If you are asking “Why push back against anti-datacenter efforts?” I consider it a tragedy that anti-nuclear efforts largely strangled nuclear power in the US based on vibes, and I don’t want to see that happen to AI. Public opinion matters, and it shouldn’t be ceded unchallenged.
If you are asking “Why should I support AI efforts at all?” I believe we are in the midst of a transition more vibrant than the industrial revolution. Opinions formed a couple of years ago about the uselessness of AI are no longer valid. Millions of people and organizations are getting great returns from using it, and the demand for data centers is the market responding to the value signal. That is how progress is made!
@dom_gag_96@italianbldrs Acceleration hub for Italian companies/startup which are raising capital. Give exposure to founders which match specific characteristics (innovation, relevance, targets, ….), increasing opportunities to gather funding or attract talent
AGENTS dot md files don't scale beyond modest codebases.
Lots of discussions on this lately.
If you're building serious software with Claude Code or any agentic tool, a single AGENTS dot md will eventually fail you. This paper shows what comes next.
A 1,000-line prototype can be fully described in a single prompt. A 100,000-line system cannot. The AI must be told, repeatedly and reliably, how the project works, what patterns to follow, and what mistakes to avoid.
Single-file manifests hit a ceiling fast.
This new paper, Codified Context, documents a three-tier infrastructure built during real development of a 108,000-line C# distributed system across 283 sessions over 70 days.
The system uses a three-tier memory architecture: a hot-memory constitution (660 lines, always loaded), 19 specialized domain-expert agents (9,300 lines total) invoked per task, and a cold-memory knowledge base of 34 specification documents (~16,250 lines) queried on demand via an MCP retrieval server.
Across 283 sessions, this produced 2,801 human prompts, 1,197 agent invocations, and 16,522 autonomous agent turns, roughly 6 autonomous turns per human prompt, with a knowledge-to-code ratio of 24.2%.
Crucially, none of it was designed upfront: each new agent and specification emerged from a real failure, a recurring bug, an architectural mistake, a convention forgotten, and was codified so it could never require re-explanation again, turning documentation into load-bearing infrastructure that agents depend on as memory, not reference.
Paper: https://t.co/ZXBzhhkzsq
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Software development is undergoing a renaissance in front of our eyes.
If you haven't used the tools recently, you likely are underestimating what you're missing. Since December, there's been a step function improvement in what tools like Codex can do. Some great engineers at OpenAI yesterday told me that their job has fundamentally changed since December. Prior to then, they could use Codex for unit tests; now it writes essentially all the code and does a great deal of their operations and debugging. Not everyone has yet made that leap, but it's usually because of factors besides the capability of the model.
Every company faces the same opportunity now, and navigating it well — just like with cloud computing or the Internet — requires careful thought. This post shares how OpenAI is currently approaching retooling our teams towards agentic software development. We're still learning and iterating, but here's how we're thinking about it right now:
As a first step, by March 31st, we're aiming that:
(1) For any technical task, the tool of first resort for humans is interacting with an agent rather than using an editor or terminal.
(2) The default way humans utilize agents is explicitly evaluated as safe, but also productive enough that most workflows do not need additional permissions.
In order to get there, here's what we recommended to the team a few weeks ago:
1. Take the time to try out the tools. The tools do sell themselves — many people have had amazing experiences with 5.2 in Codex, after having churned from codex web a few months ago. But many people are also so busy they haven't had a chance to try Codex yet or got stuck thinking "is there any way it could do X" rather than just trying.
- Designate an "agents captain" for your team — the primary person responsible for thinking about how agents can be brought into the teams' workflow.
- Share experiences or questions in a few designated internal channels
- Take a day for a company-wide Codex hackathon
2. Create skills and AGENTS[.md].
- Create and maintain an AGENTS[.md] for any project you work on; update the AGENTS[.md] whenever the agent does something wrong or struggles with a task.
- Write skills for anything that you get Codex to do, and commit it to the skills directory in a shared repository
3. Inventory and make accessible any internal tools.
- Maintain a list of tools that your team relies on, and make sure someone takes point on making it agent-accessible (such as via a CLI or MCP server).
4. Structure codebases to be agent-first. With the models changing so fast, this is still somewhat untrodden ground, and will require some exploration.
- Write tests which are quick to run, and create high-quality interfaces between components.
