Introducing Search as Code, our new search architecture for AI agents.
It writes Python that calls our search stack directly, instead of looping through function calls one at a time.
Available in the Perplexity Agent API, and now default in Computer.
https://t.co/ut6GGWQTVO
New Engineering blog: We tasked Opus 4.6 using agent teams to build a C compiler. Then we (mostly) walked away. Two weeks later, it worked on the Linux kernel.
Here's what it taught us about the future of autonomous software development.
Read more: https://t.co/htX0wl4wIf
Software development is undergoing a renaissance in front of our eyes.
If you haven't used the tools recently, you likely are underestimating what you're missing. Since December, there's been a step function improvement in what tools like Codex can do. Some great engineers at OpenAI yesterday told me that their job has fundamentally changed since December. Prior to then, they could use Codex for unit tests; now it writes essentially all the code and does a great deal of their operations and debugging. Not everyone has yet made that leap, but it's usually because of factors besides the capability of the model.
Every company faces the same opportunity now, and navigating it well — just like with cloud computing or the Internet — requires careful thought. This post shares how OpenAI is currently approaching retooling our teams towards agentic software development. We're still learning and iterating, but here's how we're thinking about it right now:
As a first step, by March 31st, we're aiming that:
(1) For any technical task, the tool of first resort for humans is interacting with an agent rather than using an editor or terminal.
(2) The default way humans utilize agents is explicitly evaluated as safe, but also productive enough that most workflows do not need additional permissions.
In order to get there, here's what we recommended to the team a few weeks ago:
1. Take the time to try out the tools. The tools do sell themselves — many people have had amazing experiences with 5.2 in Codex, after having churned from codex web a few months ago. But many people are also so busy they haven't had a chance to try Codex yet or got stuck thinking "is there any way it could do X" rather than just trying.
- Designate an "agents captain" for your team — the primary person responsible for thinking about how agents can be brought into the teams' workflow.
- Share experiences or questions in a few designated internal channels
- Take a day for a company-wide Codex hackathon
2. Create skills and AGENTS[.md].
- Create and maintain an AGENTS[.md] for any project you work on; update the AGENTS[.md] whenever the agent does something wrong or struggles with a task.
- Write skills for anything that you get Codex to do, and commit it to the skills directory in a shared repository
3. Inventory and make accessible any internal tools.
- Maintain a list of tools that your team relies on, and make sure someone takes point on making it agent-accessible (such as via a CLI or MCP server).
4. Structure codebases to be agent-first. With the models changing so fast, this is still somewhat untrodden ground, and will require some exploration.
- Write tests which are quick to run, and create high-quality interfaces between components.
5. Say no to slop. Managing AI generated code at scale is an emerging problem, and will require new processes and conventions to keep code quality high
- Ensure that some human is accountable for any code that gets merged. As a code reviewer, maintain at least the same bar as you would for human-written code, and make sure the author understands what they're submitting.
6. Work on basic infra. There's a lot of room for everyone to build basic infrastructure, which can be guided by internal user feedback. The core tools are getting a lot better and more usable, but there's a lot of infrastructure that currently go around the tools, such as observability, tracking not just the committed code but the agent trajectories that led to them, and central management of the tools that agents are able to use.
Overall, adopting tools like Codex is not just a technical but also a deep cultural change, with a lot of downstream implications to figure out. We encourage every manager to drive this with their team, and to think through other action items — for example, per item 5 above, what else can prevent a lot of "functionally-correct but poorly-maintainable code" from creeping into codebases.
