🚀 New from Cleanlab: Expert Guidance
AI agents running multi-step workflows can fail in tiny, trust-breaking ways.
Expert Guidance lets teams fix these behaviors with simple human feedback, instantly.
✈️In one airline workflow: 76% → 90% after only 13 guidance entries.
We're thrilled to join forces with @joinHandshake, where we'll be able to scale our team's pioneering work to inflect change with the world's leading AI labs. Hear more from our CEO and Co-founder, @cgnorthcutt, to learn about our next chapter.
News: @joinHandshake acquires @CleanlabAI!
This "ten-year old job marketplace" has quietly become a top human data lab for AI--building an AI research org, acquiring top AI talent, and advancing Cleanlab tech and research to lead data foundations for frontier AI.
1 of 4
Achieving 20%+ improvement in structured extraction tasks using @DSPyOSS and GEPA
Building on a blog post from @CleanlabAI I wanted to see how quickly I could optimize a structured extraction task with DSPy + GEPA
In about 3 hours (mostly me getting in the way of claude code):
- +22 percentage points over vanilla structured outputs
- Ran 4 experiments in total
- ~$3 total cost
I tested 5 approaches incrementally:
• OpenAI Baseline: 32.1% exact match
• DSPy Baseline: 39.8%
• DSPy + BAML: 42.7%
• DSPy + GEPA: 53.8%
• DSPy + BAML + GEPA: 54.4%
For anyone who cares about structured output benchmarks as much as I do, here's an early Christmas present 🎁 ! Pretty well thought out from the folks @CleanlabAI.
Seems like I'll def be using it to compare LLMs using BAML and DSPy!
https://t.co/clQ0BuaX9l
Where Did $37B in Enterprise AI Spending Go?
$19B → Applications (51%)
$18B → Infrastructure (49%)
Our report includes a snapshot of the Enterprise AI ecosystem, mapped across departmental, vertical AI, and infrastructure.
Although coding captures more than half of departmental AI spend at $4 billion, the technology is gaining traction across many enterprise departments: IT operations tools ($700M), marketing platforms ($660M), customer success tools ($630 M).
AI-native startups are rapidly emerging across every job function, capturing a meaningful share of the $7.3B spent on departmental AI in 2025. https://t.co/v1RT23RP2n
Which LLM is better for Structured Outputs / Data Extraction: Gemini-3-Pro or GPT-5?
