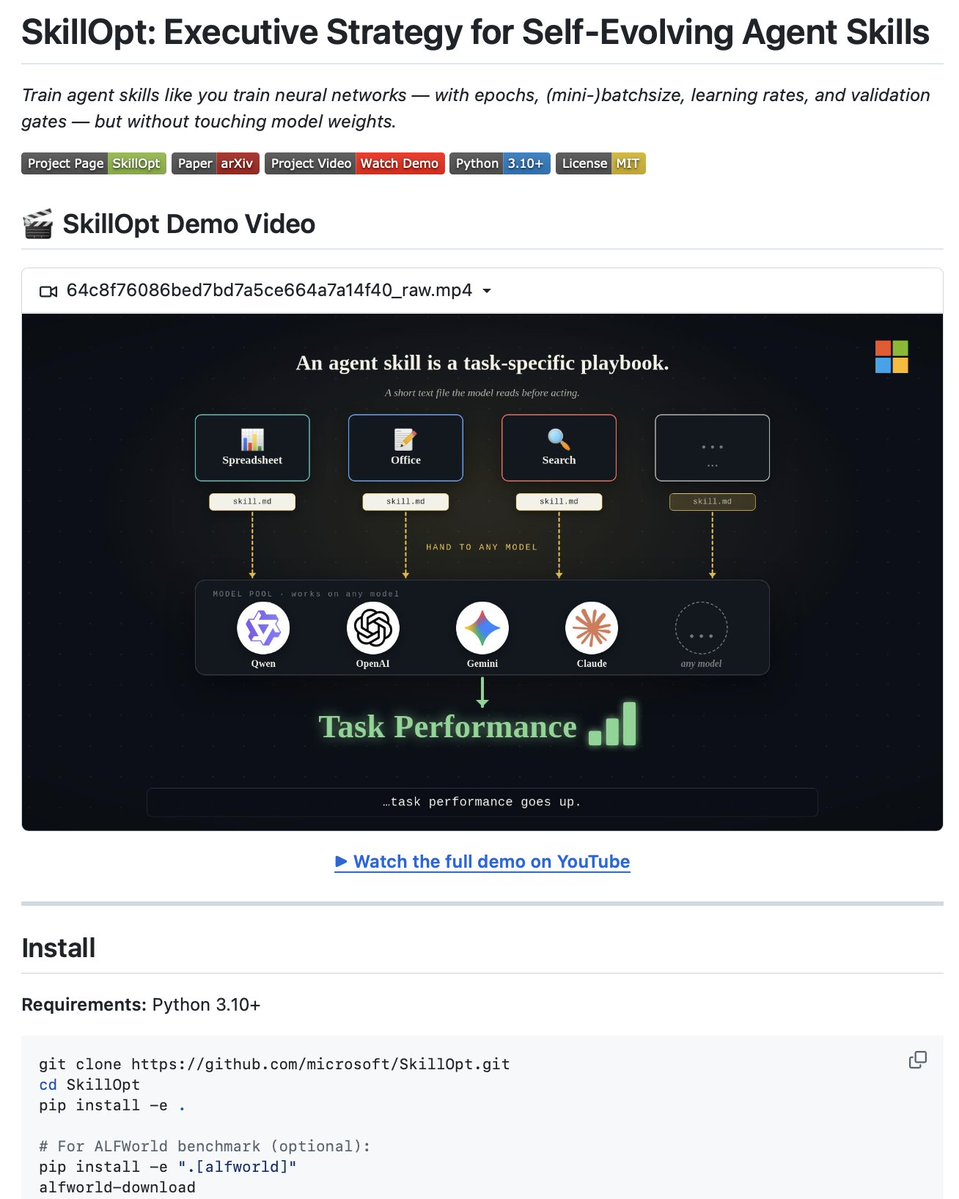
Microsoft just turned SKILL .md into a trainable object!
