I made a tiny Paperclip adapter for custom/local LLM endpoints.
If you already have an OpenAI-compatible proxy, OpenRouter gateway, Qwen/GLM setup, local server, or anything speaking HTTP, your Paperclip agents can call it directly.
Built for the boring but useful problem: fewer setup layers, more model freedom.
#paperclip
Así es trabajar en bancos como programador:
1. Te contratan.
2. Te entregan el equipo.
3. Levantas tickets para acceso a repos, herramientas, jira, etc.
4. Pasa un mes y ya tienes los accesos.
5. Te faltó pedir un permiso y debes esperar otros 20 días.
6. Dos meses después ya puedes empezar a desarrollar.
7. Te asignan la fecha de release.
8. Terminas el desarrollo y pruebas.
9. Creas la documentación necesaria para solicitar el release.
10. Creas los tickets para solicitar el release.
11. Debes conseguir los approvals de los tickets al menos 3 días antes de la fecha de release.
12. Te autorizan el release.
13. Falla el release, tienes que hacer rollback.
14. Debes esperar hasta la siguiente fecha de release.
15. Inicias el desarrollo del nuevo sprint.
16. Vuelve al paso 8.
Después les explico como se hacen los hotfix!
One Claude Max subscriber generated $5,600 in API costs on a $100/month plan. A 56x subsidy ratio.
Anthropic is now moving Enterprise to usage-based pricing, The Information reports. The flat-rate era for AI is ending.
In China, the same collision is playing out at a fraction of the price:https://t.co/APNawmeZBW
샘 올트먼이나 다리오 아모데이가 말하는 건 기본적으로 마케팅이다. 그들의 말은 들리는대로 받아들여선 안된다. 심심이(LLM)들은 인류의 삶을 본질적으로 바꿀 수 없다. AGI든 초지능이든 그 무엇이 나온다해도 본질적으로 변하는 것은 아무것도 없다. 감히 산업혁명에 비할 데가 아니다. 그리고 그 산��혁명조차도 인류를 "더 일하게" 만들었다. 심심이들도 인간의 일을 늘렸으면 늘렸지 줄일 순 없다. 고용이 줄어드는건 순전히 자본의 농간일뿐.
https://t.co/utC8aht2tH
바이브 코딩으로 만든 환자 관리 앱의 보안 참사
- 의료기관 직원이 AI 코딩 에이전트로 환자 관리 시스템을 직접 제작하며, 환자 데이터가 인터넷에 암호화 없이 노출됨
- 진료 대화 녹음이 두 개의 AI 서비스로 ��송되어 자동 요약되었고, 모든 데이터에 읽기·쓰기 권…
https://t.co/Gq9HAhEFfn
🚨 Stanford just published the most uncomfortable AI paper of the year.
They just dropped a systematic teardown of how large language models actually "think."
It proves that passing a benchmark has almost nothing to do with real reasoning.
We have spent years optimizing for tests.
But the researchers found that performance does not transfer nearly as well as the leaderboards imply.
A model that looks incredibly strong on a math benchmark will quietly fall apart when asked to do scientific reasoning, planning, or multi-step decision-making.
They call these "application-specific failures."
The AI didn't learn how to think. It learned how to pass the test it was trained on.
The paper outlines the paths forward: inference-time scaling, analogical memory, and external verification.
But they are blunt. There are no silver bullets yet.
We need to stop evaluating models based on how often they succeed on static tests, and start injecting known failure cases to see when they break.
Because right now, we are building an entire industry on an illusion.
We are deploying systems that pass benchmarks, but fail reality.
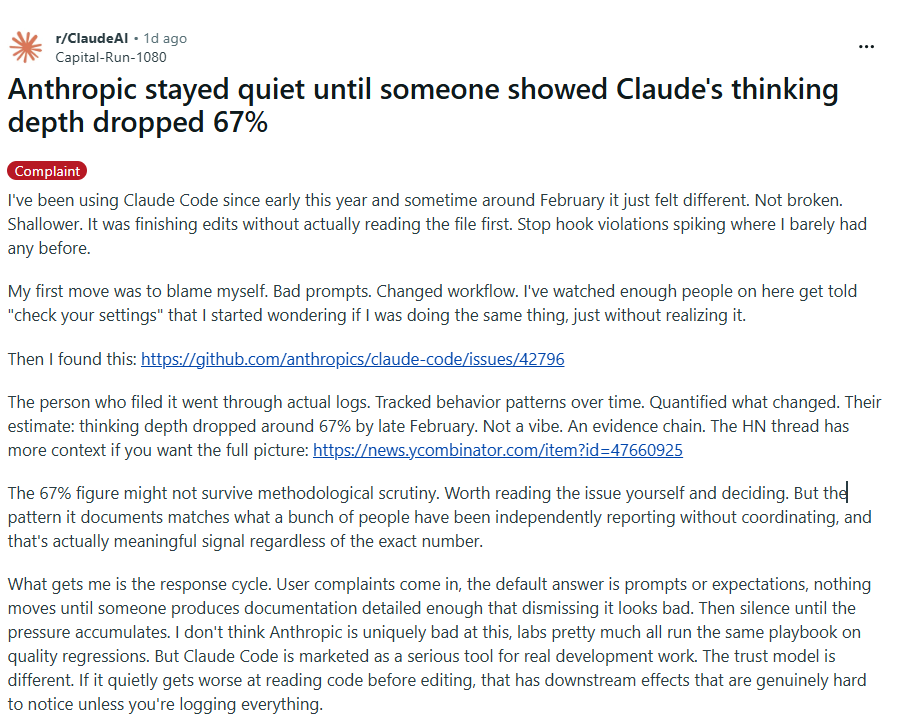
Someone finally put numbers to what developers have been feeling for weeks. The answer: 67%.
An AMD Director of AI analyzed 6,852 Claude Code sessions spanning nearly three months. Not vibes. Not Reddit complaints. Hard session data.
Here’s what the logs show:
→ Thinking depth collapsed 67% by late February before Anthropic hid the reasoning process from users.
→ Code reads per edit dropped from 6.6 to 2.0 Claude stopped researching before touching your files.
→ A stop-hook script catching lazy behavior fired 173 times after March 8. It fired zero times before.
→ API costs ballooned 80x because shallow thinking caused constant wrong outputs, interruptions, and retries.
Anthropic said nothing until the numbers went public.
Then Boris Cherny showed up on the GitHub issue and pointed to a default “thinking effort” setting, quietly lowered to “medium” on March 3 described internally as the sweet spot between intelligence, latency, and cost.
The team tried every effort-flag combination. Still broken.
AMD has since switched to a competing provider.
Users are calling it AI shrinkflation same price, meaningfully less reasoning. Fourteen product releases shipped alongside five outages in March alone.
The parting line from the issue says it all:
“Six months ago, Claude was in a league of its own. Anthropic is no longer the sole player in the capability tier Opus previously occupied.”