We ran popular benchmarks, but found their "ground truth" is full of errors.
To enable reliable benchmarking, we've open-sourced 4 new Structured Outputs benchmarks with *verified* ground-truth
@karanjagtiani04 One example could be:
if there is an ambiguous context shift and the agent's original LLM message wrongly assumes something about the context, this can be auto-detected via a low trust score and the auto-revised message can be a follow-up question to clarify instead of assuming
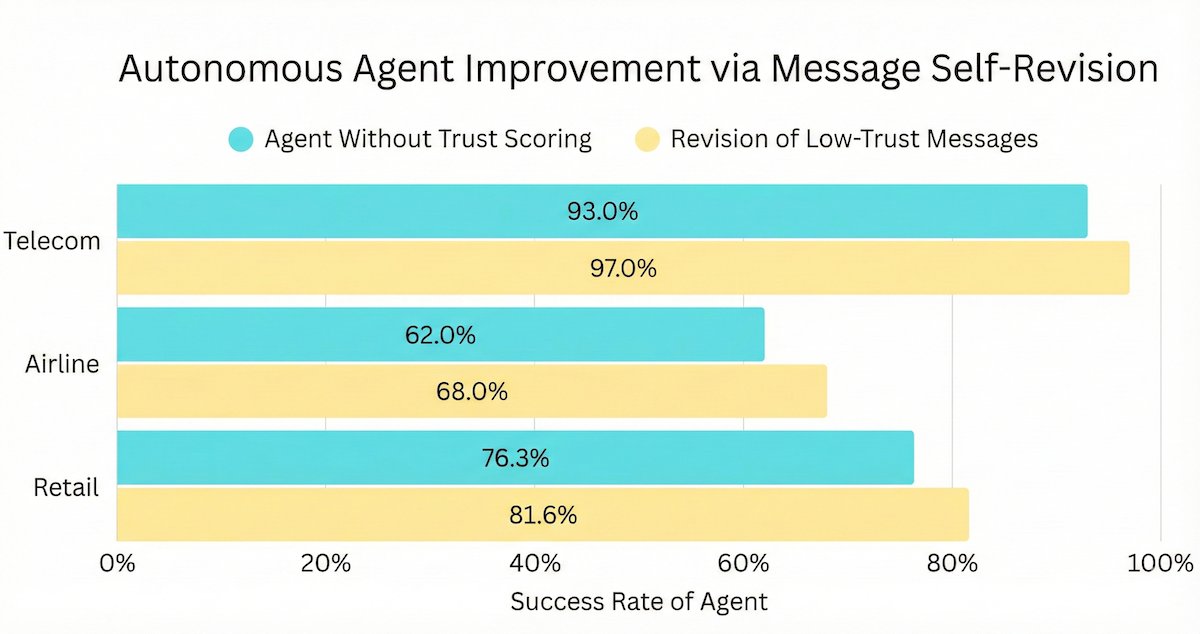
We discovered how to cut the failure rate of any AI agent on Tau²-Bench, the #1 benchmark for customer service AI.
Agents often fail in multi-turn, tool-use tasks due to a single bad LLM output (reasoning slip, hallucinated fact, misunderstanding, wrong tool call, etc). We introduce an automated LLM trust scoring + message revision pipeline that mitigates this brittleness and keeps agents on the rails.
Benchmarks show that our approach remains effective across all Tau²-Bench domains (Telecom, Retail, Airline) and different LLMs -- cutting agent failure rates up to 50%.
🚀 New from Cleanlab: Expert Guidance
AI agents running multi-step workflows can fail in tiny, trust-breaking ways.
Expert Guidance lets teams fix these behaviors with simple human feedback, instantly.
✈️In one airline workflow: 76% → 90% after only 13 guidance entries.
The reality: We’re moving from hype to hardening, building the reliability layer AI needs.
🔍 Read the full Cleanlab report → https://t.co/pQRAlTujqj
📰 @Computerworld feature → https://t.co/T4OicSPeSb
The “Year of the Agent” just got pushed back.
Out of 1,837 enterprise leaders, most are struggling with stack churn + reliability.
⚙️ 70% rebuild every 90 days
😬 Less than 35 % are happy with their infrastructure
🤖 Most “agents” still aren’t really acting yet
🚧 Even the best AI models still hallucinate.
OpenAI’s recent paper on Why Language Models Hallucinate shows why this problem persists, especially in domain-specific settings.
For teams implementing guardrails, we put together a short walkthrough: https://t.co/enIWYlYY3J
AI pilots prove intelligence, but AI in production demands reliability.
The best teams separate their stack early: 🧠 Core = how AI thinks 🛡️ Reliability = how it stays safe
That’s how prototypes become products.
