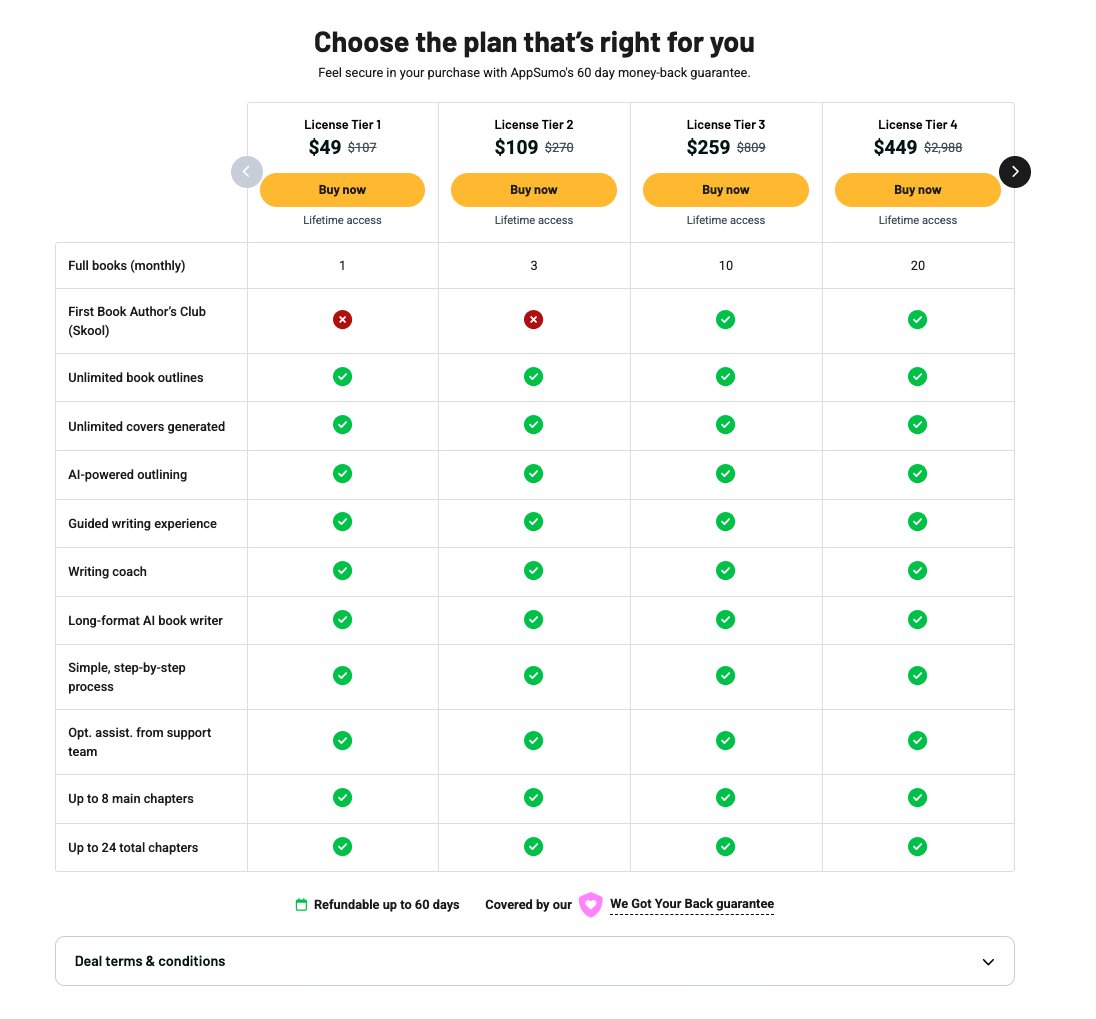
Introducing Adaline 2.0 - The Agent Self-Improvement Layer
Adaline turns Traces into Behaviors,
Behaviors surface Issues,
Issues become auto-generated Evals + Data,
Adaline then generates new agent candidates and tests them.
You review the winners and ship!
Text-to-SQL might sound like a solved problem.
Far from it. Data gets messy and complex really fast in the real world. Strong reasoning models are great, but nothing beats a custom model at this stuff. Gemini-SQL2 looks very strong here. BIRD is a tough benchmark. I suspect there are plenty of opportunities like this in KBs, search, graph databases, etc.
If you've adopted AI at your company but haven't seen any tangible results, read this 1990 article: "The Dynamo and the Computer" by Paul David.
When electricity first arrived, factories that "adopted" it barely got faster. They just swapped the steam engine for an electric one and ran everything else exactly as before: same machine layout, same workflow, same management. Electricity in, no real gains out.
The most common mistake with any new technology is to drop it into the old organization and then declare the transformation done.
The real leap came decades later, when each machine got its own small motor. Suddenly machines no longer had to be lined up around one central drive shaft. They could be rearranged around the actual flow of work.
