Surprised to see LUA still in use for high grade scientific applications, in modern software it's mostly a sub-scripting tool.
We roll all of those bit precision levels for calculations internally. STEM architecture needs to tighten up before STUXNET2 eventually goes live.
the fast16 malware was almost certainly targeting spherical implosion simulations.
left: unmodified LS-DYNA 970
right: LS-DYNA 970 modified with the relevant portions of fast16.sys
both running a spherical implosion deck
In "benchmarks" for AGI, one should consider independent operation as a major goal. If you can't figure it out standalone, then whatever "general intelligence" you create will always be bottle-fed on the internet.
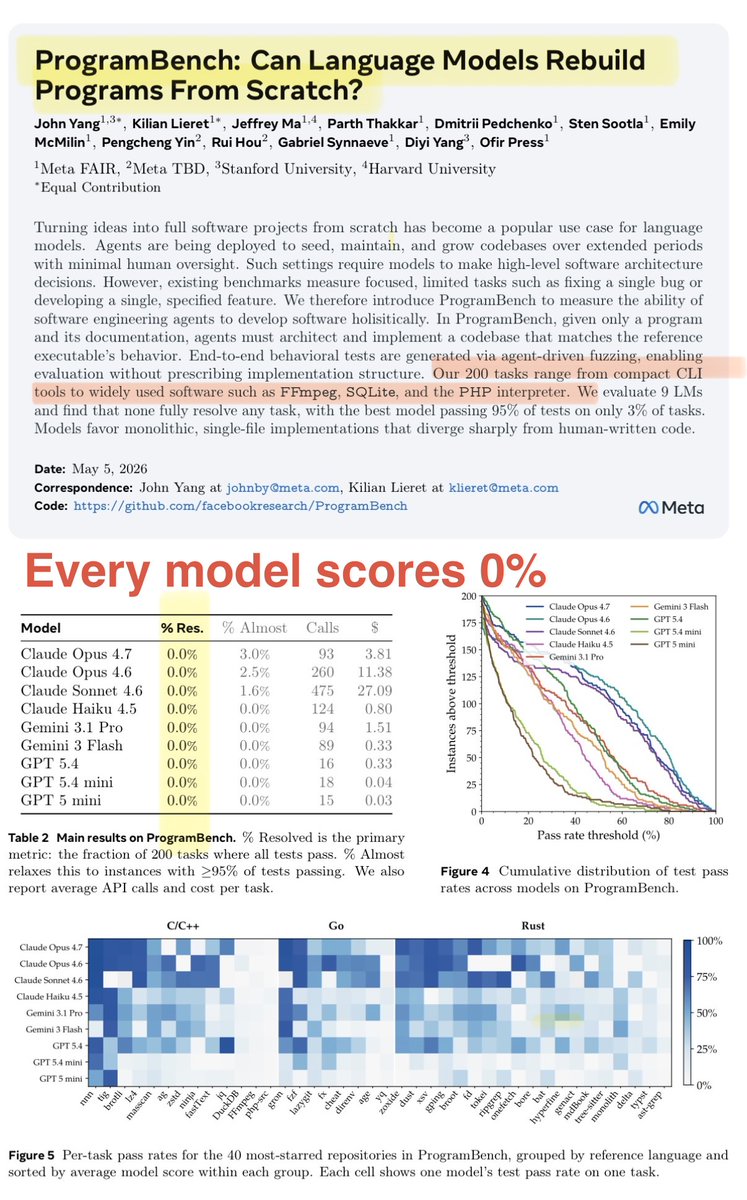
The creators of SWE-Bench just dropped a really simple new benchmark every LLM gets 0% on.
ProgramBench asks: can models recreate real executable programs (ffmpeg, SQLite, ripgrep) from scratch with no internet?
We are far from saturated on model quality.
@CDAODoW SILVIA is a deterministic cognitive operating system. Identical inputs produce bit-identical execution. Every decision carries a cryptographically-signed audit trail.
No hallucinations. No black boxes. No guessing.
All in .NET
One curve.
Three projections.f(t) = e^{-γ(t-t₀)²} ⋅ e^{iωt}
From the Re-t plane: damped cosine.
Im-t: damped sine.
Re-Im: perfect inward spiral.Same reality, different slices.
@weezerOSINT Virus Protection has begun to work inversely for defense just as VPNs have now made people who want to be secretive easier to compile into one big list of suspects.
@mathelirium Good breakdown.
So in evaluations beyond the bounds of the phase space of the flow you're trying to graph, do you get a zero back on the density?
🚨 Microsoft Defender 0-Day Vulnerability “RedSun” Enables Full SYSTEM Access
Source: https://t.co/s1vfh5GLcg
A newly disclosed zero-day vulnerability in Microsoft Defender, dubbed "RedSun," allows an unprivileged user to escalate privileges to full SYSTEM-level access on fully patched Windows 10, Windows 11, and Windows Server 2019 and later systems, and as of now, remains unpatched.
RedSun is the second zero-day exploit published within a two-week span in April 2026 by the security researcher known as "Chaotic Eclipse" (also referred to as Nightmare-Eclipse on GitHub).
RedSun follows the same exploit tradition but introduces an entirely new and independent attack vector, suggesting that Defender's architectural weaknesses run far deeper than a single isolated flaw.
#cybersecuritynews #Windowsdefender
Organoids are quietly becoming a big futuretech issue. It's difficult to take a cogent position on it.
In the case of a human-organoid I'd be worried about where to put the labor law poster. There is no break room.
Someone actually connected living human brain cells to an LLM.
Cortical Labs grew 200k neurons on a chip, taught them to play doom, and now they are wiring them into the token-selection process of an AI.
❗️ Mozilla just called out Microsoft for force-installing Copilot on Windows systems without user consent.
After user backlash, Microsoft partially rolled Copilot back.
Mozilla: "In the most recent case, they let their AI learn and collect data as fast as possible before people had a choice."
🚨 Stanford just published the most uncomfortable AI paper of the year.
They just dropped a systematic teardown of how large language models actually "think."
It proves that passing a benchmark has almost nothing to do with real reasoning.
We have spent years optimizing for tests.
But the researchers found that performance does not transfer nearly as well as the leaderboards imply.
A model that looks incredibly strong on a math benchmark will quietly fall apart when asked to do scientific reasoning, planning, or multi-step decision-making.
They call these "application-specific failures."
The AI didn't learn how to think. It learned how to pass the test it was trained on.
The paper outlines the paths forward: inference-time scaling, analogical memory, and external verification.
But they are blunt. There are no silver bullets yet.
We need to stop evaluating models based on how often they succeed on static tests, and start injecting known failure cases to see when they break.
Because right now, we are building an entire industry on an illusion.
We are deploying systems that pass benchmarks, but fail reality.