SkillOpt is a text-space optimizer for agent skills. Instead of hand-writing or one-shot generating your SKILL .md, SkillOpt treats the skill document as the trainable external state of a frozen agent and optimizes it through a feedback loop.
The core idea: a separate optimizer model analyzes agent rollout trajectories, proposes bounded add/delete/replace edits to the skill document, and accepts only edits that strictly improve performance on a held-out validation split. Rejected edits go into a buffer as negative feedback for future iterations.
The deep learning analogy is intentional. Rollout batch is your training data. Edit budget is your learning rate. Validation gate is your validation set. Rejected-edit buffer is your negative feedback signal. The optimizer runs offline. The deployed artifact is just a static SKILL .md file.
Results on GPT-5.5 across 6 benchmarks: +23.5 points average over no-skill baseline in direct chat, +24.8 inside Codex, +19.1 inside Claude Code. SpreadsheetBench jumped from 41.8 to 80.7. OfficeQA from 33.1 to 72.1. Best or tied-best on 52 of 52 evaluated cells.
What's striking: these gains come from just 1-4 accepted edits. The final skill stays compact at 300-2000 tokens. One accepted edit gave OfficeQA a +39 point gain.
Optimized skills also transfer. A SpreadsheetBench skill trained in Codex transferred to Claude Code with a +59.7 point gain. Skills trained on GPT-5.4 improved every smaller GPT variant tested.
Key capabilities:
• Text-space skill optimization with no model weight updates
• Bounded add/delete/replace edits with validation gating
• Rejected-edit buffer as negative feedback
• Epoch-wise slow/meta update for longer-horizon learning
• Works across Claude Code, Codex, and direct chat harnesses
• Optimized skills transfer across models, harnesses, and benchmarks
100% Open Source
I've shared the link to the paper and repo in the comments!
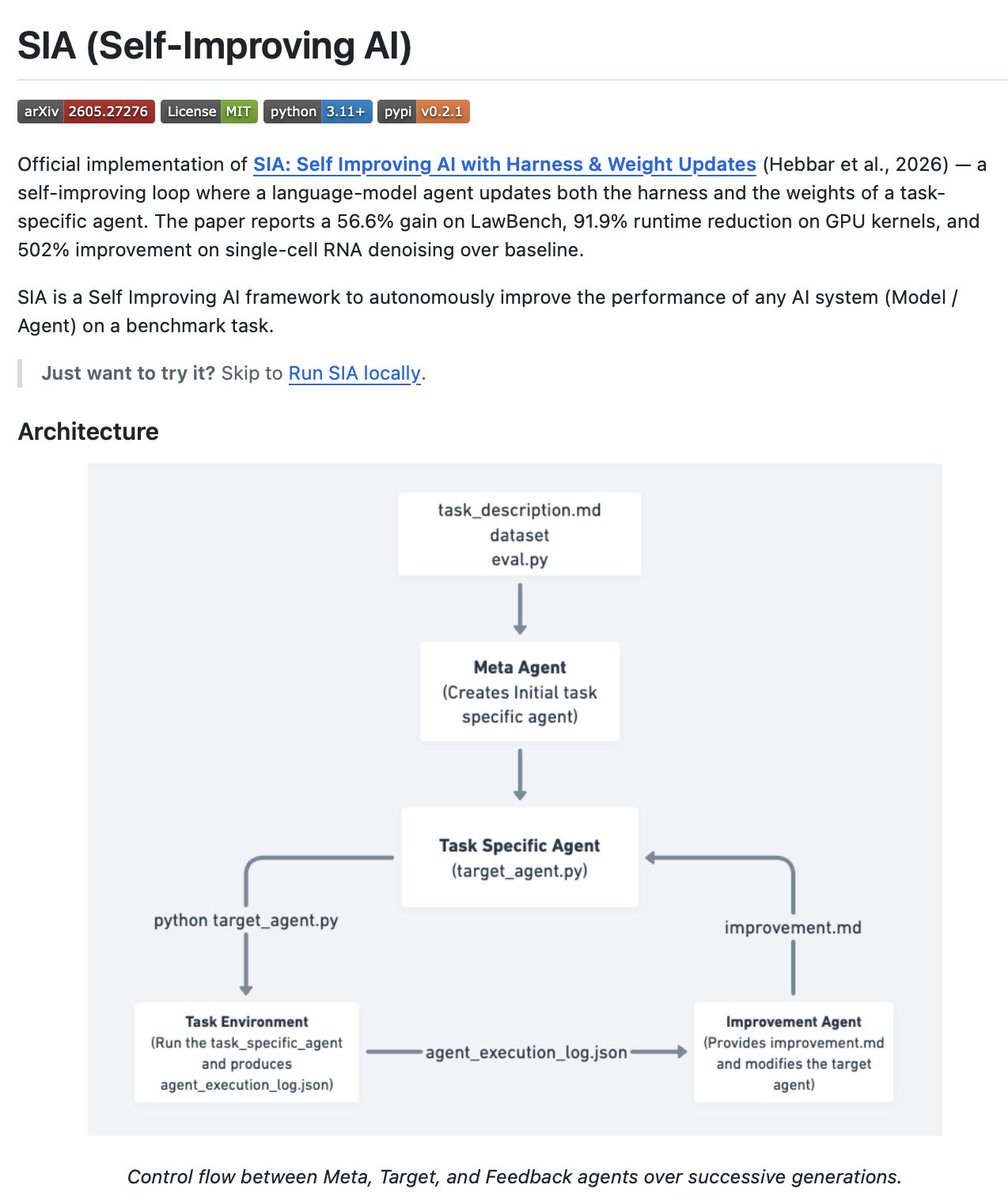
Self Improving AI (SIA) beats Karpathy's autoresearcher agent by improving itself!
SIA is a Self Improving AI framework to autonomously improve the performance of any AI system (Model / Agent) on a benchmark task.