The productivity gains didn't come from electricity. They came from REDESIGNING THE ENTIRE FACTORY around it.
AI is the same. Bolting it onto your existing process gets you a faster steam engine. The payoff comes when you redesign the work itself.
(link to paper in comments)
Design is full of codewords. Knowing them changes what you can ask for, and what you can get back, whether you're working with devs, or an AI.
“tint this neutral color”, “fix this widow”, “nudge it to the optical center”
I wrote them down: https://t.co/aFyd5avj9o
Attempted to write a Steam Engine hype at the era of Industrial Revolution as if it was the age of AI —
The steam engine breakthrough is insane right now.
Watt’s separate condenser + new GRPO optimization just dropped the 405 hp-class engine. We went from 7 hp → 70 hp → 405 hp+ in basically three years. One machine now does the work of 50+ men or water wheels — nonstop, rain or shine, anywhere.
Textile mills, ironworks, everything scaling 5-10x overnight. Productivity exploding.
This isn’t incremental. It’s automating physical labor at massive scale. Jobs shifting forever. Society about to look unrecognizable.
The Industrial Revolution isn’t coming. It’s here and accelerating faster than anyone predicted.
Terrified. Excited. Both.
What a time to be alive. 🚂💨
In 1960 the IBM 7090 rented for $63,500/mo, or $514,000/mo in today’s dollars. It was the most powerful computer on earth, and universities had to share one across the entire campus.
Today the most powerful AI on earth costs $200/mo and is available to everyone all the time.
Yet, the loudest reaction I see here is that AI pricing is some kind of a ripoff.
On-Premise Business AI Center
After my posts on the 2-GPU and 4-GPU builds, people reached out asking how to build an 8-GPU box for their businesses.
Why?
- Protect their IP
- Protect customer data
- Save on inference costs
- Train their own models
Here's how to build one: 🧵
today in Hell Yeah Technology:
an uncle of mine recently had a stroke
he was at dinner with his family, making them laugh as usual. when they got home, he told his wife he was feeling “off.” by morning, he physically couldn’t get out of bed
after being in a vegetative state for weeks, he’s conscious and doing a little better, but doctors say it’s unlikely he’ll ever speak or walk again
thankfully, somehow, his dominant arm still works - so to make communication less frustrating for everyone involved, i built this local, iPad-first communication board for him with text-to-speech
one of theee simplest, most important tools i’ve ever made
being able to create something useful for a specific person’s needs, without any fluff, in a single sitting, is just unreal
Quick update on my FrankenSQLite project (https://t.co/dlb3LwLAZh), which has proven to be one of the most challenging projects I've taken on so far.
The goal was to make a from-scratch, memory-safe Rust version of SQLite that is truly "drop-in compatible" (meaning you could just swap it out for SQLite and it just works and can open and operate with all your old SQLite database files, etc.) but with a few major changes:
1) Real concurrent writers using a similar MVCC (Multi-Version Concurrency Control) design to what is used in Postgres. (Well, sort of: Postgres does row-level MVCC with VACUUM; FrankenSQLite does page-level MVCC because row-level would have broken SQLite's file format.)
2) Built-in protection against corruption (particularly for WAL files) using RaptorQ fountain codes.
So here's the status check after months of work (which I've likened to a kind of agentic Bataan Death March of optimization):
On a 93-scenario benchmark matrix (which I tried to make as realistic as possible) vs C SQLite, FrankenSQLite is faster on 79 of them, comparable on 5, and slower on 9, with a geometric mean about 3.7x faster overall.
The headline number is 8 concurrent writers on separate tables, which is ~41x the throughput of C SQLite, which still serializes everything through a single lock byte.
Mixed OLTP (80% reads, 20% writes) is ~5.4x faster, scan/aggregate reads ~13.7x.
The 9 places it still loses (which I am actively triaging now) are all single-threaded small-N writes (five small INSERT loops, three small UPDATE/DELETE loops, and one 2-writer same-table case), clustered between 1.05x and 1.37x slower.
Why? Because in these scenarios, each row pays full MVCC bookkeeping (page lock check, version check, page state clear) where C SQLite keeps a cursor open and patches the page in place.
The gap closes once you get past ~4 threads or larger row counts. Closing it for the small-N case is the next chunk of work (the leading approach we are trying is a same-leaf mutation-run operator that amortizes the bookkeeping across rows in the same B-tree leaf without breaking transaction semantics).
The RaptorQ feature is really quite cool. You can intentionally corrupt the WAL with random bit-flips and the engine automatically reconstructs it from the repair symbols, no full WAL replay needed. There is something deeply satisfying about deliberately mutilating a database file and having it just shrug.
Perhaps more interesting than the project itself is the process I've been using on it. I was able to get something that basically worked relatively quickly, but getting complete correctness when dealing with extreme concurrency was a challenge, and trying to match performance against a codebase that's as well-designed and heavily optimized as SQLite is, shall we say, not easy.