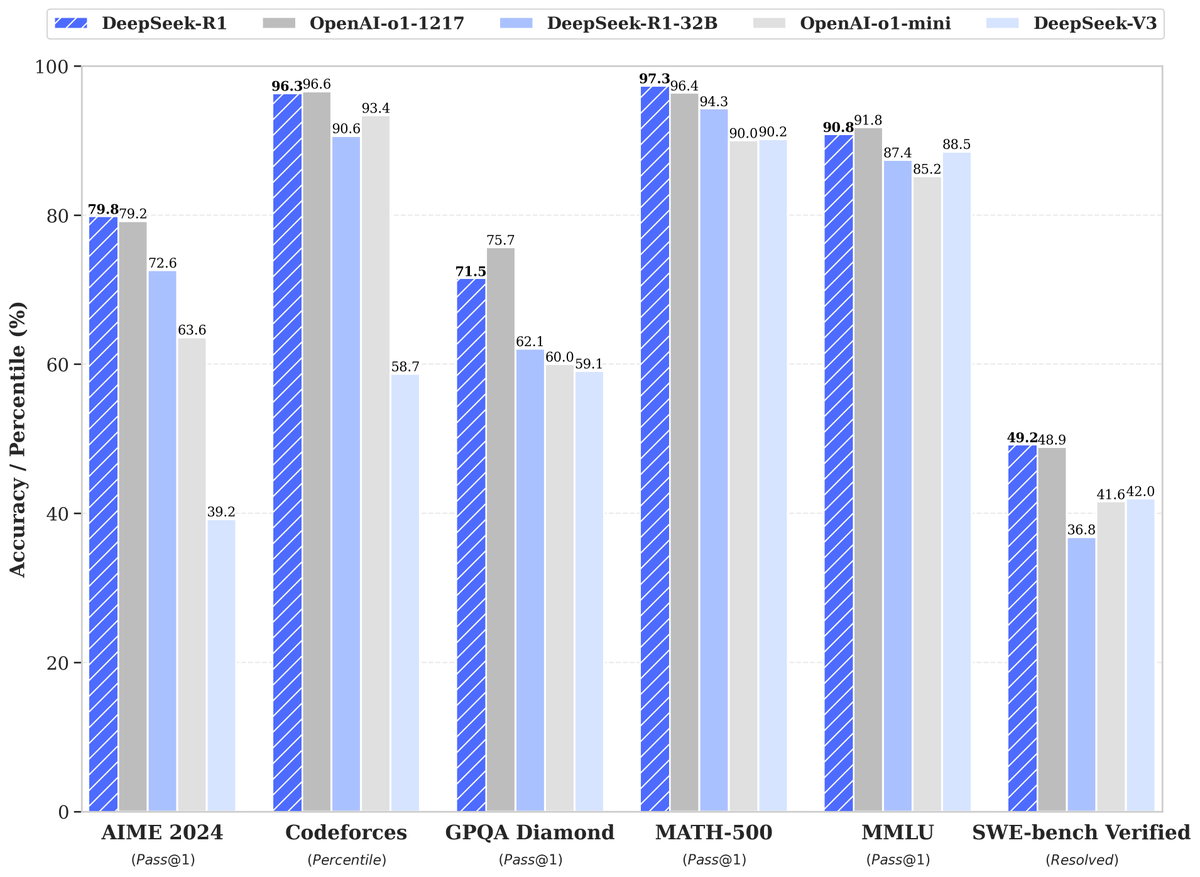
🚀 DeepSeek-R1 is here!
⚡ Performance on par with OpenAI-o1
📖 Fully open-source model & technical report
🏆 MIT licensed: Distill & commercialize freely!
🌐 Website & API are live now! Try DeepThink at https://t.co/v1TFy7LHNy today!
🐋 1/n
NotebookLM is quite powerful and worth playing with
https://t.co/EMHIjc15iU
It is a bit of a re-imagination of the UIUX of working with LLMs organized around a collection of sources you upload and then refer to with queries, seeing results alongside and with citations.
But the current most new/impressive feature (that is surprisingly hidden almost as an afterthought) is the ability to generate a 2-person podcast episode based on any content you upload. For example someone took my "bitcoin from scratch" post from a long time ago:
https://t.co/7ajZNZ0BGi
and converted it to podcast, quite impressive:
https://t.co/ZZn0LJgsnu
You can podcastify *anything*. I give it train_gpt2.c (C code that trains GPT-2):
https://t.co/gDrAqix4Iv
and made a podcast about that:
https://t.co/bgcwmQr5d7
I don't know if I'd exactly agree with the framing of the conversation and the emphasis or the descriptions of layernorm and matmul etc but there's hints of greatness here and in any case it's highly entertaining.