Most agent frameworks are static. Fixed harness, fixed model weights, fixed memory layer. They plan, act, and use tools. SIA operates on a different layer entirely.
SIA focuses on one problem: how do you design structured feedback loops that allow an agent to evaluate its own performance, adapt its strategy, and get better over time?
After every run, SIA evaluates itself and improves three things. It updates its own harness. Updates the weights of its underlying model. Updates its own memory layer to handle new complexities. The agent rewrites itself based on what it learned.
On MLE-Bench, OpenAI's benchmark for evaluating an agent's ability to train ML models, SIA climbed to the top of the leaderboard. Beat every specialized ML research agent including MLEvolve and AIRA-dojo. Then kept improving and displaced its own previous versions on the leaderboard.
I've shared the link to the paper and the repo in the replies!
Run your personal AI company with a team of AI agents!
Alook is an open-source collaboration platform for AI coding agents. Self-hosted and local-first.
The setup: Define an org structure. Give each agent a role - dev, ops, research, whatever you need. Set reporting lines. Alook gives each agent an email address.
How it works: Assign a task to the right agent. They take it from there. Agents coordinate through email - passing deliverables, asking questions, updating status. You see everything in your inbox but you're not routing anything manually.
Runs as an always-on daemon. Close your laptop, agents keep working. Come back to finished tasks.
Shared memory across all agents. Every agent knows what every other agent worked on. You never re-explain context. After each task completes, Alook logs what worked and builds SOPs. The whole team gets sharper over time.
Works with Claude Code, Codex, and OpenCode. Mix and match or run multiple agents from one runtime.
Built-in Kanban for task tracking. Calendar for scheduling. Email for all communication. Agents pick up tasks autonomously, update their own calendars, close issues when done.
Chat or email with agents like any AI tool. Install the runtime once, runs in the background. No terminal needed after setup.
