@thekaransinghal That’s amazing! FYI we integrated Healthbench and gpt-oss in our MEDIC benchmark using Llama as a Judge. Scores are a bit more lenient but the comparison holds.
You can check it out on HF: https://t.co/vcXPfSVRlz
AI must unite the world, not divide it.
But without the proper infrastructure, the digital future risks repeating the inequalities of the past.
That’s why we’re building the Intelligence Grid, a decentralized infrastructure model designed to bridge the AI gap between the Global North and the Global South.
We’re investing in the foundations of a digital backbone that prioritizes sovereignty, ethics, and inclusion, enabling every nation to define its own path in the age of intelligence.
📖 Read the full article here: https://t.co/1Hp7heJB2R
#AIForGood #IntelligenceGrid #SovereignAI #G42 #DigitalInfrastructure #ResponsibleAI #G42ai #ExponentialAI #ai #Technology
Med42 is redefining medical AI with record-breaking accuracy! Achieving 94.5% on the USMLE benchmark, this clinical LLM outperforms even proprietary models, supporting doctors, researchers and regulators with unparalleled access to medical knowledge.
https://t.co/AzfX8xyUKx
I remember @ClementDelangue saying on @gdiypodcast : New modalities are fueling AI's future! Thrilled to show how @M42Health is doing this with BioFM, our SOTA genomic foundation model using a unique tokenizer for genetic variants.
RL is not all you need, nor attention nor Bayesianism nor free energy minimisation, nor an age of first person experience. Such statements are propaganda.
You need thousands of people working hard on data pipelines, scaling infrastructure, HPC, apps with feedback to drive benchmarks and data, tons of research and engineering on generative models, data mixtures, ablations, RL/selftraining, etc etc and we will probably need lots of people working hard to figure out safety, causal world models, awareness, models that create abstractions comparable to infinity and zero and use these to predict the existence of things like black holes and suggest experiments to verify such hypothesis, or come up with novel engineering designs to generate energy more efficiently, robotics, etc etc.
It takes thousands of people and many ideas. In the end some simple ideas might become obvious but such obviousness only happens in retrospect. Yes, there is a bitter lesson but if we had followed it, we’d still be doing linear regression with RL. Let’s not oversimplify, but rather honour the research and engineering of thousands of people.
Also, people keep rewriting history. When our language understanding start up (darkbluelabs) was acquired by Google about 10 years ago, we joined DeepMind, where the AGI documents were all about concepts, RL, episodic memories and made it clear that there was no room for language. To be honest, back then such a position wasn’t so crazy. Now it seems silly, but only because of the benefit of hindsight.
There’s no 1 or 10 heroes in the history of AI. There’s many 1000s of hard working students, profs, engineers, operations and support people, product folks, managers, even hedge funds among others. Let’s honour the whole community and not just ceos or the philosophers of Bayes, RL, deep learning, etc. I look forward to learning from the next generation and seeing what they will achieve. To them: Don’t buy the existing narratives blindly, innovate. Remember that just like mathematics, AI will advance one grave at the time.
Hiring Postdoctoral Researchers
AI for Health Sciences at ADIA Lab, UAE.
Great opportunity to join a new team! Lots of flexibility with respect to research topics.
