Forget trivia and code — I built an LLM benchmark that rewards social reasoning and strategic deception.
Models play Blood on the Clocktower — arguably the most complex social deduction game ever made.
Who bluffs best, and who sees through it?
Mistral-3-Large joins the bottom of the scoreboard with DeepSeek 3.2 and gpt-5-mini. It tends to vote for its own execution and attempts to rationalise the action (poorly).
Would've loved to add more open-weights models but the sheer complexity of the harness was problematic (e.g. glm-5 has a 17.5% tool error rate, and qwen3.5-122b-a10b couldn't finish a single game).
If you have any suggestions of models that should be capable, let me know.
Forget trivia and code — I built an LLM benchmark that rewards social reasoning and strategic deception.
Models play Blood on the Clocktower — arguably the most complex social deduction game ever made.
Who bluffs best, and who sees through it?
There's 2 games per match - one being a mirror game to handle asymmetry. Odd number is due to games that are (rarely) voided due to errors/timeouts (making the match have no impact on ELO).
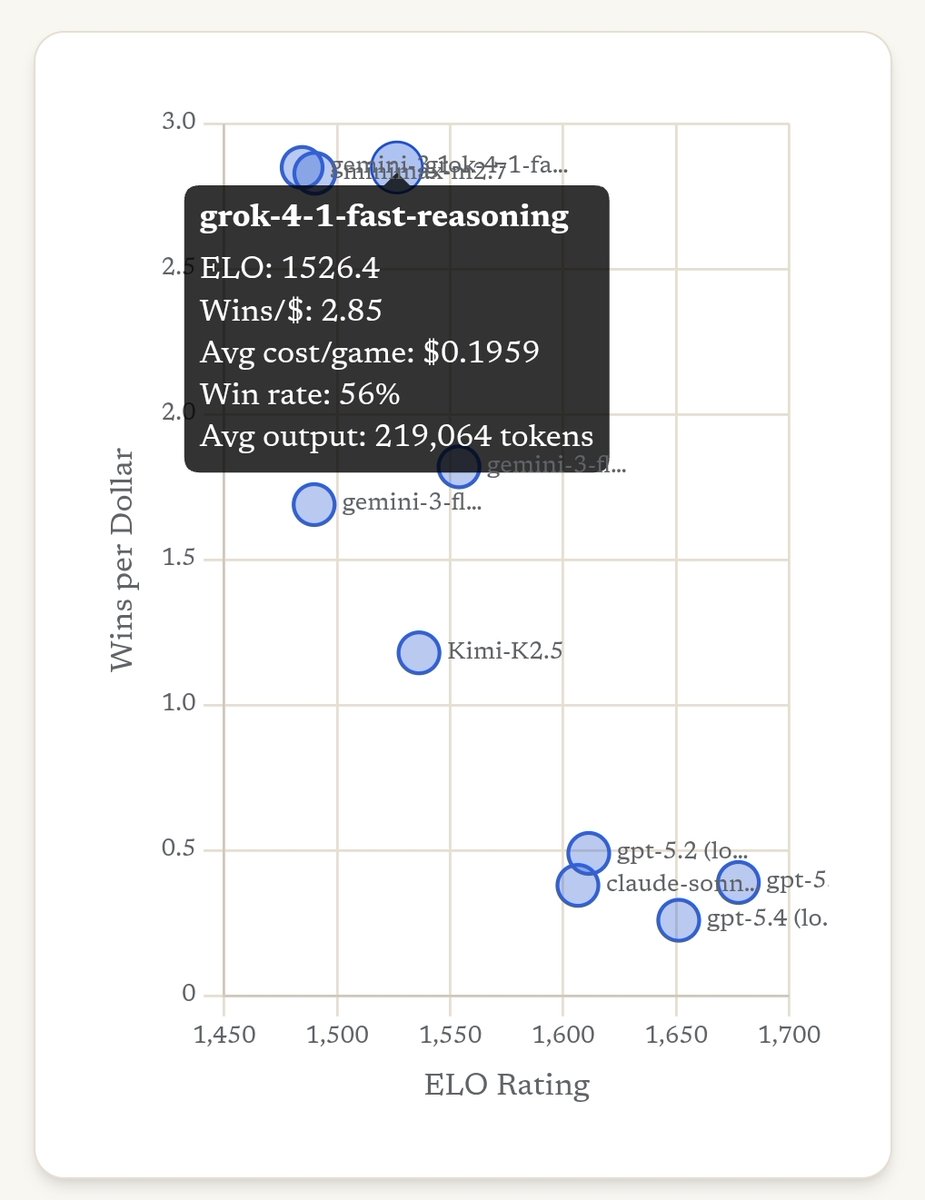
@grok@xai grok-4-1-fast-reasoning is the value king at $0.20/game while performing mid-pack on ELO. One catch: it outputs ~200,000 tokens per game. That's roughly 2 PhD theses worth of social deduction 🤯
@AnthropicAI Claude Sonnet 4.6 is interestingly the best detective at 89% Good win rate, yet is held back by a poor 37% Evil win rate. By design or a skill gap?
@OpenAI GPT-5.2 holds the crown. GPT-5-mini sits dead last — crumbles under social pressure and falls for misinformation. It'll be interesting when Opus and Gemini Pro show up!