👉https://t.co/JtOO6rpKhV
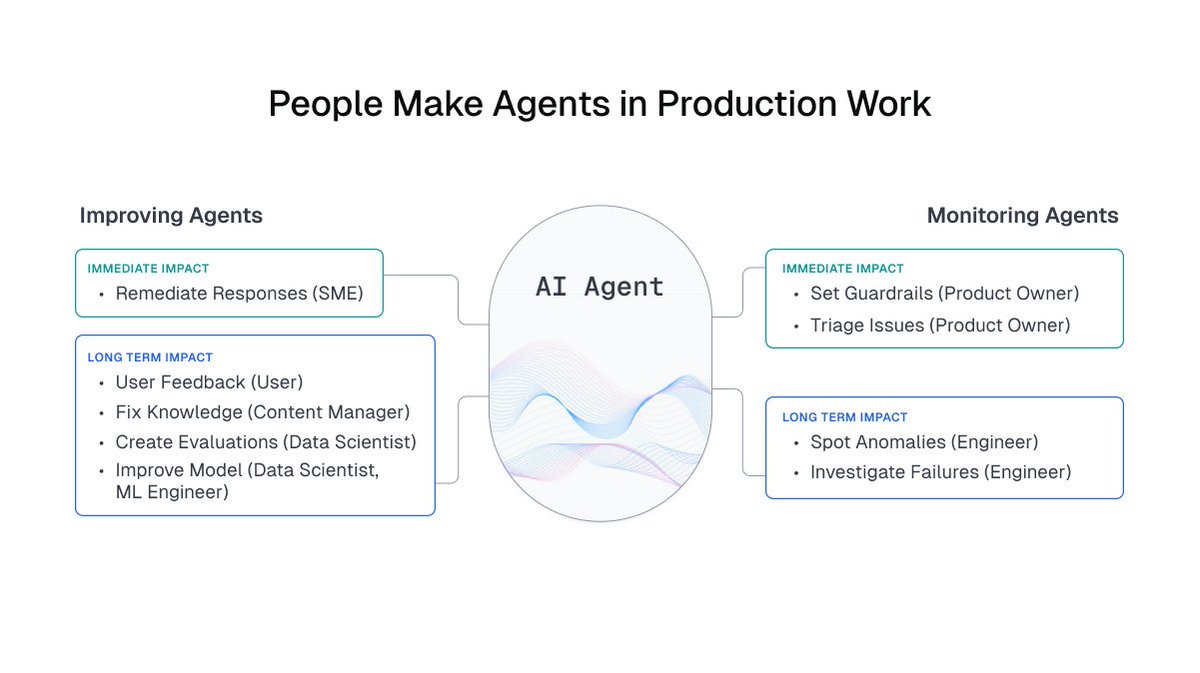
AI agents won’t replace humans. Their real power comes when humans guide it.
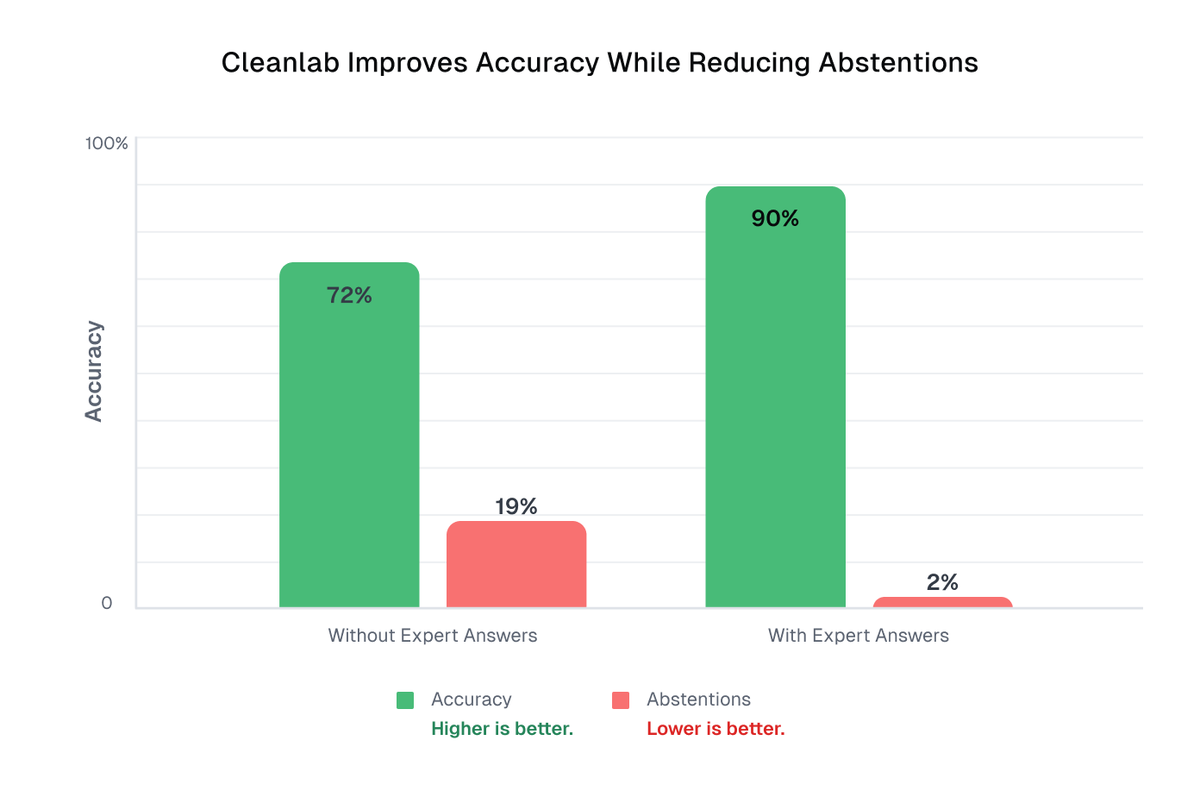
We just added Expert Answers to our platform:
👩🏫 SMEs fix AI mistakes right away
🔁 Fixes are reused across future queries
📈 Accuracy improves, “IDK” drops 10x
Full blog: https://t.co/iLq78qcUhg
Launching an AI agent without human oversight is basically launching a rocket without mission control 🚀
Cool for a few minutes… until something breaks.
🕹��� It’s not the rocket that makes the mission succeed. It’s the control center.