Every time I tried to fix one performance issue, it started impacting another one, whack-a-mole style. In order to solve this, I had to create various new skills (most of which are available on my https://t.co/Un9brY2G3l site). My /profiling-software-performance skill was a big breakthrough.
So was designing a big, complex end-to-end testing "matrix" that covered various workloads, like reads, inserts, deletes; individual rows and big groups of rows (there's a huge difference between 1,000 rows and 100,000 rows!). And then testing things with one thread, 2 threads, 4 threads, etc., up to 32 threads.
It was critical to measure real end-to-end workloads rigorously, otherwise the agents would fall into the micro-optimization trap where they'd spend so much time shaving microseconds off of things that barely moved the needle, while ignoring the elephants in the room.
The thing that decisively moved the campaign in my favor after weeks of what felt like trying to boil the ocean was the introduction of a "negative evidence" ledger.
This kept track of all the various performance enhancements we conceived, implemented, and benchmarked, only to discover that they didn't help, or helped in one way but hurt in other ways, and had to be reverted.
I started keeping the ledger and revising it for all new optimization attempts, and "backfilled" it by having the agents go over months' worth of agent coding session history using my cass tool.
By having the agents study that negative ledger before trying the next optimization ideas, they were able to avoid dead-ends and build up strong intuition for what works and what areas were likely to be most fruitful. It ultimately became almost like a search problem.
It also brings to mind, at least for me, the many calls for scientists of all stripes to start publishing their negative findings instead of journals only ever wanting to accept positive results, even when they don't replicate and have massive methodological issues! That's another discussion though...
Anyway, I'm not saying that FrankenSQLite is "done" and I'm not declaring victory yet. I view this project as an ongoing testbed for my techniques and will continue investing many more billions of tokens in polishing and improving it.
I'm already using FrankenSQLite in several of my other projects, including cass (coding_agent_session_search), mcp_agent_mail_rust, beads_rust, and more. The decision to dogfood it early has been quite painful, but has helped to flush out bugs and problems and gives me more confidence that things are on the right path.
I believe I will be able to close out all remaining performance gaps within the next month or so, and will also fix every single correctness issue, since those are much easier to solve once the performance work is done and things are no longer in flux so much.
This project is really a kind of existence proof: if I can do this, then I can do something similar for just about ANY piece of software. Because SQLite is unbelievably complicated and intricate. There's a whole universe of intricacy involving the query planner and dynamic optimizations that the engine makes on queries so they go faster.
And all that complexity becomes magnified dramatically when you get rid of the "one atomic writer" constraint and embrace full-fledged concurrency! All sorts of simplifying assumptions go out the window, and now you need to start tracking tons of things super carefully. If you screw up even one thing, you can end up with catastrophic results very quickly.
And I have a massive number of these projects in-flight now, covering many other ambitious projects, like FrankenNumpy, FrankenJax, FrankenPandas, etc. Plus a complete reimplementation of ALL of glibc, FrankenLibC (already millions of lines of Rust and nearly complete), which can dynamically fix security problems on the fly, a sort of "libc condom" if you will.
And also a complete user-space reimplementation of ext4 and btrfs, FrankenFS. Perhaps most ambitious of these is my FrankenEngine (a complete ground-up JS engine), plus its companion project, FrankenNode. These are setting the foundation for a new kind of platform for running adversarial workloads for extensions/plugins in agent harnesses. Plus many other projects that you can read about on my GitHub profile page.
Finally, I asked Claude: "what else about this project (FrankenSQLite) is most ingenious, innovative, special, and cool, both in absolute terms and relative to legacy SQLite, that I didn't mention?" and here is what it came up with after cranking on it for a while:
---
A pile of things you didn't touch on. Ranked by "would make a database-curious reader stop scrolling":
1. It's actually full SERIALIZABLE by default, not just snapshot isolation — via SSI at page granularity
This is the biggest unmentioned thing IMO. Most MVCC-on-SQLite forks settle for plain Snapshot Isolation, which has the well-known "write skew" anomaly (two transactions can read overlapping data and write disjoint changes that together violate an invariant).
FrankenSQLite implements Serializable Snapshot Isolation — Cahill/Fekete's rule applied at page granularity ("Page-SSI") — so it's full Serializable like the C SQLite serial-writer model, but achieves it via tracking rw-antidependencies instead of locking. Postgres only shipped SSI in 2011 and it took years to get right. You did it for SQLite at page granularity, which is genuinely original work. C SQLite gets serializability the boring way (one writer at a time); you get it the interesting way.
2. The safe write-merge ladder — two writers on the same page often both commit
When two transactions touch the same B-tree leaf page, the standard MVCC answer is "first committer wins, loser aborts and retries." FrankenSQLite tries something cleverer first: each writer keeps a semantic intent log of what it meant to do at the B-tree level (Insert rowid X, Delete index entry Y), and on conflict the loser deterministically rebases its intent log against the winner's new page state.
