If Hantavirus mutated into a global threat, it would unleash AI + biotech unlike anything we've ever seen.
> genome sequenced and public in 4 hours
> AlphaFold maps every protein target
> AI screens 10,000 drugs in 24 hrs
> 50 vaccine candidates designed simultaneously
> AI designed antibodies in days
> risk of death computed instantly
> decentralized trials launch globally
> enroll from home
> 20 countries manufacturing at once
> first doses in three weeks
> real-time dose characterization
> your genome + biomarkers determine your protocol
> variant map updates every hour
No one would wait for governments.
Ambition since childhood: become the world's best hacker.
Met Wilma Emanuelsson yesterday.
Wilma is such an impressive human being.
Started hacking at 7, finding exploits while playing MovieStarPlanet.
Turned hacktivist as a teenager. Went after child exploitation and trafficking rings.
Founded iTrack Reading before that. Software for people with dyslexia. Look at a word, hear it in your headphones. The idea came from a friend who kept getting held back in school.
Now running her next company, Ezteric.
She's 22.
Big claim in this paper. "Prefill-as-a-Service"
Prefill, the heaviest part of inference, may finally be portable.
Long-context AI is no longer trapped inside a single datacenter.
Shows how to run LLM prefill on remote clusters by sending much smaller saved prompt state. So long-prompt work can be done on remote machines and sending back only the smaller saved state needed to answer.
The breakthrough is not sending everything farther, but sending the right requests farther.
---
When you ask a model a long question, it first has to read and digest the whole prompt before it starts answering.
That first step is called prefill, and it is brutally compute-heavy.
The second step is decode, where the model generates tokens one by one, and that part is more about memory bandwidth than raw compute.
But moving the saved prompt state between those phases is usually so data-heavy that both parts must stay in the same tightly connected cluster.
So Until now, those two steps usually had to stay close together inside the same fast network, because prefill creates a huge blob of temporary memory called KVCache that had to be moved quickly to the decode machine.
That is the bottleneck.
What changed is model design.
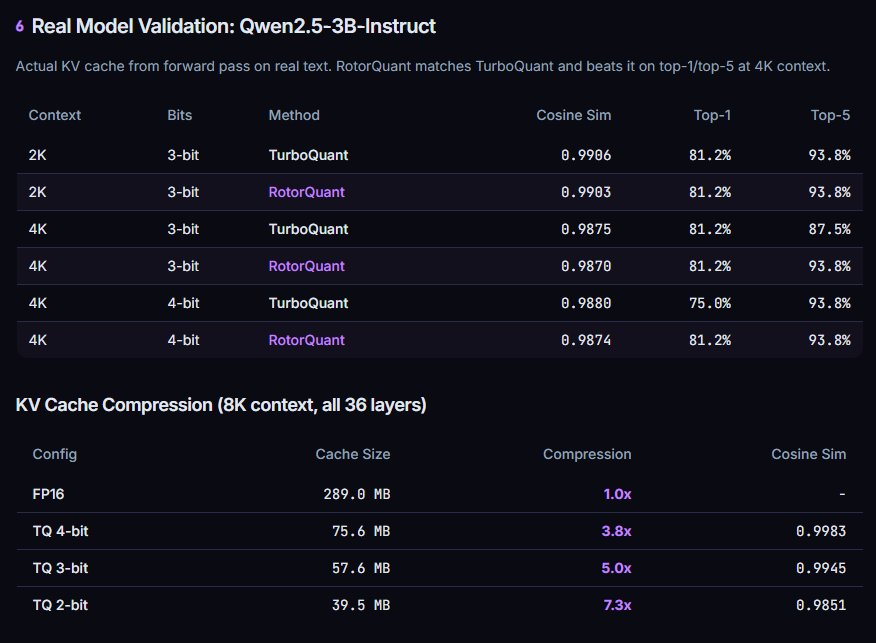
Newer hybrid-attention models produce much smaller KVCache than older dense-attention models, so shipping that state across ordinary datacenter links starts to become practical instead of absurd.
The paper’s idea is a Prefill-as-a-Service setup that sends only long, uncached prompts to a remote prefill cluster, then ships back the saved prompt state, called KV cache, over normal Ethernet while short requests stay local.
