Caltech's Computational Biology group used Cedana to automatically orchestrate AI and HPC workloads to deliver results ~2x faster and slash costs by ~80%.
This is the power of automated GPU workload migration.
https://t.co/AVan0BhTla
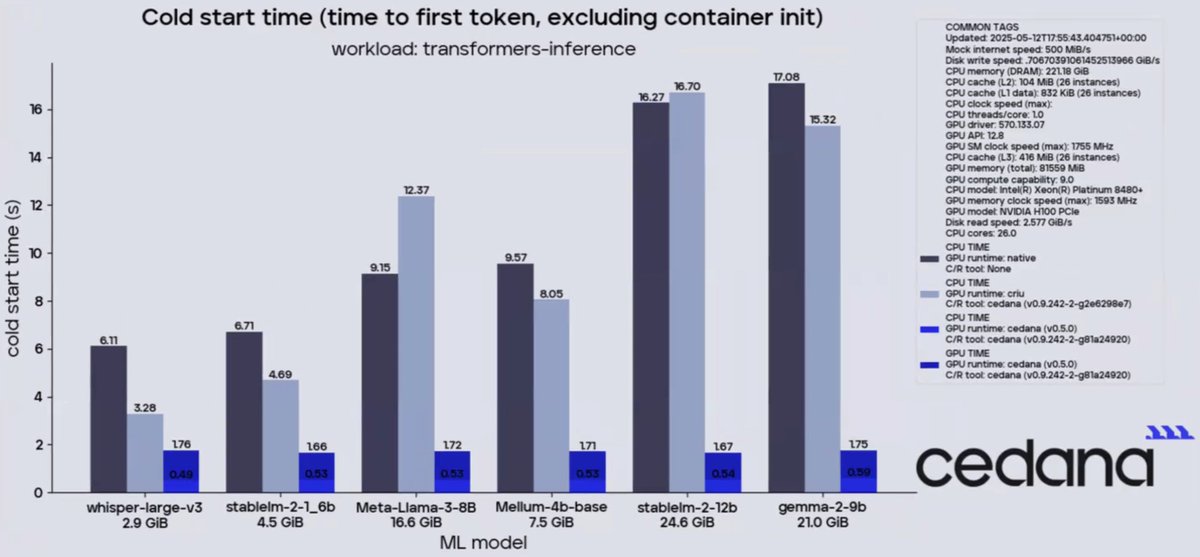
YC startup Cedana enables play/stop/rewind on all GPU and CPU compute - the result is 10x faster time to first token. Training jobs automatically resume from failures.
Caltech's computational biology team just saved 80% on compute by deploying Cedana 🤯
Cedana supercharges AI and HPC workloads with live migration of your GPU and CPU workloads. We automatically migrate jobs to optimize SLAs including performance, reliability, cost, and latency.
We seamless integrate with K8s, SLURM, Kubeflow, Kueue and Ray.
Cedana automatically migrates your GPU/CPU workloads when spot instances get revoked or catastrophic failure.
✅ 2-10x faster inference cold starts
✅ Save up to 80% on compute costs
✅ Fault-tolerant, higher throughput agents
✅ Zero code changes
https://t.co/H1R9025m9K