Imo LLM capability (IQ, but also memory (context length), multimodal, etc.) is getting way ahead of the UIUX of packaging it into products. Think Code Interpreter, Claude Artifacts, Cursor/Replit, NotebookLM, etc. I expect (and look forward to) a lot more and different paradigms of interaction than just chat.
That's what I think is ultimately so compelling about the 2-person podcast format as a UIUX exploration. It lifts two major "barriers to enjoyment" of LLMs. 1 Chat is hard. You don't know what to say or ask. In the 2-person podcast format, the question asking is also delegated to an AI so you get a lot more chill experience instead of being a synchronous constraint in the generating process. 2 Reading is hard and it's much easier to just lean back and listen.
25 years ago, knowing "how to google" gave you an edge when it came to being more productive.
Today, it's about prompt engineering and creating AI Agents on platforms like @youdotcom. That gets even more powerful when collaborating.
This marks the beginning of our next chapter: The AI Productivity Engine
We aren't a search engine for links. We're a productivity engine helping knowledge workers accomplish more.
Our AI Agents research, give answers, solve problems, write and run code, create content, and more.
We do this with a relentless focus on accuracy.
We've built a model-agnostic AI Operating System, making any Large Language Model more accurate and trustworthy. Live web access, advanced search capabilities, dynamic prompting, and advanced citation logic ensure reliable, up-to-date information every time.
It's a step function for productivity. Millions of knowledge workers already use us. Over 1B queries served since launch. 500% ARR growth since January 2024
We also just closed a $50M Series B today led by @Georgian_io, with @SalesforceVC, @Nvidia, SBVA, @DuckDuckGo, @DayOneVC, and others, bringing our total funding to $99 million.
Better, better. Never done.
Awesome and highly useful: FineWeb-Edu 📚👏
High quality LLM dataset filtering the original 15 trillion FineWeb tokens to 1.3 trillion of the highest (educational) quality, as judged by a Llama 3 70B. +A highly detailed paper.
Turns out that LLMs learn a lot better and faster from educational content as well. This is partly because the average Common Crawl article (internet pages) is not of very high value and distracts the training, packing in too much irrelevant information. The average webpage on the internet is so random and terrible it's not even clear how prior LLMs learn anything at all. You'd think it's random articles but it's not, it's weird data dumps, ad spam and SEO, terabytes of stock ticker updates, etc. And then there are diamonds mixed in there, the challenge is pick them out.
Pretraining datasets may also turn out to be quite useful for finetuning, because when you finetune a model into a specific domain (as is very common), you slowly lose general capability. The model starts to slowly forget things outside of the target domain. But this is not only restricted to knowledge; You also lose more general "thinking" skills that the original data demanded, but your new domain might not exercise. i.e. in addition to the broad knowledge fading, those computational circuits also slowly degrade. So there are likely creative ways to blend the pretraining and finetuning stages.
Collaboration is vital. We need developers, policymakers, and the public to work together to create ethical AI frameworks that benefit everyone. Let's keep the conversation going! #AIForAll (5/5)
Let's empower users! Can we give people more control over their data and how AI systems interact with them? Opt-in for data collection & clear options to withdraw consent. (4/5)
📣 We're excited to introduce...
DuckDuckGo Privacy Pro: three new protections bundled into one easy subscription. Subscribers get:
✅ An Anonymous VPN
✅ Personal Information Removal
✅ Identity Theft Restoration
Learn more 👇 https://t.co/zGsbS6s3QB
Privacy-focused company DuckDuckGo is launching a tool to remove data from people-search websites, a VPN, and an identity theft restoration service. https://t.co/RJDaxTUrkD
On this day in 2008: DuckDuckGo was launched. 🎉
15 years later, we've built something truly rare in tech: a healthy, profitable company that protects user privacy, instead of exploiting it. 🦆
Chandrayaan-3 Mission:
Chandrayaan-3 ROVER:
Made in India 🇮🇳
Made for the MOON🌖!
The Ch-3 Rover ramped down from the Lander and
India took a walk on the moon !
More updates soon.
#Chandrayaan_3#Ch3