If the rebase produces a valid B-tree page with no constraint violations, both commit. Only true conflicts abort. Nobody does this in mainstream databases. The phrase "structured page patches + intent replay, byte-range XOR forbidden" is the kind of thing database researchers will recognize and ask you about.
3. Deadlocks are mathematically impossible, by construction
The four-line proof from the README: page locks are acquired eagerly, holding-thread can't wait (gets SQLITE_BUSY immediately), no waiting means no wait-for cycle, no wait-for cycle means no deadlock. So there's no deadlock detector, no timeout tuning, no lock-ordering rules. C SQLite famously can deadlock under contended writes; FrankenSQLite cannot.
4. Page-level encryption is built in (free)
Encrypted SQLite is famously a paid commercial extension (SEE). FrankenSQLite has XChaCha20-Poly1305 AEAD encryption built into the engine, with proper Argon2id KEK derivation and a DEK/KEK envelope so you can rotate keys without re-encrypting the database. Free, drop-in, works on any standard SQLite file path. This is a "wait what" feature for people who've been quoting SEE prices.
5. The async story is wild — and explicitly not tokio
Most database engines aren't async at all (SQLite definitely isn't). The ones that are use tokio. FrankenSQLite uses asupersync, your own structured-concurrency runtime, and threads a &Cx capability context through every I/O-touching call. That Cx carries three things at once: cancellation (long queries can be interrupted at VDBE instruction boundaries with SQLITE_INTERRUPT), deadline propagation (a 5-second budget decrements through parser → planner → executor), and capability narrowing (a read-only Cx mechanically forbids write paths).
Cancellation isn't "drop the future" — it's a multi-phase protocol (Created → CancelRequested → Cancelling → Finalizing → Completed) with linear "obligation" resources that fail-fast if leaked. The supervisor tree is OTP-style: if the WriteCoordinator panics, it escalates; if a Replicator dies, it restarts with backoff. None of this exists in C SQLite or in any other SQLite-compatible engine I'm aware of.
6. Concurrency is deterministically replayable in tests
The asupersync test runtime gives you a Lab reactor with virtual time and DPOR (Dynamic Partial Order Reduction) — every MVCC interleaving can be replayed exactly, and the test infrastructure prunes equivalent schedules so you exhaustively explore all non-equivalent outcomes without combinatorial blowup.
Plus e-processes (anytime-valid statistical invariant monitoring with bounded false-positive rates) for catching SI violations under load. This is the kind of testing infrastructure people write academic papers about.
7. The engine has zero unsafe Rust
Workspace-wide #![forbid(unsafe_code)]. The only crates that override it are fsqlite-vfs (because mmap and shared-memory regions need raw pointers) and the optional fsqlite-c-api shim (because FFI).
The MVCC engine, pager, B-tree, parser, planner, VDBE, all extension surfaces — provably memory-safe Rust. SQLite is ~218K LOC of C with a famous testing budget because it's C. You get the safety for free from the type system.
Reddit says Opus 4.7 is a regression. Boris Cherny says it's more agentic and precise.
Both are right. After 16 hours, I loved it: 4.7 is more capable, but most people are prompting it like 4.6.
You don't need more instructions. Explain what you're building, who it's for, constraints, objectives, and what good looks like. It will figure out how.
This is aligned with Karpathy's Claude coding post:
"LLMs are exceptionally good at looping until they meet specific goals (...) Don't tell it what to do, give it success criteria and watch it go"
The most agentic model. Manage it like a human.











![doodlestein's tweet photo. Quick update on my FrankenSQLite project (https://t.co/dlb3LwLAZh), which has proven to be one of the most challenging projects I've taken on so far.
The goal was to make a from-scratch, memory-safe Rust version of SQLite that is truly "drop-in compatible" (meaning you could just swap it out for SQLite and it just works and can open and operate with all your old SQLite database files, etc.) but with a few major changes:
1) Real concurrent writers using a similar MVCC (Multi-Version Concurrency Control) design to what is used in Postgres. (Well, sort of: Postgres does row-level MVCC with VACUUM; FrankenSQLite does page-level MVCC because row-level would have broken SQLite's file format.)
2) Built-in protection against corruption (particularly for WAL files) using RaptorQ fountain codes.
So here's the status check after months of work (which I've likened to a kind of agentic Bataan Death March of optimization):
On a 93-scenario benchmark matrix (which I tried to make as realistic as possible) vs C SQLite, FrankenSQLite is faster on 79 of them, comparable on 5, and slower on 9, with a geometric mean about 3.7x faster overall.
The headline number is 8 concurrent writers on separate tables, which is ~41x the throughput of C SQLite, which still serializes everything through a single lock byte.
Mixed OLTP (80% reads, 20% writes) is ~5.4x faster, scan/aggregate reads ~13.7x.
