A lot of routing work evaluates isolated prompts, but real agent systems are fundamentally multi-step and budget-constrained. Cool to see benchmarks moving toward execution-grounded, end-to-end evaluation instead of just token-level proxies.
TwinRouterBench is a strong step toward realistic agentic routing evaluation — especially the separation between static supervision and dynamic SWE-bench execution. Excited to see where this goes!
Great to see TwinRouterBench accepted to the #RLEval Workshop at #CAIS2026!
Per-step routing is quickly becoming essential infrastructure for agentic systems: each planning, coding, retrieval, and verification call should use the cheapest sufficient model without hurting final task success.
Proud to open-source TwinRouterBench and contribute a practical benchmark for this problem.
Excited to share that TwinRouterBench has been accepted to the #RLEval Workshop at #CAIS2026 🎉
As LLM apps become long-horizon agents, one request can trigger many model calls across planning, tool use, retrieval, coding, and verification.
That makes per-step LLM routing a core infrastructure problem: sending each call to the cheapest sufficient model without breaking downstream success.
TwinRouterBench introduces:
⚡ Static track: 970 router-visible prefixes from 520 instances across SWE-bench, BFCL, mtRAG, QMSum, and PinchBench
🚀 Dynamic track: live SWE-bench Verified evaluation with official task resolution + realized API spend
Key result: a router trained on static labels achieves comparable SWE-bench resolve rate while cutting API cost by ~53% vs. an unrouted Opus 4.6 baseline.
Paper: https://t.co/dVZaZvvUk5
Code: https://t.co/ZRnswiW3T7
Dataset: https://t.co/65l1rEcOs7
Website: https://t.co/O45KZwLPCt
#LLM #AgenticAI #LLMRouting #Benchmark #SWEBench
Step-level routing matters. The benchmark to measure it is open today.
Bench: https://t.co/cCyKNLxuKl
The current leader: https://t.co/6bJ9Whu8UA
Paper coming soon on ArXiv.
How do you evaluate an LLM router fairly?
Most benchmarks look at prompts, but routers operate at an agentic-step level. A router that saves money but breaks the task could be worse than no router.
We open-sourced TwinRouterBench to measure this honestly.
🧵
Conflict of interest? acknowledged!
We know our router (UncommonRoute) currently leads the leaderboard.
Open submissions, locked pricing, public scoring code. If a different router wins, the leaderboard will say so.
Run Claude Code with Commonstack in 4 steps:
- generate an API key
- set 4 environment variables
- run claude
- /status to verify
Set it up now in 5 minutes with @alex_mirran.
GPT-5.5 is live on https://t.co/L4uejEYZ40! 🚀🚀
Use the strong reasoning and coding capabilities of GPT-5.5 in your application or with your favorite agentic harness.
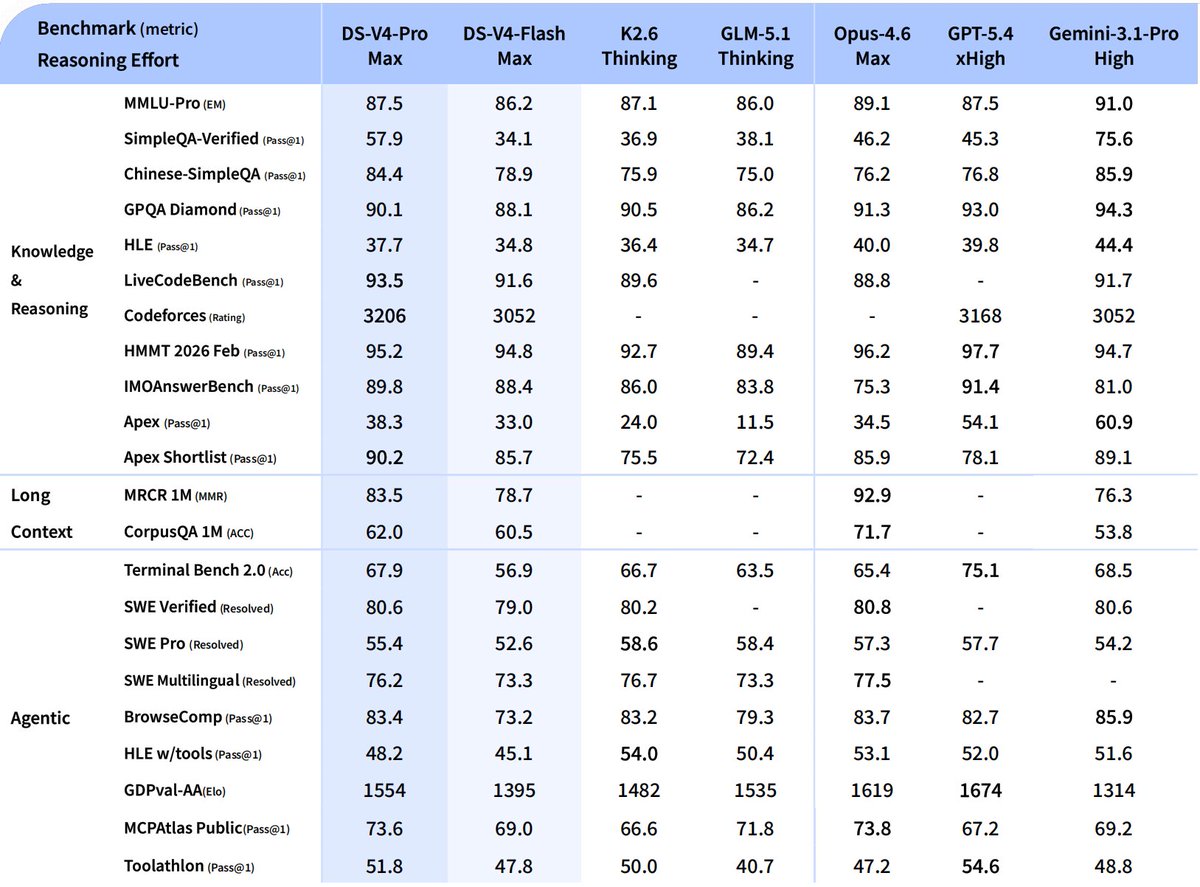
DeepSeek-V4-Flash
🔹 Reasoning capabilities closely approach V4-Pro.
🔹 Performs on par with V4-Pro on simple Agent tasks.
🔹 Smaller parameter size, faster response times, and highly cost-effective API pricing.
3/n