5. Say no to slop. Managing AI generated code at scale is an emerging problem, and will require new processes and conventions to keep code quality high
- Ensure that some human is accountable for any code that gets merged. As a code reviewer, maintain at least the same bar as you would for human-written code, and make sure the author understands what they're submitting.
6. Work on basic infra. There's a lot of room for everyone to build basic infrastructure, which can be guided by internal user feedback. The core tools are getting a lot better and more usable, but there's a lot of infrastructure that currently go around the tools, such as observability, tracking not just the committed code but the agent trajectories that led to them, and central management of the tools that agents are able to use.
Overall, adopting tools like Codex is not just a technical but also a deep cultural change, with a lot of downstream implications to figure out. We encourage every manager to drive this with their team, and to think through other action items — for example, per item 5 above, what else can prevent a lot of "functionally-correct but poorly-maintainable code" from creeping into codebases.
New Engineering blog: We tasked Opus 4.6 using agent teams to build a C compiler. Then we (mostly) walked away. Two weeks later, it worked on the Linux kernel.
Here's what it taught us about the future of autonomous software development.
Read more: https://t.co/htX0wl4wIf
@karpathy How to measure the impact of this on a team SDLC? There must be a good combination of metrics for productivity (eg. Numbers of weekly PR, time from concept to shop in prod), quality (eg. Mean time between failure/bug discovery..) and engineer team happiness.
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
What the Trump Admin is telling you.
-Don't record ICE
-Don't carry a gun around ICE
-Don't ask ICE for a warrant.
So that takes out the 1st, 2nd, and 4th Amendments.
I just spoke with the White House after another horrific shooting by federal agents this morning. Minnesota has had it. This is sickening.
The President must end this operation. Pull the thousands of violent, untrained officers out of Minnesota. Now.
BREAKING: A witness who was just 5 feet from Alex Pretti filed an affidavit depicting what she saw.
She says he didn’t touch any of the officers and didn’t appear to be resisting. He was merely helping a woman who had been pepper-sprayed.
She’s is terrified that ICE is looking for her, saying they are lying and she doesn’t know what they will do to her if they find her.
Il cellulare alzato, le spinte, i 10 colpi in 5 secondi: cosa racconta il video dell’uccisione di Pretti | Cosa succede a Minneapolis https://t.co/62GeLg7xoN
A new developer workflow and app paradigm is emerging, with an agentic execution loop at the core.
