Disappointing. Timid, backward-looking recommendations completely inadequate to the moment, with a side-helping of peevish, finger-wagging self-interest. If this is how the mathematical community chooses to respond, it will be completely overtaken by what's coming.
https://t.co/hBJl8M3Dl6
Grok CLI is an excellent harness, and Composer 2.5 is a good, fast workhorse for quick refactoring (though too weak for deep work). I'm reaching for it more and more, which is surprising me.
Second, Codex used to be the model I could set to work without worrying about running out of a $200 subscription. Now, my data shows Claude is the model that I can set to work at a rate of about 10% of weekly quota per day, while for the same work Codex will eat 30% and run out.
Two flippenings, in two directions. First, Claude used to be more personally pleasant than Codex. Now it's a nitpicky, unenthusiastic, perpetually caveating scold. Codex is still a low-affect worker bee but I can work with that.
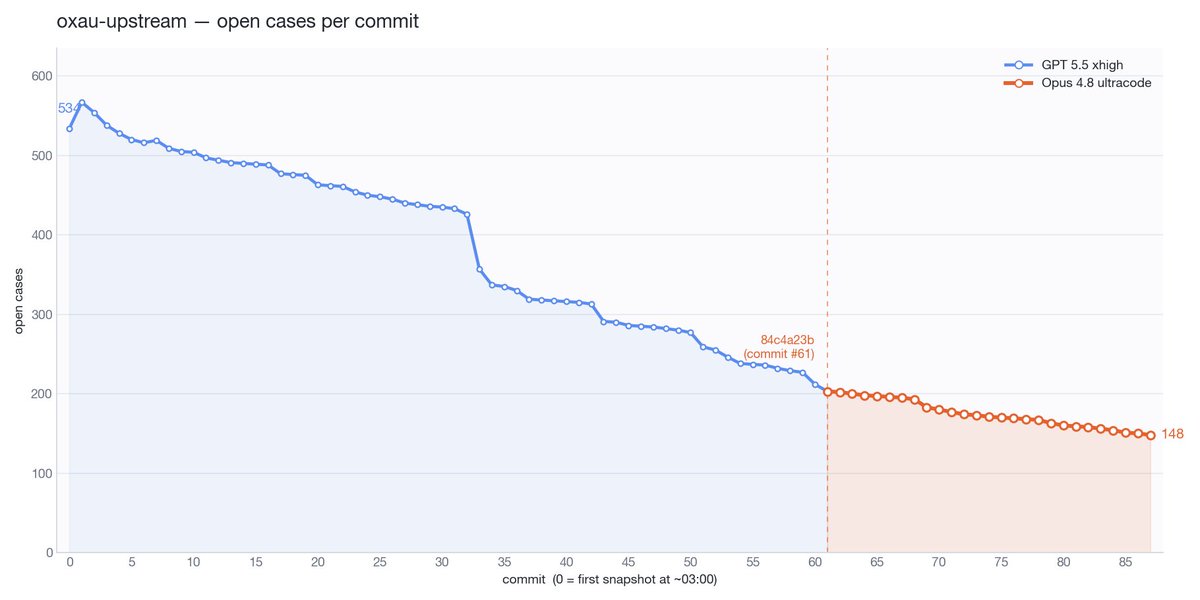
And here are the same graphs in term of wall-clock time. Interpret with caution because a) GPT got to reap the big wins early on, b) I stopped Claude 4.8 often in its early run for subjective code evals. I'd say this nets out to roughly the same progress slope.
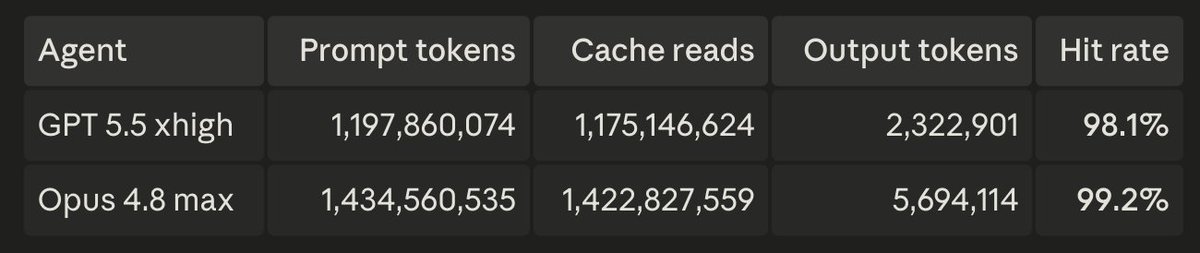
One fascinating finding. Both agents are on their respective $200 tiers. Opus is using about 1/10th of the weekly quota per day on max thinking, while GPT 5.5 is using about 1/4 weekly quota per day on xhigh. Unexpected.