This works mainly because newer hybrid-attention models create far less KV cache than older dense models, and the system adds smart routing, bandwidth-aware scheduling, and cache-aware placement so the network does not clog up.
The authors test this with an internal 1T-parameter hybrid model on a mixed setup that uses H200 GPUs for remote prefill and H20 GPUs for local decode.
With a routing threshold near 19.4K tokens, about 50% of requests go remote, average cross-cluster traffic is only 13Gbps on a 100Gbps link, and throughput rises 54% over a local-only baseline and 32% over a naive heterogeneous setup.
The real point is that smaller KV cache alone was not enough, but paired with selective offloading and scheduling it makes cross-datacenter LLM serving workable, more flexible, and easier to scale across different hardware.
----
Paper Link – arxiv. org/abs/2604.15039v1
Paper Title: "Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter"
Features i am working on:
> Drag and drop components from different papers and build a novel model.
> Generate the code for that in real time
> Ask questions about the reasoning about your idea.
Currently building a new tool that I would personally find quite useful.
Its an interactive machine learning tool. Its main feature would be so it can help you visualize a model in a research paper, manipulate it and generate code to test it yourself.
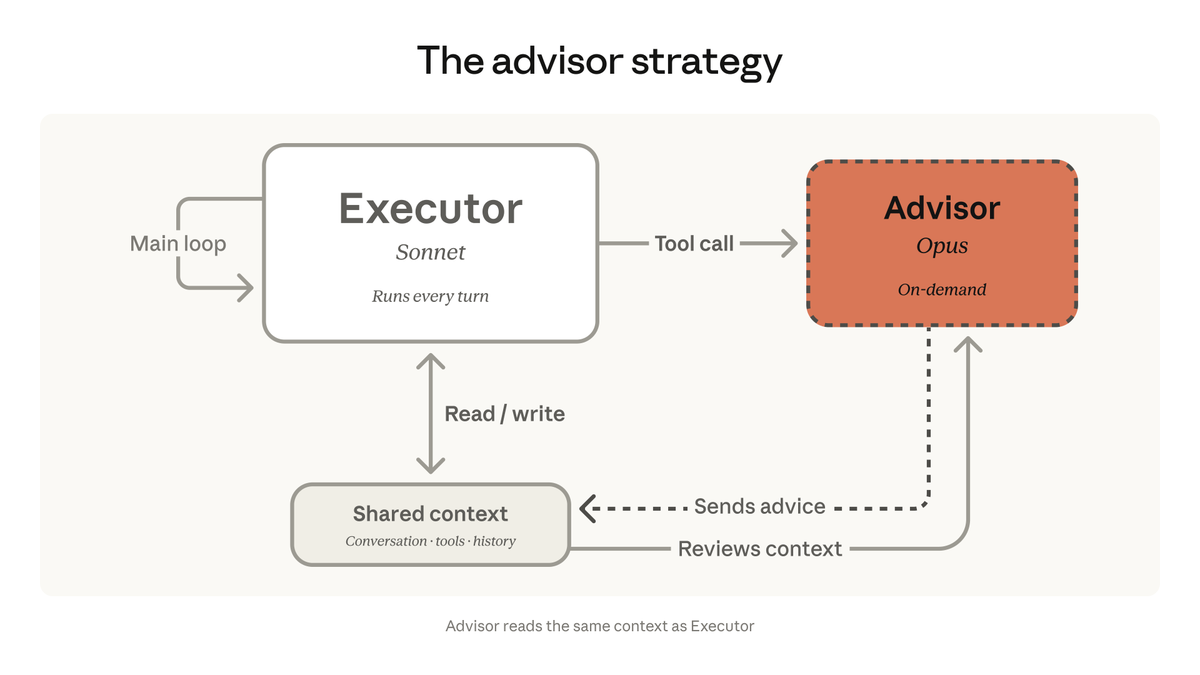
We're bringing the advisor strategy to the Claude Platform.
Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost.
Tried to use ForgeCode's Forge Harness yesterday night, ran into a bunch or errors regarding the database being full and crashed out hard.