The 9 places it still loses (which I am actively triaging now) are all single-threaded small-N writes (five small INSERT loops, three small UPDATE/DELETE loops, and one 2-writer same-table case), clustered between 1.05x and 1.37x slower.
Why? Because in these scenarios, each row pays full MVCC bookkeeping (page lock check, version check, page state clear) where C SQLite keeps a cursor open and patches the page in place.
The gap closes once you get past ~4 threads or larger row counts. Closing it for the small-N case is the next chunk of work (the leading approach we are trying is a same-leaf mutation-run operator that amortizes the bookkeeping across rows in the same B-tree leaf without breaking transaction semantics).
The RaptorQ feature is really quite cool. You can intentionally corrupt the WAL with random bit-flips and the engine automatically reconstructs it from the repair symbols, no full WAL replay needed. There is something deeply satisfying about deliberately mutilating a database file and having it just shrug.
Perhaps more interesting than the project itself is the process I've been using on it. I was able to get something that basically worked relatively quickly, but getting complete correctness when dealing with extreme concurrency was a challenge, and trying to match performance against a codebase that's as well-designed and heavily optimized as SQLite is, shall we say, not easy.
Every time I tried to fix one performance issue, it started impacting another one, whack-a-mole style. In order to solve this, I had to create various new skills (most of which are available on my https://t.co/Un9brY2G3l site). My /profiling-software-performance skill was a big breakthrough.
So was designing a big, complex end-to-end testing "matrix" that covered various workloads, like reads, inserts, deletes; individual rows and big groups of rows (there's a huge difference between 1,000 rows and 100,000 rows!). And then testing things with one thread, 2 threads, 4 threads, etc., up to 32 threads.
It was critical to measure real end-to-end workloads rigorously, otherwise the agents would fall into the micro-optimization trap where they'd spend so much time shaving microseconds off of things that barely moved the needle, while ignoring the elephants in the room.
The thing that decisively moved the campaign in my favor after weeks of what felt like trying to boil the ocean was the introduction of a "negative evidence" ledger.
This kept track of all the various performance enhancements we conceived, implemented, and benchmarked, only to discover that they didn't help, or helped in one way but hurt in other ways, and had to be reverted.
I started keeping the ledger and revising it for all new optimization attempts, and "backfilled" it by having the agents go over months' worth of agent coding session history using my cass tool.
By having the agents study that negative ledger before trying the next optimization ideas, they were able to avoid dead-ends and build up strong intuition for what works and what areas were likely to be most fruitful. It ultimately became almost like a search problem.
It also brings to mind, at least for me, the many calls for scientists of all stripes to start publishing their negative findings instead of journals only ever wanting to accept positive results, even when they don't replicate and have massive methodological issues! That's another discussion though...
Anyway, I'm not saying that FrankenSQLite is "done" and I'm not declaring victory yet. I view this project as an ongoing testbed for my techniques and will continue investing many more billions of tokens in polishing and improving it.
I'm already using FrankenSQLite in several of my other projects, including cass (coding_agent_session_search), mcp_agent_mail_rust, beads_rust, and more. The decision to dogfood it early has been quite painful, but has helped to flush out bugs and problems and gives me more confidence that things are on the right path.
I believe I will be able to close out all remaining performance gaps within the next month or so, and will also fix every single correctness issue, since those are much easier to solve once the performance work is done and things are no longer in flux so much.
This project is really a kind of existence proof: if I can do this, then I can do something similar for just about ANY piece of software. Because SQLite is unbelievably complicated and intricate. There's a whole universe of intricacy involving the query planner and dynamic optimizations that the engine makes on queries so they go faster.
And all that complexity becomes magnified dramatically when you get rid of the "one atomic writer" constraint and embrace full-fledged concurrency! All sorts of simplifying assumptions go out the window, and now you need to start tracking tons of things super carefully. If you screw up even one thing, you can end up with catastrophic results very quickly.
And I have a massive number of these projects in-flight now, covering many other ambitious projects, like FrankenNumpy, FrankenJax, FrankenPandas, etc. Plus a complete reimplementation of ALL of glibc, FrankenLibC (already millions of lines of Rust and nearly complete), which can dynamically fix security problems on the fly, a sort of "libc condom" if you will.
And also a complete user-space reimplementation of ext4 and btrfs, FrankenFS. Perhaps most ambitious of these is my FrankenEngine (a complete ground-up JS engine), plus its companion project, FrankenNode. These are setting the foundation for a new kind of platform for running adversarial workloads for extensions/plugins in agent harnesses. Plus many other projects that you can read about on my GitHub profile page.
Finally, I asked Claude: "what else about this project (FrankenSQLite) is most ingenious, innovative, special, and cool, both in absolute terms and relative to legacy SQLite, that I didn't mention?" and here is what it came up with after cranking on it for a while:
---
A pile of things you didn't touch on. Ranked by "would make a database-curious reader stop scrolling":
1. It's actually full SERIALIZABLE by default, not just snapshot isolation — via SSI at page granularity
This is the biggest unmentioned thing IMO. Most MVCC-on-SQLite forks settle for plain Snapshot Isolation, which has the well-known "write skew" anomaly (two transactions can read overlapping data and write disjoint changes that together violate an invariant).
