Use LLMs like companies do.
Don’t rely on one model for everything.
Small LLMs → fast, cheap, great for simple tasks
Large LLMs → powerful, better for complex reasoning
That’s how you scale AI without scaling cost.
#AI#LLM#Engineering#Startup
How do containers on different host talk to each other ?
Using Kubernetes as a case study:
An overlay network in Kubernetes makes containers on different machines behave like they are on the same network, handling IP addresses and communication automatically.
A race condition happens when
Multiple processes try to modify the same data at the same time, and the system doesn’t control access properly.
Good systems make sure only one operation wins safely.
Slow tasks shouldn’t block your API.
That’s where BullMQ comes in.
Instead of doing heavy work during a
request:
User request → Queue → Worker → Job done
Perfect for: • Emails • Image processing • Notifications • Background jobs
Fast APIs. Reliable processing.
@AbhiCodes15 Node—Takes incoming requests—Sends requests to endpoint- frees up main thread- handles next user—Event loop sends result back—response is returned—Node never blocks
@Jessseglee No lies cash flow problems have killed lots of potential businesses.
It’s even surprising to know that the rapid growth all startups pray for is a cause of cash flow problems 🤣. If not manage well Ofcourse.
console.log Pro Max.
That’s basically what Pino is for Node.js.
Fast. Structured. Production-ready.
JSON logs. Log levels. Minimal overhead.
When your app grows, console.log isn’t enough.
Real systems need real logging.
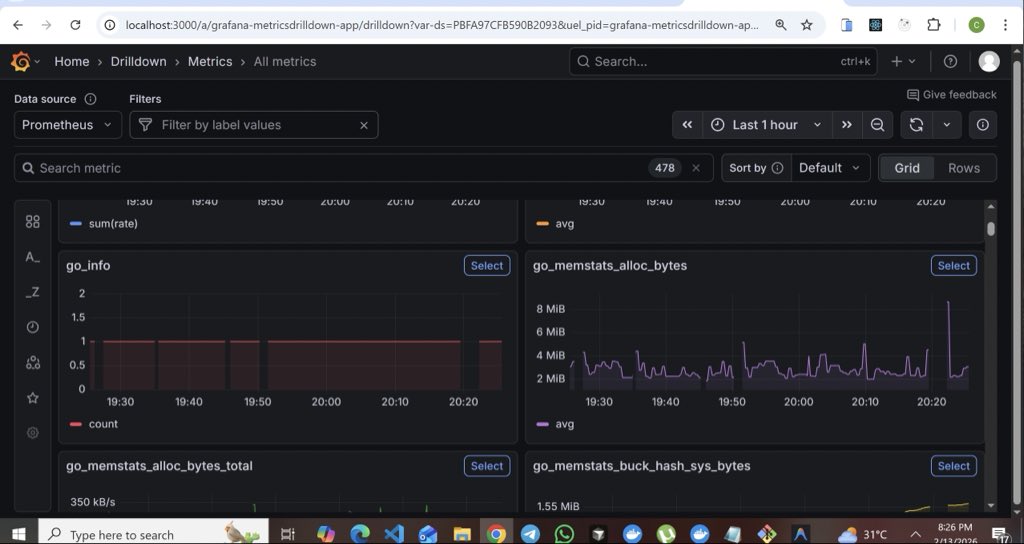
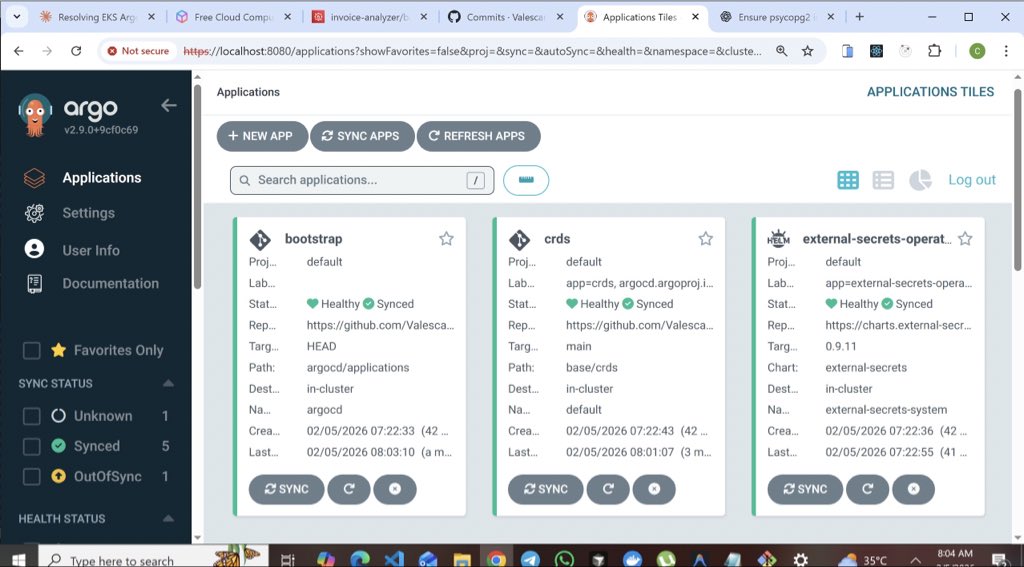
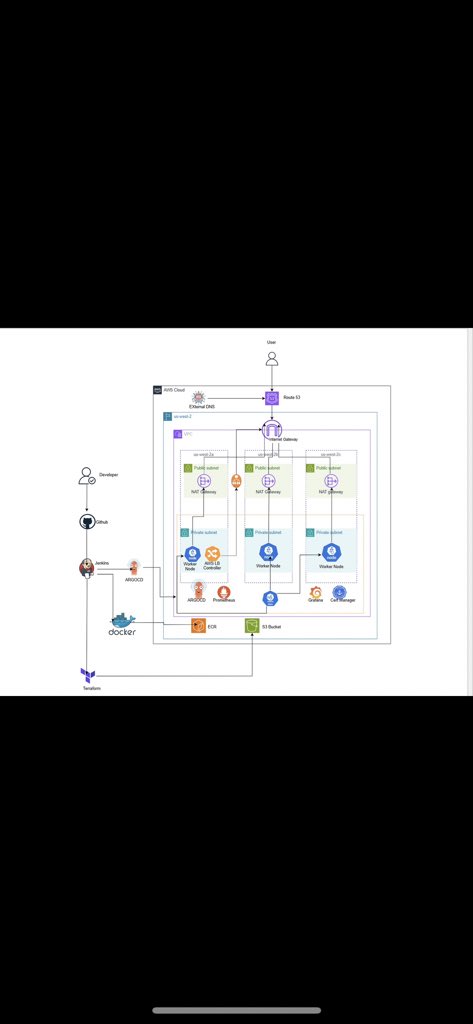
Built a production-ready Kubernetes platform on Amazon Web Services.
• EKS + Terraform (multi-AZ, modular IaC) • GitOps with Argo CD • CI/CD via Jenkins + Trivy • ALB Ingress + Route53 + HTTPS • IRSA for least-privilege pod access • Prometheus + Grafana observability
Added a killer model to my workflow: Gemini 3.1 Pro.
Here’s how I’m using its new features:
• Massive context → drop in large files/ docs without splitting
• Stronger reasoning → better multi-step debugging
• Longer outputs → full refactors + structured reports in one go