The longer term of my Opus 4.8 comparison actually looks a bit more flattering. Clearing issues roughly inline with GPT 5.5, in a domain where all the big wins have been reaped.
More data in my ongoing Opus 4.8 vs GPT 5.5 task clearing runoff. Agents are doing a very large C++ to Rust port. The tasks are extracted unit tests from upstream that need to give the same result in our Rust type checker. Deep in diminishing returns now.
This can be completely explained by how the interaction is framed in terms of the training corpus and doesn't require any reasoning about model agency, consciousness or personality.
It's my firm belief that many people get sub-optimal results because they're rude or abusive to the models. In the age of AI, nicer people also produce better code.
@snesworld90 I mean, this is surely because of some nonsense you have in your system prompt or memory, right? Did this 10x, and all responses were reasonable.
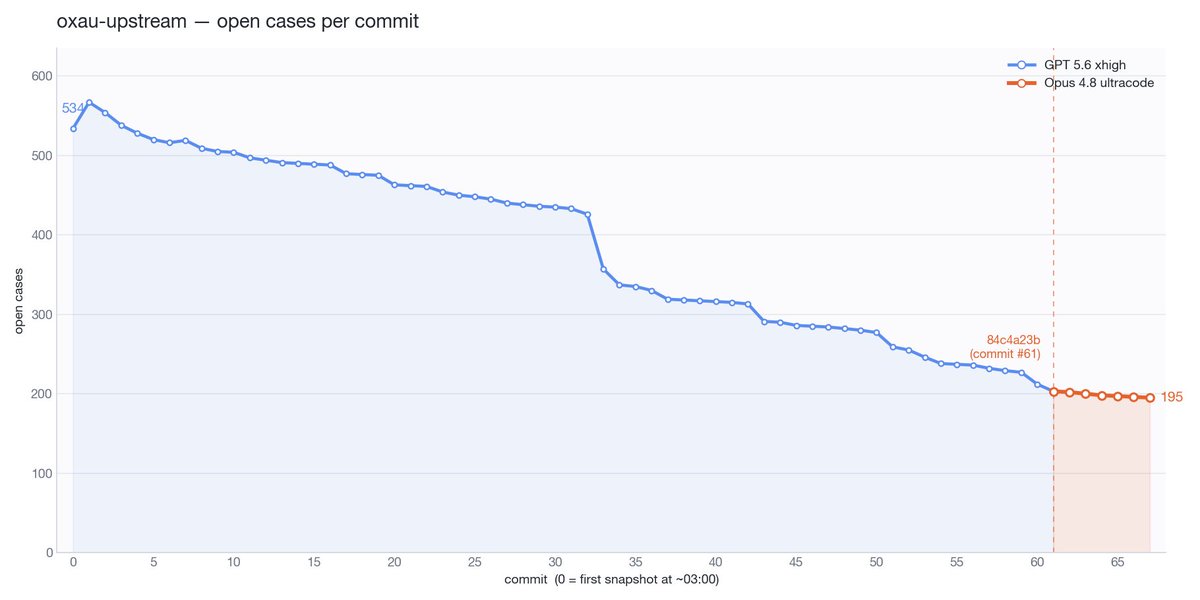
And here are the same graphs in term of wall-clock time. Interpret with caution because a) GPT got to reap the big wins early on, b) I stopped Claude 4.8 often in its early run for subjective code evals. I'd say this nets out to roughly the same progress slope.
More data in my ongoing Opus 4.8 vs GPT 5.5 task clearing runoff. Agents are doing a very large C++ to Rust port. The tasks are extracted unit tests from upstream that need to give the same result in our Rust type checker. Deep in diminishing returns now.
Early data on Opus 4.8. I switched a task queue for a complex project over from GPT 5.6. Case resolution progress slowed down... BUT the patches read very well and show taste - often including strong consolidation and code quality improvements.
The longer term of my Opus 4.8 comparison actually looks a bit more flattering. Clearing issues roughly inline with GPT 5.5, in a domain where all the big wins have been reaped.