FrankenSQLite implements Serializable Snapshot Isolation — Cahill/Fekete's rule applied at page granularity ("Page-SSI") — so it's full Serializable like the C SQLite serial-writer model, but achieves it via tracking rw-antidependencies instead of locking. Postgres only shipped SSI in 2011 and it took years to get right. You did it for SQLite at page granularity, which is genuinely original work. C SQLite gets serializability the boring way (one writer at a time); you get it the interesting way.
2. The safe write-merge ladder — two writers on the same page often both commit
When two transactions touch the same B-tree leaf page, the standard MVCC answer is "first committer wins, loser aborts and retries." FrankenSQLite tries something cleverer first: each writer keeps a semantic intent log of what it meant to do at the B-tree level (Insert rowid X, Delete index entry Y), and on conflict the loser deterministically rebases its intent log against the winner's new page state.
If the rebase produces a valid B-tree page with no constraint violations, both commit. Only true conflicts abort. Nobody does this in mainstream databases. The phrase "structured page patches + intent replay, byte-range XOR forbidden" is the kind of thing database researchers will recognize and ask you about.
3. Deadlocks are mathematically impossible, by construction
The four-line proof from the README: page locks are acquired eagerly, holding-thread can't wait (gets SQLITE_BUSY immediately), no waiting means no wait-for cycle, no wait-for cycle means no deadlock. So there's no deadlock detector, no timeout tuning, no lock-ordering rules. C SQLite famously can deadlock under contended writes; FrankenSQLite cannot.
4. Page-level encryption is built in (free)
Encrypted SQLite is famously a paid commercial extension (SEE). FrankenSQLite has XChaCha20-Poly1305 AEAD encryption built into the engine, with proper Argon2id KEK derivation and a DEK/KEK envelope so you can rotate keys without re-encrypting the database. Free, drop-in, works on any standard SQLite file path. This is a "wait what" feature for people who've been quoting SEE prices.
5. The async story is wild — and explicitly not tokio
Most database engines aren't async at all (SQLite definitely isn't). The ones that are use tokio. FrankenSQLite uses asupersync, your own structured-concurrency runtime, and threads a &Cx capability context through every I/O-touching call. That Cx carries three things at once: cancellation (long queries can be interrupted at VDBE instruction boundaries with SQLITE_INTERRUPT), deadline propagation (a 5-second budget decrements through parser → planner → executor), and capability narrowing (a read-only Cx mechanically forbids write paths).
Cancellation isn't "drop the future" — it's a multi-phase protocol (Created → CancelRequested → Cancelling → Finalizing → Completed) with linear "obligation" resources that fail-fast if leaked. The supervisor tree is OTP-style: if the WriteCoordinator panics, it escalates; if a Replicator dies, it restarts with backoff. None of this exists in C SQLite or in any other SQLite-compatible engine I'm aware of.
6. Concurrency is deterministically replayable in tests
The asupersync test runtime gives you a Lab reactor with virtual time and DPOR (Dynamic Partial Order Reduction) — every MVCC interleaving can be replayed exactly, and the test infrastructure prunes equivalent schedules so you exhaustively explore all non-equivalent outcomes without combinatorial blowup.
Plus e-processes (anytime-valid statistical invariant monitoring with bounded false-positive rates) for catching SI violations under load. This is the kind of testing infrastructure people write academic papers about.
7. The engine has zero unsafe Rust
Workspace-wide #![forbid(unsafe_code)]. The only crates that override it are fsqlite-vfs (because mmap and shared-memory regions need raw pointers) and the optional fsqlite-c-api shim (because FFI).
The MVCC engine, pager, B-tree, parser, planner, VDBE, all extension surfaces — provably memory-safe Rust. SQLite is ~218K LOC of C with a famous testing budget because it's C. You get the safety for free from the type system.](https://pbs.twimg.com/media/HH1aK9rWQAEUx_C.jpg)























![doodlestein's tweet photo. Quick update on my FrankenSQLite project (https://t.co/dlb3LwLAZh), which has proven to be one of the most challenging projects I've taken on so far.
The goal was to make a from-scratch, memory-safe Rust version of SQLite that is truly "drop-in compatible" (meaning you could just swap it out for SQLite and it just works and can open and operate with all your old SQLite database files, etc.) but with a few major changes:
1) Real concurrent writers using a similar MVCC (Multi-Version Concurrency Control) design to what is used in Postgres. (Well, sort of: Postgres does row-level MVCC with VACUUM; FrankenSQLite does page-level MVCC because row-level would have broken SQLite's file format.)