Key capabilities:
• Email-based agent coordination with real inboxes
• Org structure with roles and reporting lines
• Shared memory and self-learning SOPs
• Always-on daemon for 24/7 operation
• Works with Claude Code, Codex, OpenCode
• Built-in Kanban, calendar, and email
• Self-hosted and local-first
100% open source.
I've shared the Github Repo in the replies!
Turn any GUI app into a CLI for AI agents!
CLI-Anything automatically generates command-line interfaces for any software by analyzing its codebase. Point it at GIMP, Blender, LibreOffice, or any application and get a production-ready CLI that AI agents can use.
The problem: AI agents can't use professional software. These tools have GUIs, not command interfaces. UI automation breaks constantly. APIs don't exist or miss 90% of functionality. Building custom CLIs manually takes months.
CLI-Anything runs as a Claude Code plugin. You call `/cli-anything ./gimp` and it analyzes the codebase, designs command architecture, implements the full CLI, writes comprehensive tests, and publishes everything as a pip-installable package.
The generated CLIs call the actual software backends. Blender renders 3D scenes, LibreOffice generates PDFs, Zoom schedules meetings.
How it works depends on what the software provides. Tools with REST APIs get wrapped with OAuth handling. Tools with Python scripting get script generators. Tools with documented file formats get file creators plus rendering calls.
Each CLI works the same way for agents. Commands return structured JSON. REPL mode for interactive use. pip-installable to PATH. Comprehensive tests included.
Tested across 16 diverse applications: GIMP, Blender, Inkscape, Audacity, LibreOffice, OBS Studio, Kdenlive, Shotcut, Zoom, Mermaid, ComfyUI, Ollama. 1,839 passing tests with 100% pass rate.
Key capabilities:
• Automated CLI generation from any codebase
• Calls actual software backends (no replacements)
• Multiple integration approaches (APIs, scripting, file formats)
• Production-ready with comprehensive tests
• pip-installable with JSON output for agents
• REPL mode for interactive use
Built as Claude Code plugin. Works with OpenCode, Codex, OpenClaw, Qodercli.
I've shared the link to the repo in the comments!
Turn any document into structured data for AI agents!
Firecrawl just released a new parse endpoint. Upload local files or non-public documents and get back clean, LLM-ready data.
The parse endpoint converts PDF, DOCX, XLSX, HTML, and other formats into Markdown, JSON, or structured output. Reading order and tables are preserved.
Upload a file via multipart/form-data. The endpoint processes it using a Rust-based engine (up to 5x faster) and returns your chosen format.
Key capabilities:
• Multiple output formats: Markdown, JSON, HTML, summaries, extracted links, or metadata
• Preserves document structure, reading order, and tables
• Extracts metadata automatically (title, description, language)
• Zero data retention option (document not logged or stored)
• Content filtering via includeTags and excludeTags
Built for AI agent pipelines that need clean document data at scale.
I've shared the link in the comments!
Stop guessing which models fit in your VRAM!
llmfit is a CLI tool that auto-detects your hardware and ranks 206 models by what actually runs on your system.
You download a 70B model and hope it fits. Or you estimate memory requirements across quantization levels and still end up with models that crash or run too slow.
llmfit changes that. It detects your CPU, RAM, GPU, and VRAM, then scores every model in its database against your hardware.
Instead of assuming one quantization level, it tries the best quality that fits. Starts with Q8_0, walks down to Q2_K if needed. If nothing fits at full context, it tries half context. You get the highest quality model that actually works.
Each model gets scored on Quality, Speed, Context, and Capability. The weights shift based on what you're doing. Chat models prioritize speed, reasoning models prioritize quality.
Run it as an interactive TUI to browse models, use CLI mode for a quick table, or get JSON output for scripts. There's a REST API for cluster schedulers.
You can also run it in reverse. Give it a model you want to run and target performance, it tells you what hardware you need.
The real value: you see ranked options before downloading anything. No more burning bandwidth on 50GB models that won't run.
It's 100% open source.
Link to llmfit in comments!