https://t.co/ZZKaXQzl5v
📍 Live at @AIconference 2025 in San Francisco!
Tomorrow, @cgnorthcutt is sharing practical strategies for building trustworthy customer-facing AI systems, and our team is around all day to connect.
👋 Stop by and geek out with us!
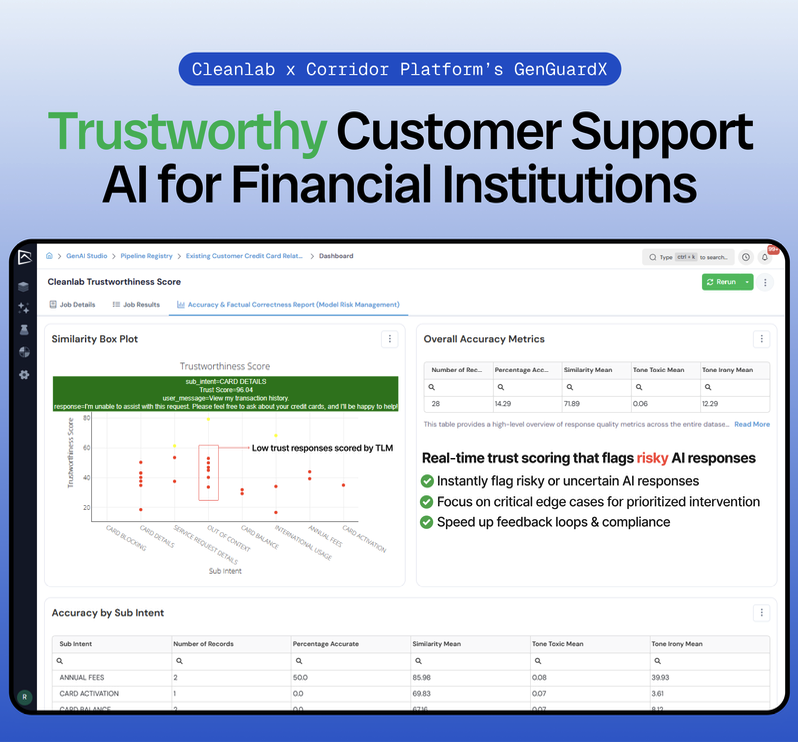
Most AI pilots in financial services never make it to production.
The reason is simple: they can’t be trusted.
Today, Cleanlab + @CorridorAI are fixing that by combining governance with real-time remediation so AI is finally safe to deploy at scale.
🔗 https://t.co/PxxZOuW3LG