Why do we assume an RL agent can always compute the correct action immediately? Every policy is a program and thus resource bounded. In this blog, I argue why computation should be part of decision making, illustrated with some toy examples.
🔗https://t.co/tBBRc6K0CX
@danielwurgaft This loss/complexity tradeoff has started bothering me---I think we can be okay with (slightly) worse loss at the cost of better generalization, e.g. physics models will fail to predict noise but memorization can. Any thoughts about this, e.g. regularization, architecture, etc.?
@puneeshdeora@bhavya_vasudeva Great work! Our work https://t.co/iH72TWaifl shows that asymptotically ICL will choose the best prediction mode, but we didn't address anything about which is preferred when they're equally good---do you think it has to do with k=1 converging faster than k=3 in the MC case?
@Stone_Tao There are few but this is what I have on my mind: https://t.co/Yb34TOdGJ7
I think with smaller buffer size the data gets closer to on policy data, and larger -> more off policy
Meet the recipients of the 2024 ACM A.M. Turing Award, Andrew G. Barto and Richard S. Sutton! They are recognized for developing the conceptual and algorithmic foundations of reinforcement learning. Please join us in congratulating the two recipients! https://t.co/GrDfgzW1fL
LLMs can leverage context information, i.e., in-context learning (ICL) or memorize solutions, i.e., in-weight learning (IWL) for prediction, but when do they happen? 1/N
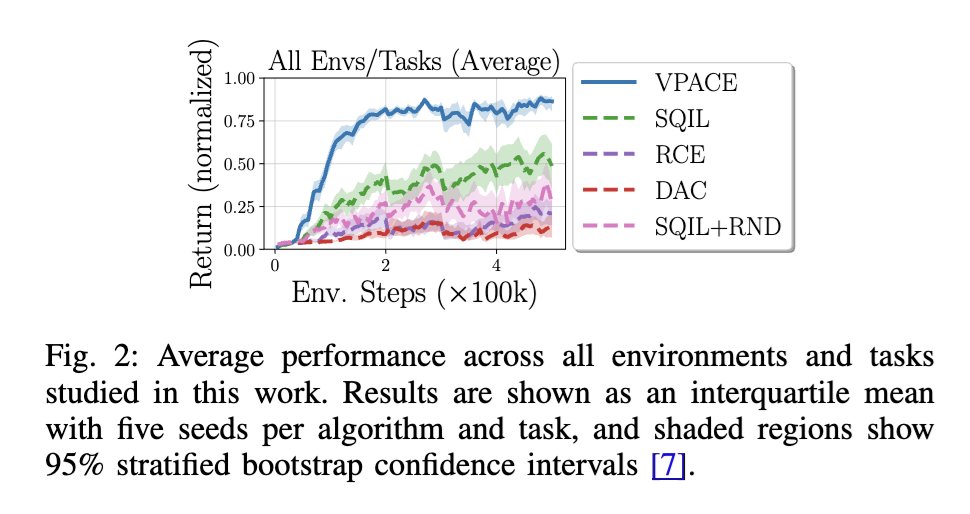
Thanks @m_wulfmeier ! We were surprised to see that SAC-X is just very robust. Something that was interesting to us that we didn’t further investigate: Learning from examples ended up being more efficient than using reward. Let’s chat at #NeurIPS2024 if there’s a chance?
Here's a fascinating paper by @domo_mr_roboto's group linking hierarchical reinforcement learning and cheaply-obtainable auxiliary tasks https://t.co/dhVVA9gLDv
Better exploration with minimal engineering effort remains a critical challenge (even for RLHF/AIF) - reminiscent of our efforts on SAC-X and intrinsic rewards through representation learning (VAE, Transporter, etc.) https://t.co/zt9OjxcmTz
Excited to see more progress in this space!
#robotics #reinforcementlearning
@anianruoss One immediate observation I have is that there seems to be no boundary between two demonstration sequence (list. 1). Would it not be problematic because the model can’t tell they are different demonstrations without further training?
@daibond_alpha@iclr_conf 3. Both scores 3 and 5 are somewhat due to experimental results like significance and benchmarks.
(3) is interesting because former provides no empirical insight, while latter provides some, arguably claiming "maybe" the theory applies. Which one is more important/contribution?
@daibond_alpha@iclr_conf Some interesting observations here:
1. It seems like the latter has "shorter reviews" and imo generally of lower quality than those of the former
2. The expectations seem to be different, maybe due to different primary areas?
3. ...
Would you believe that deep RL can work without replay buffers, target networks, or batch updates? Our recent work gets deep RL agents to learn from a continuous stream of data one sample at a time without storing any sample. Joint work with @Gautham529 and @rupammahmood.
Our NeurIPS paper is now on arXiv:
We introduce Action Value Gradient (AVG), a novel incremental deep RL method that learns in real-time, one sample at a time — no batch updates, target networks or a replay buffer!
Co-authors @mhmd_elsaye@bellingerc@white_martha@rupammahmood
@c_voelcker@usmananwar391 What alternative are you using? I think I can see some limitations with the IQM approach but unsure what you think to address it
Hey all! We are thrilled to have @chanpyb from @UAlberta for this week's seminar! The talk is titled: "Why can't we use reinforcement learning for
image-based robotic manipulation?". See you at 11:30AM ET!
https://t.co/vki05SSZgx
#rl#manipulation, #imitationLearning