"You can run OpenClaw inside your company now." Annoucing our work with @Microsoft to bring OpenClaw to the Microsoft and Windows ecosystems. Claws now work securly in the enterprise.
Built a meta-skill that creates skills for my workflow. At session end, the agent summarizes when to ask me, when to fix things, and how to design output. Surprisingly agentic.
"Explain this code logic from the user's perspective." Use this simple prompt when trying to understand unfamiliar or vibe-coded code. You won't regret it.
I’ve joined the🦞@openclaw Foundation as Chief Architect! Excited to propel the future of agentic computing with @steipete and a world-class team.
In the post-claw era, AI is moving beyond coding into our personal lives. Big announcements at @nvidia Computex & @Microsoft Build!
This benchmark is nearly right. The truth is, Codex is better than Claude Code as of September 2025, at least. The strange thing is, when I said Codex is better than Claude Code this month, some people still thought I'd lost my mind.
Many developers have suspected for months that GPT-5.5 outperforms Claude Sonnet for coding. But SWE-Bench reported near-parity, and it made people question what they’d been seeing in practice.
DeepSWE aligns more closely with that day-to-day experience: GPT-5.5 scores 70% versus Claude Sonnet at 32%. That difference is substantial.
DeepSWE focuses on what tends to matter in real workflows: whether an agent can take a short behavioral prompt, locate the correct area of the codebase, and implement the change cleanly - without needing you to enumerate files, modules, and functions. SWE-Bench often fails to capture that, due to dataset contamination and weaker verification.
https://t.co/C3s80xfDkk
I attended a talk the day before yesterday where someone asked for my thoughts on multi-agent systems. I almost blurted out that they are just a pure waste of tokens. The only approach that seems useful is the one-to-many sub-agent architecture used by Claude Code.
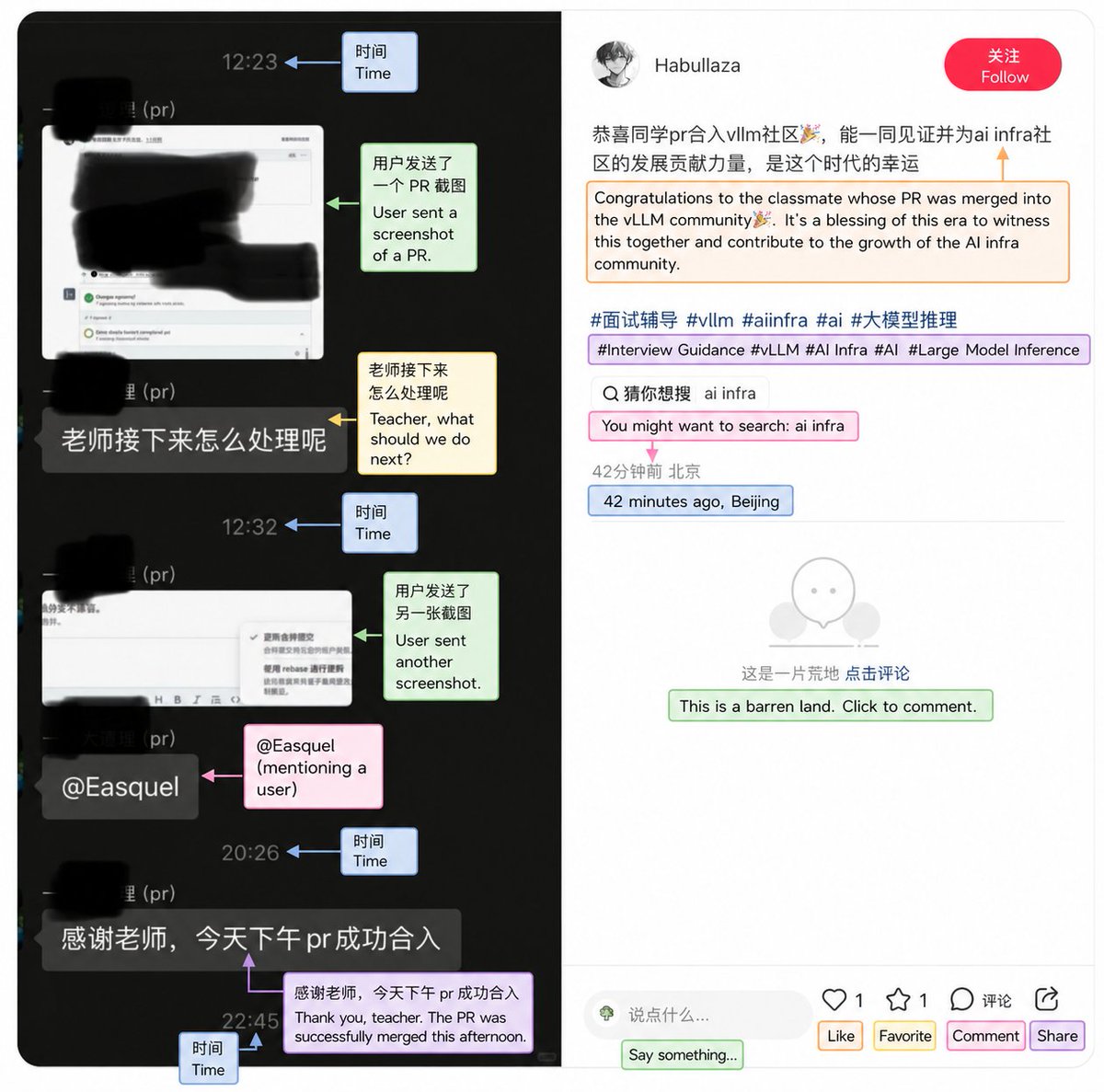
Thanks to the community report, we recently identified a PR https://t.co/QWboSmskkF that attempted to solve a non-existent issue and was submitted as part of a “PR training” workflow for resume building.
The contributor involved has been banned from the vLLM community.
This kind of low-signal contribution increases maintainer review overhead and creates unnecessary operational costs for open-source projects.
As AI coding agents make generating large volumes of small PRs increasingly cheap, open-source communities will need to explore new ways to preserve contribution quality and reviewer trust.
While we are investigating how to deal with AI slop, we continue to highly value contributions from real users solving real production problems.
If you have an important contribution that has not yet received maintainer attention, please email us at:
[email protected]
Using a verifiable company or university email, include:
- your production or research use case
- the problem you encountered
- how your contribution addresses it
This helps us better prioritize impactful contributions while keeping the vLLM community open and collaborative.
As AI makes virtual contributors look increasingly real, authentic human collaboration matters more than ever.
vLLM’s mission remains unchanged: to make LLM inference easy, fast, and cheap for everyone — and we will continue working toward that goal.