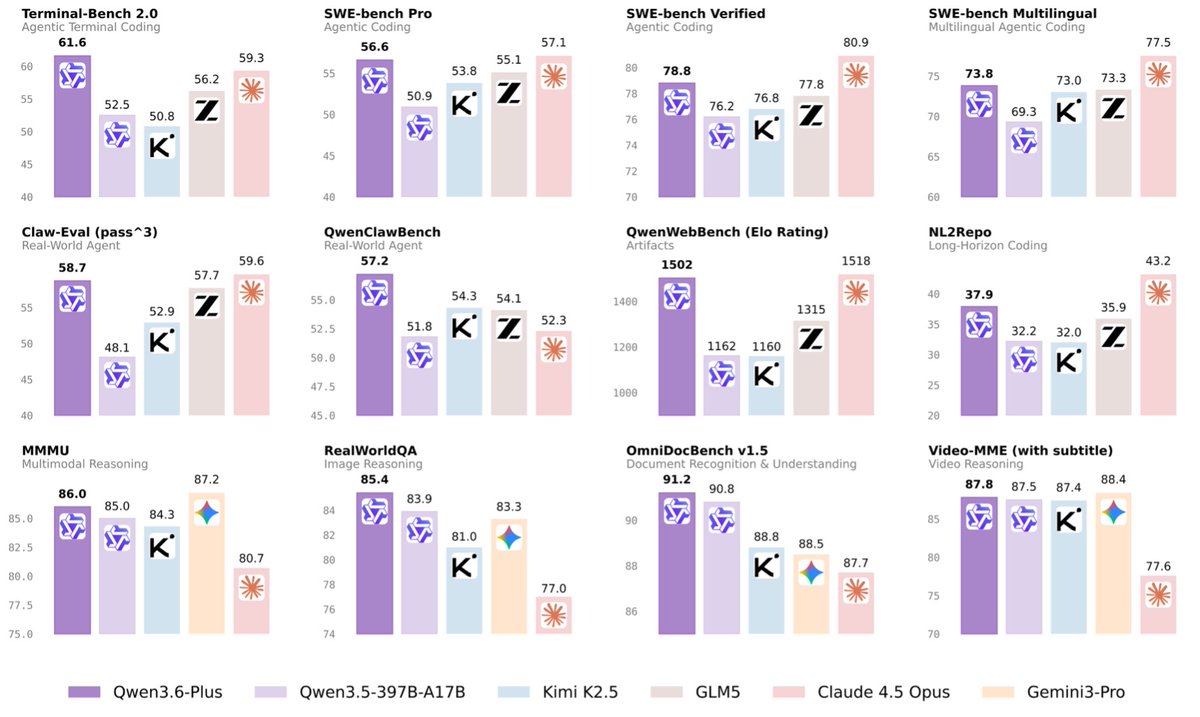
(1/8)🚀 Introducing Qwen3.6-Plus: Towards Real-World Agents! 🤖
Today, we’re thrilled to drop a major milestone in our journey toward native multimodal agents.
Here is what makes Qwen3.6-Plus a game-changer:
💻 Next-level Agentic Coding: Smarter, faster execution.
👁️ Enhanced Multimodal Vision: Sharper perception & reasoning.
🏆 Top-tier Performance: Maintaining leading general capabilities.
📚 1M Context Window: Available by default via our API.
Built on your invaluable feedback from the Qwen3.5 era, we’re laying a rock-solid foundation for real-world devs. Get ready to experience truly transformative ✨ Vibe Coding ✨.
Huge thanks to our community! Go try it out and show us what you can build. 👇
Chat: https://t.co/V7RmqMaVNZ
API: https://t.co/937Qkc9AMy
Blog: https://t.co/P0rJSxERND
🔔Noted:More Qwen3.6 models to come and be open-sourced! Stay tuned~ 👀#Qwen #AI #AgenticCoding #VibeCoding #Agents
🚀 Qwen3.5-Omni is here! Scaling up to a native omni-modal AGI.
Meet the next generation of Qwen, designed for native text, image, audio, and video understanding, with major advances in both intelligence and real-time interaction.
A standout feature: 'Audio-Visual Vibe Coding'. Describe your vision to the camera, and Qwen3.5-Omni-Plus instantly builds a functional website or game for you.
Offline Highlights:
🎬 Script-Level Captioning: Generate detailed video scripts with timestamps, scene cuts & speaker mapping.
🏆 SOTA Performance: Outperform Gemini-3.1 Pro in audio and matches its audio-visual understanding.
🧠 Massive Capacity: Natively handle up to 10h of audio or 400s of 720p video, trained on 100M+ hours of data.
🌍 Global Reach: Recognize 113 languages (speech) & speaks 36.
Real-time Features:
🎙️ Fine-Grained Voice Control: Adjust emotion, pace, and volume in real-time.
🔍 Built-in Web Search & complex function calling.
👤 Voice Cloning: Customize your AI's voice from a short sample, with engineering rollout coming soon.
💬 Human-like Conversation: Smart turn-taking that understands real intent and ignores noise.
The Qwen3.5-Omni family includes Plus, Flash, and Light variants.
Try it out:
Blog: https://t.co/yuSAz3DuO8
Realtime Interaction: click the VoiceChat/VideoChat button (bottom-right): https://t.co/nnAW9ZfRet
HF-Demo: https://t.co/rLsqejKgCG
HF-VoiceOnline-Demo: https://t.co/LIGtmITeSw
API-Offline: https://t.co/lNE7fH5YUt
API-Realtime: https://t.co/9A3lopXGwV
Exactly — the shift from reasoning to agentic thinking is real.