With the GitHub Copilot SDK, you can embed the same production-tested runtime behind Copilot CLI—multi-model, multi-step planning, tools, MCP integration, auth, streaming—directly into your apps. https://t.co/RamJvw2U9D
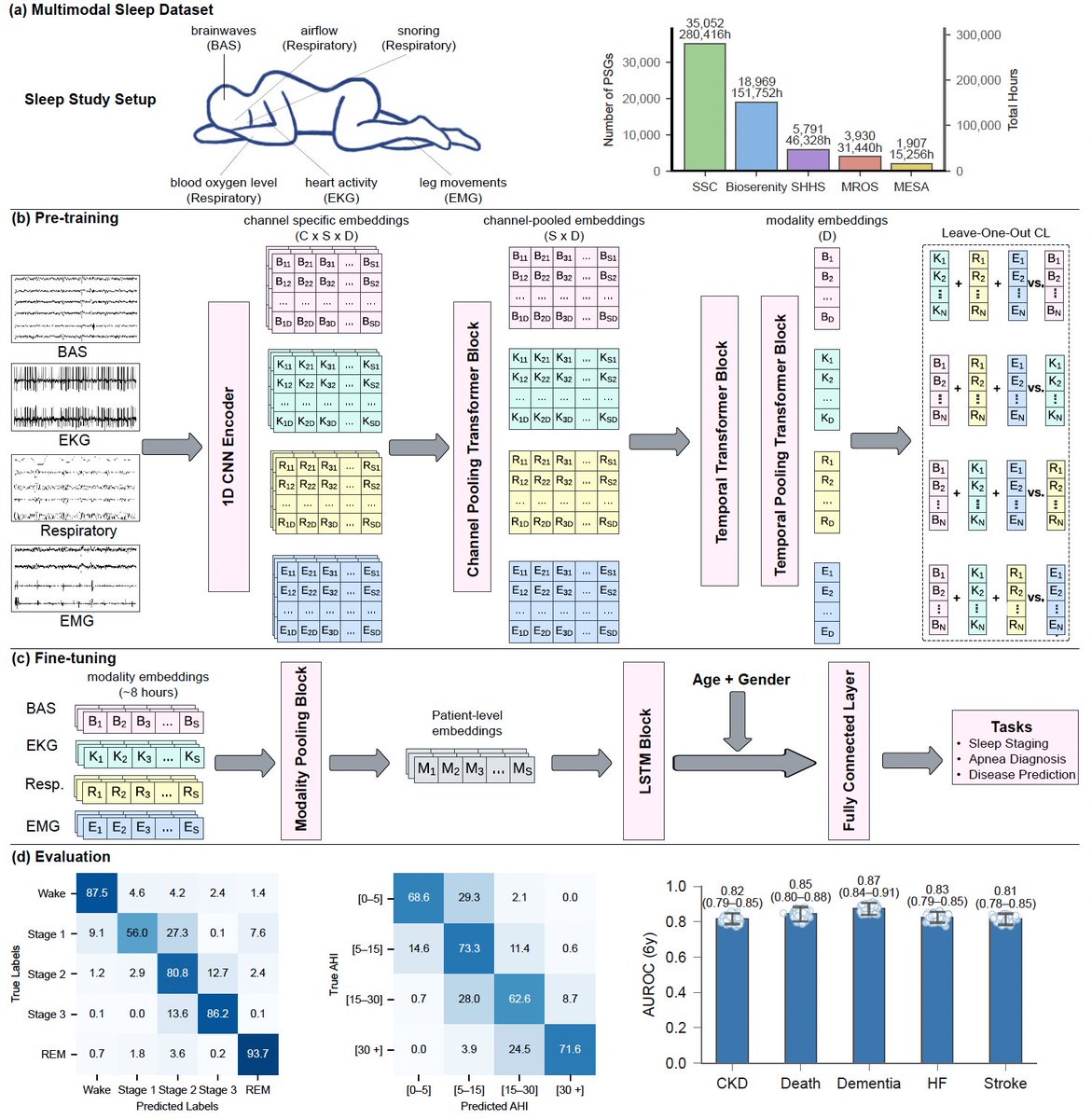
Today in @NatureMedicine we report that AI can predict 130 diseases from 1 night of sleep🛌
We trained a foundation model (#SleepFM) on 585K hours of sleep recordings from 65K people—brain, heart, muscle & breathing signals combined.
AI learns the language of sleep🧵
Sharing an interesting recent conversation on AI's impact on the economy.
AI has been compared to various historical precedents: electricity, industrial revolution, etc., I think the strongest analogy is that of AI as a new computing paradigm (Software 2.0) because both are fundamentally about the automation of digital information processing.
If you were to forecast the impact of computing on the job market in ~1980s, the most predictive feature of a task/job you'd look at is to what extent the algorithm of it is fixed, i.e. are you just mechanically transforming information according to rote, easy to specify rules (e.g. typing, bookkeeping, human calculators, etc.)? Back then, this was the class of programs that the computing capability of that era allowed us to write (by hand, manually).
With AI now, we are able to write new programs that we could never hope to write by hand before. We do it by specifying objectives (e.g. classification accuracy, reward functions), and we search the program space via gradient descent to find neural networks that work well against that objective. This is my Software 2.0 blog post from a while ago. In this new programming paradigm then, the new most predictive feature to look at is verifiability. If a task/job is verifiable, then it is optimizable directly or via reinforcement learning, and a neural net can be trained to work extremely well. It's about to what extent an AI can "practice" something. The environment has to be resettable (you can start a new attempt), efficient (a lot attempts can be made), and rewardable (there is some automated process to reward any specific attempt that was made).
The more a task/job is verifiable, the more amenable it is to automation in the new programming paradigm. If it is not verifiable, it has to fall out from neural net magic of generalization fingers crossed, or via weaker means like imitation. This is what's driving the "jagged" frontier of progress in LLMs. Tasks that are verifiable progress rapidly, including possibly beyond the ability of top experts (e.g. math, code, amount of time spent watching videos, anything that looks like puzzles with correct answers), while many others lag by comparison (creative, strategic, tasks that combine real-world knowledge, state, context and common sense).
Software 1.0 easily automates what you can specify.
Software 2.0 easily automates what you can verify.