Anyone know how to fix this? @forgecodehq
Be anthroptic
>give your ai researchers a crap ton of caffeine and ask them to build a SOTA model
>Use this model to accelerate product development
>Keep it hidden from the public since Feb 2024
>Leak it so everyone knows whats coming
>Drop the model and generate crazy hype
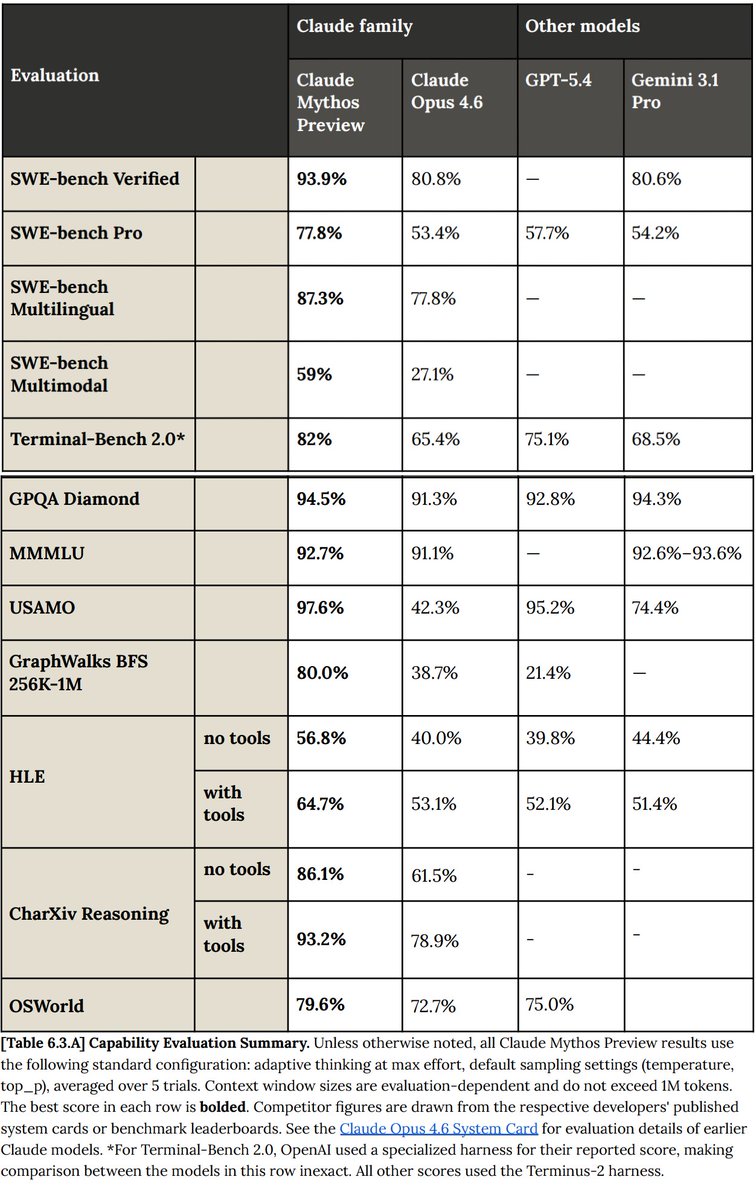
🚨 Anthropic just revealed their unreleased frontier model called Claude Mythos Preview
The model is INSANE
It found thousands of zero-day vulnerabilities in EVERY major operating system and browsers:
> 27-year-old bug in OpenBSD
> 16-year-old bug in FFmpeg that automated tools hit 5M times without catching
Completely autonomous. No human steering.
They assembled an entire industry coalition called Project Glasswing around it:
AWS, Apple, Google, Microsoft, NVIDIA, CrowdStrike, JPMorgan, Cisco, Palo Alto, Linux Foundation
Goal: patch the world’s software BEFORE releasing it
> SWE-bench: 93.9% (Opus 4.6: 80.8%)
> Anthropic is committing $100M in usage credits
> Thousands of vulnerabilities in 40+ organizations are being fixed right now
Yesterday OpenAI published a 13-page essay warning about cyber threats and asking the government to help…
Today Anthropic actually fixed them.