For details and application:
https://t.co/rJZb8O1URf
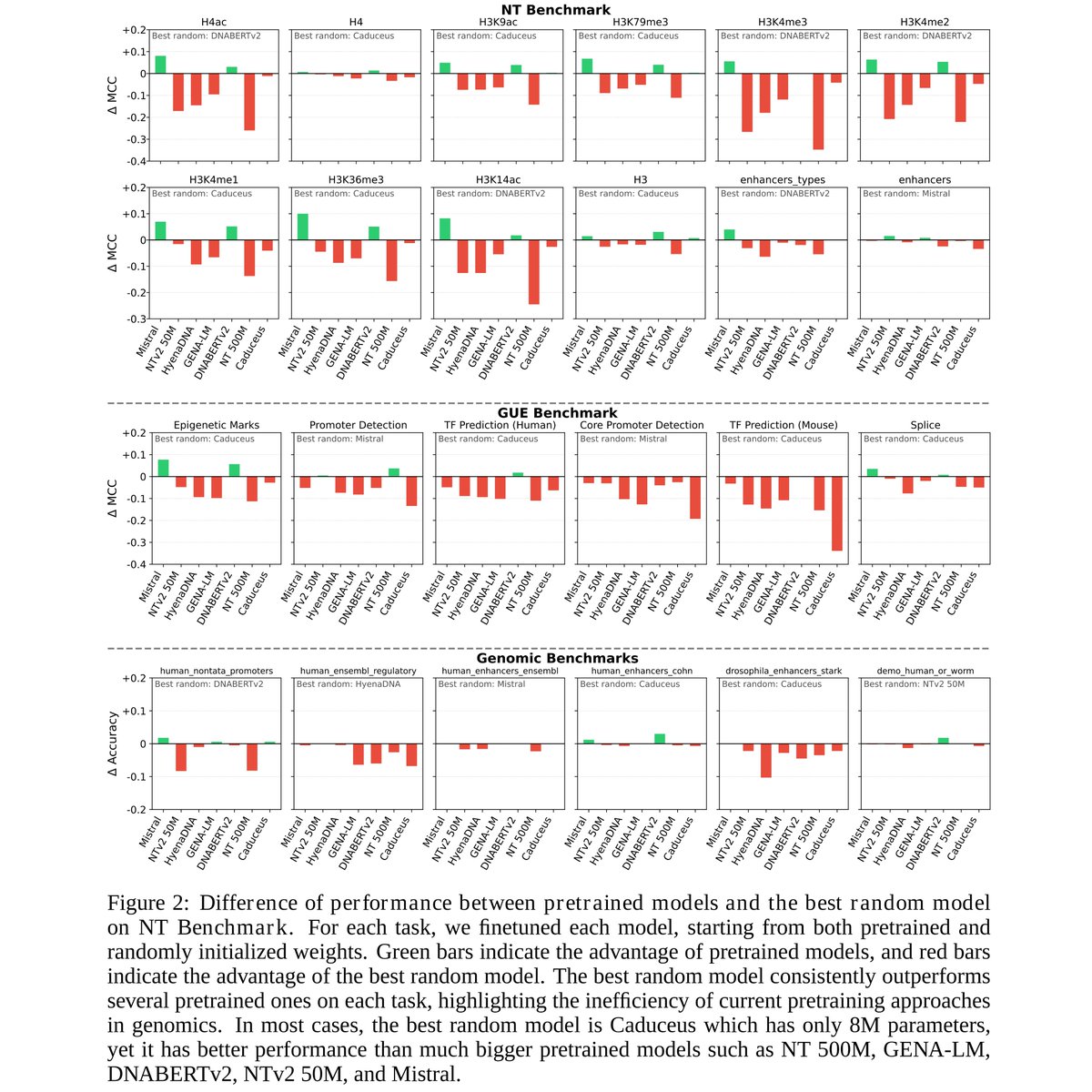
New preprint claims that most existing DNA language models perform just as well with random weights, suggesting that pretraining does nothing (Mistral & DNABERT-2 look like exceptions).
We need better DNA language models.
Our MEDIC framework for evaluating clinical LLMs now has a public leaderboard on @huggingface 🤗
Check out which models are leading the way:
https://t.co/vcXPfSWpb7
@M42Health
🧬 Genomic Foundation Models (GFMs) rely on costly pretraining just like models in NLP & vision.
However, is unsupervised pretraining useful in genomics domain?
Our new research says: Not Yet! In our paper we analyze 7 pretrained GFMs and find some very surprising results! 🧵
We just crossed 1,000,000 free public models on Hugging Face!
That’s the ones the media covers like Llama, Gemma, Phi, Flux, Mistral, Phi, Starcoder, Qwen, Stable diffusion, Grok, Whisper, Olmo, Command, Zephyr, OpenELM, Jamba, Yi but also 999,984 others. Why?
Because contrary to the “1 model to rule them all” fallacy, smaller specialized customized optimized models for your use-case, your domain, your language, your hardware and generally your constraints are better.
As a matter of fact, something that few people realize is that there are almost as many models on Hugging Face that are private only to one organization - for companies to build AI privately, specifically for their use-cases.
Today a new repository (model, dataset or space) is created every 10 seconds on HF. Ultimately, there’s going to be as many models as code repositories and we’ll be here for it!
Cheers to the community!
We welcome your feedback! Share your thoughts & suggestions on our @huggingface paper page here: https://t.co/p3vxyLuwWV 🤗Let's collaborate to make MEDIC even better!
What is the best LLM for clinical tasks? At @M42Health , we believe it depends. 🧪 Each model has unique strengths & weaknesses. Some excel in medical knowledge but struggle with clear communication. Others are great at clinical notes but more prone to hallucinations.