Been thinking about this for a while, as tasks go to more and more turns and longer horizons, PPO is much more elegant for giving dense, per-turn reward. And here we go.
This paper prompted me to do a review of NVFP4 pre-training, given that NVIDIA seems to be pushing support for it especially on Blackwells.
Much of the content will come from "Pretraining Large Language Models with NVFP4" and the Nemotron 3 Super paper 🧵
The main highlight is that NVIDIA did NVFP4 pretraining. Much of the recipe follows previous Nemotron work:
- Hadamard Transforms applied to weight gradient computation to reduce the impact of outliers.
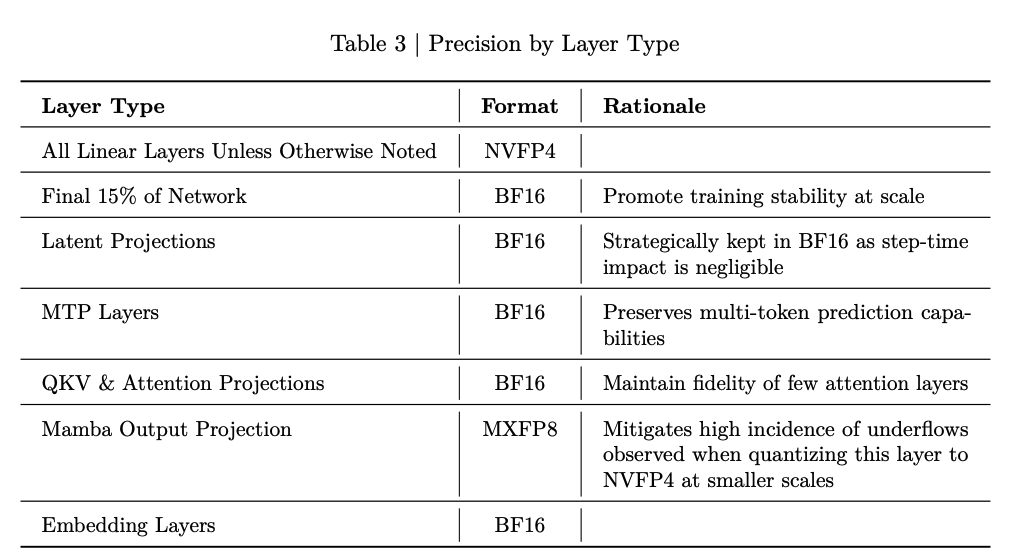
- Some layers kept at higher precision. (Table from Nemotron 3 Super). Specifically, final layers tend to require more dynamic range and mantissa than FP4 provides.
- Stochastic rounding rather than deterministic rounding to prevent bias, specifically in the gradients.
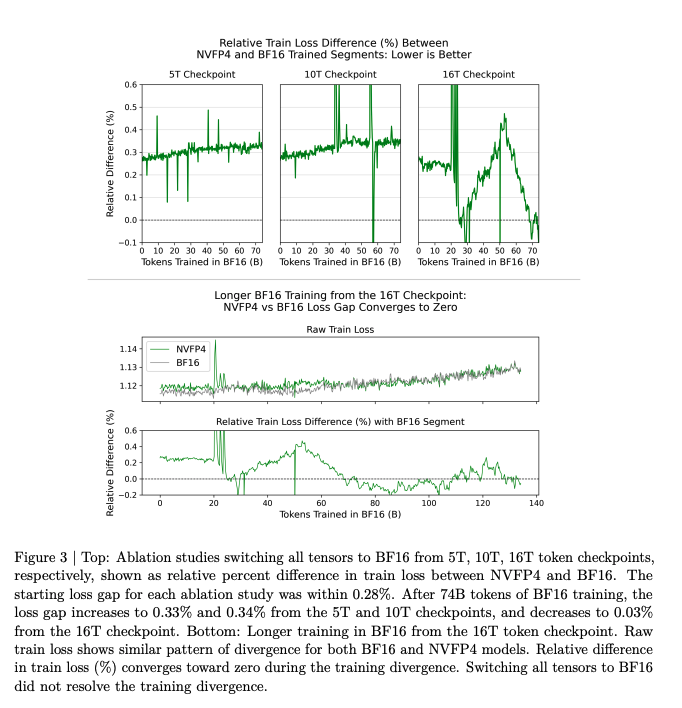
To validate the recipe, they train smaller models up to 16T and show a mere ~0.4% relative train loss gap with the bf16 baseline.
See more: https://t.co/XwBLFEg7QV
(we discuss other stability issues in later sections)