@HowToAI_ Yep. That Qwen wrapped in some scaffolding. Try generating a dialog of a few turns. Voice is sounding remotely like the sample and there’s no way to make it better. The stability of the generation is meh and is not really useful for anything besides 5-10-word phrases, maybe ads
189 releases = sorry I can’t really test it well as requirements don’t change that fast.
All integrations done = 90% were never tested in a real scenario
Elastic , not MIT = I am not sure how but I would like to earn money with my vibecoded thing :-)
SaaS company doesn’t pay for the code, it pays for a reliable tested access to the data or functionality so that they can focus on their core, not fix/debug “elastic dependency”
Not as a gloat, just a remark: natural selection works.
And magic wands do not exist.
Everyone knows the rules and yet agentic flows are being treated like one works with a human. You are not. It is a single API call to a LLM that predicts the next token based on the previous ones.
Disasters like this are bound to happen because there’s no “intelligence” that makes a “decision” there.
i've been working on llm memory systems for 3 years and dumped everything i know into this.
learn about the 9 axes of memory systems, the 10 most common failure modes, why memory eval is an intractable problem, and more.
everyone building with llms should read this.
One HN commenter wrote "I might as well be using Haiku." He meant it as a hypothetical.
Two workarounds exist. Neither is clean. Running the override now -- still seeing some Haiku in telemetry.
https://t.co/N7won22eNZ
Opus was throwing 500 errors yesterday. Switched to Sonnet, figured I'd finally set up the OTEL pipeline I'd been putting off.
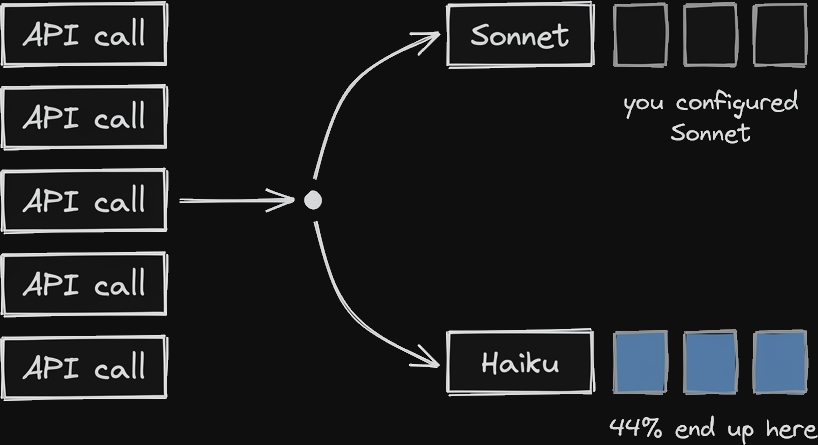
First thing the dashboard showed: 95% of my API requests were going to Haiku.
I had model: sonnet configured everywhere.
Worse: 331 of those complex calls had cache reads averaging 79K tokens. Not stateless. Reading your full conversation context on the cheapest model.
/stats doesn't count subagent models. At all. Confirmed bug, GitHub #17692, tagged for auto-close.
I don't have good answers yet. Every configuration I sketch out trades one unfairness for another.
Wrote up where I've landed so far — impossibility theorem, the HFT parallel, and why "bring your own bot" creates different problems.
https://t.co/NI8V6t6pFM
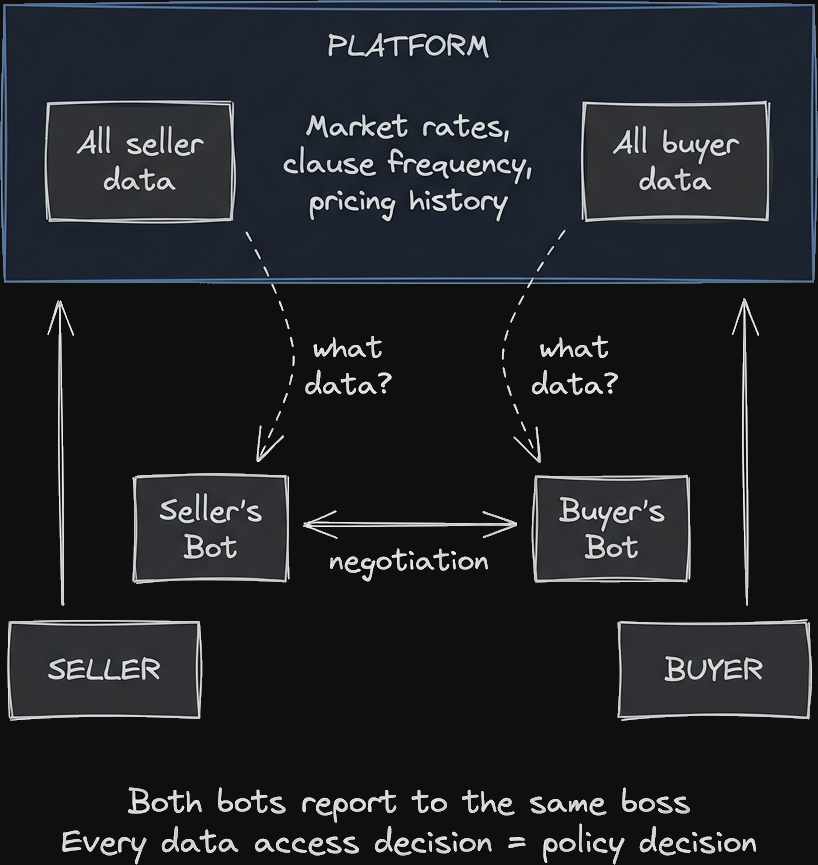
Building advisory bots for both sides of a services marketplace. Seller bot reviews contracts, suggests negotiation points. Buyer bot does the same from the other side.
We built both. We control both prompts. We choose what data each one sees.
The research numbers make it worse. Weaker agents cost users up to 14% more (Stanford HAI). GPT-4o accepted the first proposal 100% of the time in Microsoft's marketplace experiment.
The agents aren't negotiating. They're satisficing.
Why didn't "throwing money at the problem" work?
The recommendation from the top labs is "Agent is smart, ot will figure it out, let it run". It kinda does, but you pay for all that.
It is like letting a junior figure it out instead of giving guidance.
Expensive and inefficient
@arscontexta Cool idea. I did some work on the skill creation that takes advantage of the best practices and connectivity is one of the idea. That said, wiki links aren’t processed by Claude as we want. So the recommendation is to link by the skill id(name)