I ran Gemma 3 4B without PyTorch, without CUDA — just flat binary files + 600 lines of Rust.
Paris #1. Jupiter #1. Ulm #1. Exact HF match.
CPU or Vulkan GPU. Any vendor. No framework.
Built on @chrishayuk's LarQL decomposition.
https://t.co/Gc9TPxehns
#DeepLearning#GPU #MLOps #AIEngineering #RustLang #HuggingFace #Gemma #WebGPU
#CrossPlatform #EdgeAI #OpenAI #LLMInference #FOSS #IndieResearch
@chrishayuk watched your LARQL video this morning, spent the day porting it to Windows/Linux + CUDA and wrapping it in a Gradio UI — live on HF Spaces 12 hours after your release.
👉 https://t.co/yowLwXztiP
👉 https://t.co/XWDBpJuDPJ
Already running in 3 of my projects. Great work.
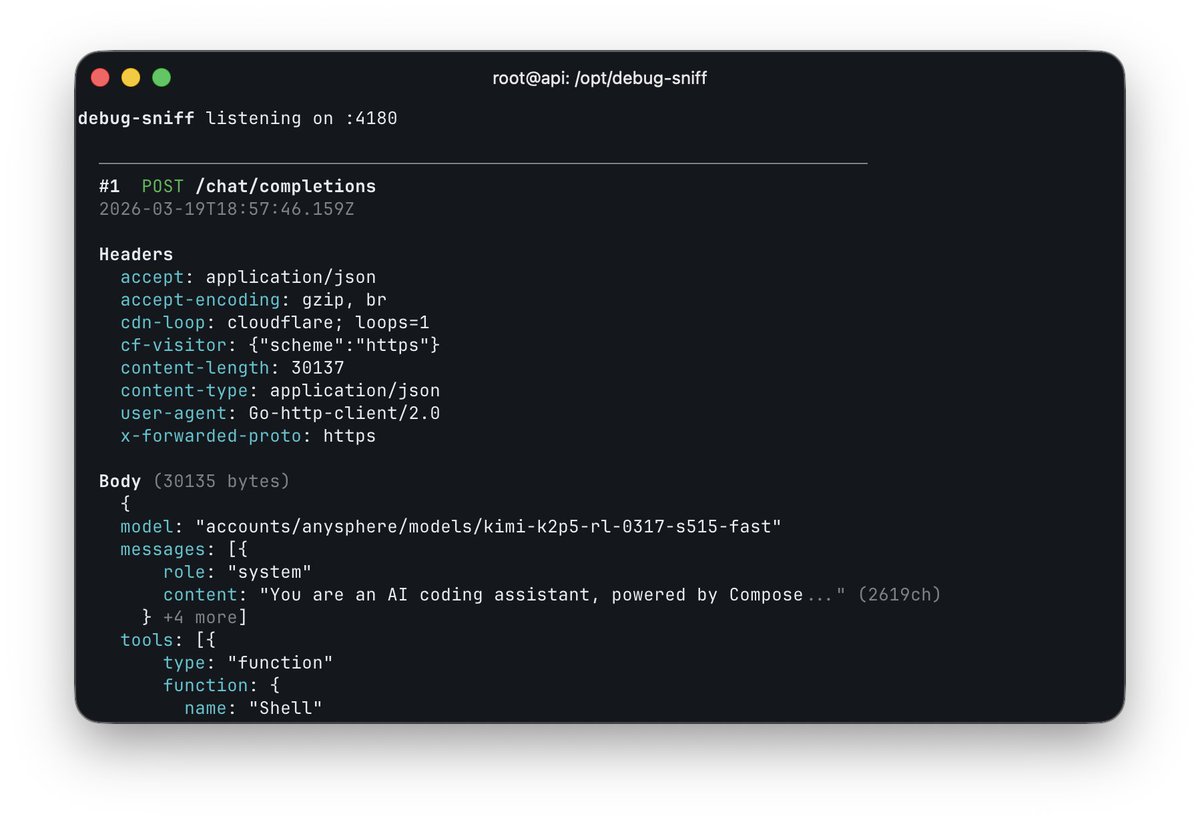
was messing with the OpenAI base URL in Cursor and caught this
accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast
so composer 2 is just Kimi K2.5 with RL
at least rename the model ID
@humancompressed Chain of Thought just needs to rewrite it to the correct syntax and then you’re good. This is exactly how gpt-5 gpt-oss handles math today. Type in 25 times 30 and look at the reasoning and notice it will rewrite it out to 25 * 30 =
just dropped my mcp client oauth library, which i think makes it easier to work with oauth mcp servers.. totally standalone not tied to any agent
framework.. https://t.co/q30HW9LSav
yeah, i cover that about 30 mins of the video... but there is essentially a hierarchy of alignment... what the model has been trained on, the developer prompt, they system prompt, user prompt etc.. but if lower hierarchy prompt conflicts with higher hierarchy prompt.. higher wins