2) Built-in protection against corruption (particularly for WAL files) using RaptorQ fountain codes.
So here's the status check after months of work (which I've likened to a kind of agentic Bataan Death March of optimization):
On a 93-scenario benchmark matrix (which I tried to make as realistic as possible) vs C SQLite, FrankenSQLite is faster on 79 of them, comparable on 5, and slower on 9, with a geometric mean about 3.7x faster overall.
The headline number is 8 concurrent writers on separate tables, which is ~41x the throughput of C SQLite, which still serializes everything through a single lock byte.
Mixed OLTP (80% reads, 20% writes) is ~5.4x faster, scan/aggregate reads ~13.7x.
The 9 places it still loses (which I am actively triaging now) are all single-threaded small-N writes (five small INSERT loops, three small UPDATE/DELETE loops, and one 2-writer same-table case), clustered between 1.05x and 1.37x slower.
Why? Because in these scenarios, each row pays full MVCC bookkeeping (page lock check, version check, page state clear) where C SQLite keeps a cursor open and patches the page in place.
The gap closes once you get past ~4 threads or larger row counts. Closing it for the small-N case is the next chunk of work (the leading approach we are trying is a same-leaf mutation-run operator that amortizes the bookkeeping across rows in the same B-tree leaf without breaking transaction semantics).
The RaptorQ feature is really quite cool. You can intentionally corrupt the WAL with random bit-flips and the engine automatically reconstructs it from the repair symbols, no full WAL replay needed. There is something deeply satisfying about deliberately mutilating a database file and having it just shrug.
Perhaps more interesting than the project itself is the process I've been using on it. I was able to get something that basically worked relatively quickly, but getting complete correctness when dealing with extreme concurrency was a challenge, and trying to match performance against a codebase that's as well-designed and heavily optimized as SQLite is, shall we say, not easy.
Every time I tried to fix one performance issue, it started impacting another one, whack-a-mole style. In order to solve this, I had to create various new skills (most of which are available on my https://t.co/Un9brY2G3l site). My /profiling-software-performance skill was a big breakthrough.
So was designing a big, complex end-to-end testing "matrix" that covered various workloads, like reads, inserts, deletes; individual rows and big groups of rows (there's a huge difference between 1,000 rows and 100,000 rows!). And then testing things with one thread, 2 threads, 4 threads, etc., up to 32 threads.
It was critical to measure real end-to-end workloads rigorously, otherwise the agents would fall into the micro-optimization trap where they'd spend so much time shaving microseconds off of things that barely moved the needle, while ignoring the elephants in the room.
The thing that decisively moved the campaign in my favor after weeks of what felt like trying to boil the ocean was the introduction of a "negative evidence" ledger.
This kept track of all the various performance enhancements we conceived, implemented, and benchmarked, only to discover that they didn't help, or helped in one way but hurt in other ways, and had to be reverted.
I started keeping the ledger and revising it for all new optimization attempts, and "backfilled" it by having the agents go over months' worth of agent coding session history using my cass tool.
By having the agents study that negative ledger before trying the next optimization ideas, they were able to avoid dead-ends and build up strong intuition for what works and what areas were likely to be most fruitful. It ultimately became almost like a search problem.
It also brings to mind, at least for me, the many calls for scientists of all stripes to start publishing their negative findings instead of journals only ever wanting to accept positive results, even when they don't replicate and have massive methodological issues! That's another discussion though...
Anyway, I'm not saying that FrankenSQLite is "done" and I'm not declaring victory yet. I view this project as an ongoing testbed for my techniques and will continue investing many more billions of tokens in polishing and improving it.
I'm already using FrankenSQLite in several of my other projects, including cass (coding_agent_session_search), mcp_agent_mail_rust, beads_rust, and more. The decision to dogfood it early has been quite painful, but has helped to flush out bugs and problems and gives me more confidence that things are on the right path.
I believe I will be able to close out all remaining performance gaps within the next month or so, and will also fix every single correctness issue, since those are much easier to solve once the performance work is done and things are no longer in flux so much.
This project is really a kind of existence proof: if I can do this, then I can do something similar for just about ANY piece of software. Because SQLite is unbelievably complicated and intricate. There's a whole universe of intricacy involving the query planner and dynamic optimizations that the engine makes on queries so they go faster.
And all that complexity becomes magnified dramatically when you get rid of the "one atomic writer" constraint and embrace full-fledged concurrency! All sorts of simplifying assumptions go out the window, and now you need to start tracking tons of things super carefully. If you screw up even one thing, you can end up with catastrophic results very quickly.
And I have a massive number of these projects in-flight now, covering many other ambitious projects, like FrankenNumpy, FrankenJax, FrankenPandas, etc. Plus a complete reimplementation of ALL of glibc, FrankenLibC (already millions of lines of Rust and nearly complete), which can dynamically fix security problems on the fly, a sort of "libc condom" if you will.