It’s not about thinking longer, but thinking in ways that drive action.
The benchmark era is ending; the environment era is here.
Which local models can actually handle tool calling?
I built a framework to find out.
15 scenarios. 12 tools. Mocked responses. Temperature 0. No cherry-picking.
Tested every Qwen3.5 size from 0.8B to 397B, and since some of you asked after the distillation tests: yes, I included Jackrong's Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled too.
Only two models went all green: the 27B dense and the distilled 27B.
The 397B? Failed two tests. The 122B? Failed one. The 35B? Failed two.
The timed-out results — mostly on the smaller models, are cases where the model got stuck in a loop, repeating the same tool call until it hit the 30-second limit.
The test that exposed the most models: "Search for Iceland's population, then calculate 2% of it." Simple, but 35B, 122B, and 397B all used a rounded number from memory instead of the actual search result. They didn't trust their own tool output.
Small models hallucinate data.
Big models ignore data.
The 27B just threaded it through.
Big congrats. Cursor has built an amazing product — huge reach, real brand recognition, tons of users, and a really strong feedback loop.
Pair that with strong open-source models and great agentic RL / infra partners, and I think we’ll see a lot more amazing vertical and enterprise models emerge.
Finally — yes, finally — our GPTQ-Int4 weights are here 🔥
The Qwen3.5 series maintains near-lossless accuracy under 4-bit weight and KV cache quantization. In terms of long-context efficiency:
• Qwen3.5-27B supports 800K+ context length
• Qwen3.5-35B-A3B exceeds 1M context on consumer-grade GPUs with 32GB VRAM
• Qwen3.5-122B-A10B supports 1M+ context length on server-grade GPUs with 80GB VRAM
🔥 Qwen 3.5 Series GPTQ-Int4 weights are live.
Native vLLM & SGLang support.
⚡️ Less VRAM. Faster inference.
Run powerful models on limited-GPU setups.
👇 Grab the weights + example code:
Hugging Face:
https://t.co/3MSb7miq68
ModelScope:
https://t.co/LGHruBHP6Q
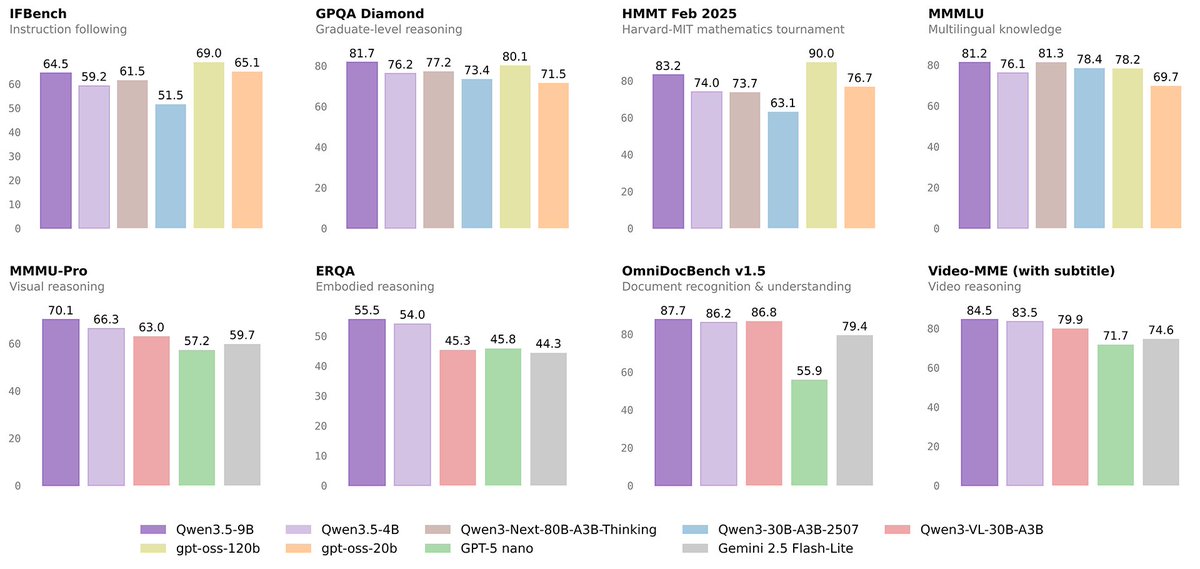
🚀 Introducing the Qwen 3.5 Small Model Series
Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B
✨ More intelligence, less compute.
These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL:
• 0.8B / 2B → tiny, fast, great for edge device
• 4B → a surprisingly strong multimodal base for lightweight agents
• 9B → compact, but already closing the gap with much larger models
And yes — we’re also releasing the Base models as well.
We hope this better supports research, experimentation, and real-world industrial innovation.
Hugging Face: https://t.co/wFMdX5pDjU
ModelScope: https://t.co/9NGXcIdCWI
With Qwen3-TTS Voice Design, you can shape tone and richness just using text.
If you want more consistency:
Generate the first segment with Voice Design, then continue with Voice Clone.
Hope you enjoy it — would love to hear the fun voice styles you come up with. 🎙️
Big moment for text-to-speech.
Qwen open-sourced a TTS model that lets you clone voices, design new ones & control speech using natural language.
You can ask it "speak in a cheerful tone with slight nervousness," and it actually does that.
No complex audio engineering needed!
Qwen 3.5 35B is now available on Venice.
Fast, efficient, and multilingual. 262K context window, multimodal input, and strong coding and agent performance — all fully private on Venice.