And also a complete user-space reimplementation of ext4 and btrfs, FrankenFS. Perhaps most ambitious of these is my FrankenEngine (a complete ground-up JS engine), plus its companion project, FrankenNode. These are setting the foundation for a new kind of platform for running adversarial workloads for extensions/plugins in agent harnesses. Plus many other projects that you can read about on my GitHub profile page.
Finally, I asked Claude: "what else about this project (FrankenSQLite) is most ingenious, innovative, special, and cool, both in absolute terms and relative to legacy SQLite, that I didn't mention?" and here is what it came up with after cranking on it for a while:
---
A pile of things you didn't touch on. Ranked by "would make a database-curious reader stop scrolling":
1. It's actually full SERIALIZABLE by default, not just snapshot isolation — via SSI at page granularity
This is the biggest unmentioned thing IMO. Most MVCC-on-SQLite forks settle for plain Snapshot Isolation, which has the well-known "write skew" anomaly (two transactions can read overlapping data and write disjoint changes that together violate an invariant).
FrankenSQLite implements Serializable Snapshot Isolation — Cahill/Fekete's rule applied at page granularity ("Page-SSI") — so it's full Serializable like the C SQLite serial-writer model, but achieves it via tracking rw-antidependencies instead of locking. Postgres only shipped SSI in 2011 and it took years to get right. You did it for SQLite at page granularity, which is genuinely original work. C SQLite gets serializability the boring way (one writer at a time); you get it the interesting way.
2. The safe write-merge ladder — two writers on the same page often both commit
When two transactions touch the same B-tree leaf page, the standard MVCC answer is "first committer wins, loser aborts and retries." FrankenSQLite tries something cleverer first: each writer keeps a semantic intent log of what it meant to do at the B-tree level (Insert rowid X, Delete index entry Y), and on conflict the loser deterministically rebases its intent log against the winner's new page state.
If the rebase produces a valid B-tree page with no constraint violations, both commit. Only true conflicts abort. Nobody does this in mainstream databases. The phrase "structured page patches + intent replay, byte-range XOR forbidden" is the kind of thing database researchers will recognize and ask you about.
3. Deadlocks are mathematically impossible, by construction
The four-line proof from the README: page locks are acquired eagerly, holding-thread can't wait (gets SQLITE_BUSY immediately), no waiting means no wait-for cycle, no wait-for cycle means no deadlock. So there's no deadlock detector, no timeout tuning, no lock-ordering rules. C SQLite famously can deadlock under contended writes; FrankenSQLite cannot.
4. Page-level encryption is built in (free)
Encrypted SQLite is famously a paid commercial extension (SEE). FrankenSQLite has XChaCha20-Poly1305 AEAD encryption built into the engine, with proper Argon2id KEK derivation and a DEK/KEK envelope so you can rotate keys without re-encrypting the database. Free, drop-in, works on any standard SQLite file path. This is a "wait what" feature for people who've been quoting SEE prices.
5. The async story is wild — and explicitly not tokio
Most database engines aren't async at all (SQLite definitely isn't). The ones that are use tokio. FrankenSQLite uses asupersync, your own structured-concurrency runtime, and threads a &Cx capability context through every I/O-touching call. That Cx carries three things at once: cancellation (long queries can be interrupted at VDBE instruction boundaries with SQLITE_INTERRUPT), deadline propagation (a 5-second budget decrements through parser → planner → executor), and capability narrowing (a read-only Cx mechanically forbids write paths).
Cancellation isn't "drop the future" — it's a multi-phase protocol (Created → CancelRequested → Cancelling → Finalizing → Completed) with linear "obligation" resources that fail-fast if leaked. The supervisor tree is OTP-style: if the WriteCoordinator panics, it escalates; if a Replicator dies, it restarts with backoff. None of this exists in C SQLite or in any other SQLite-compatible engine I'm aware of.
6. Concurrency is deterministically replayable in tests
The asupersync test runtime gives you a Lab reactor with virtual time and DPOR (Dynamic Partial Order Reduction) — every MVCC interleaving can be replayed exactly, and the test infrastructure prunes equivalent schedules so you exhaustively explore all non-equivalent outcomes without combinatorial blowup.
Plus e-processes (anytime-valid statistical invariant monitoring with bounded false-positive rates) for catching SI violations under load. This is the kind of testing infrastructure people write academic papers about.
7. The engine has zero unsafe Rust
Workspace-wide #![forbid(unsafe_code)]. The only crates that override it are fsqlite-vfs (because mmap and shared-memory regions need raw pointers) and the optional fsqlite-c-api shim (because FFI).
The MVCC engine, pager, B-tree, parser, planner, VDBE, all extension surfaces — provably memory-safe Rust. SQLite is ~218K LOC of C with a famous testing budget because it's C. You get the safety for free from the type system.](https://pbs.twimg.com/media/HH1mwGQWsAYi3BL.jpg)





















