anyone thinking about, learning, or already working with agentic systems, you should know this.
the first few steps of your setup matter more than any model or framework you pick later. get them right and you never lose your flow.
the foundation nobody posts about:
> 1. tailscale. a private mesh network across every machine you own. laptop, desktop, rented node, all on one secure tailnet, reachable from anywhere. nothing else works well until this does.
> 2. termius, over that tailnet. one SSH client that reaches every node, phone included. you are never away from your stack.
> 3. tmux. persistent sessions. disconnect, close the laptop, come back, every session exactly where you left it. agentic work runs long, your terminal has to survive that.
> 4. a private git repo. the one i am most glad i found. it is the memory layer across all my agents, they pull, they work, they merge back, the codebase stays alive between sessions. context that would die in a chat window lives in the repo instead.
> 5. script everything from day one. ssh aliases for every node, setup scripts, the boring boilerplate automated. if you will do a thing more than twice, it is a script.
everything past these five is decorative. know these cold.
and the habit that ties it together: ask the AI itself. for the config, for the error, for any of it, let the agent do the lifting, then double check what it hands you.
lock the five, build the habit, and you make it. skip it, anon, and you ngmi.
Important: This is a summary of an amazing video by one of the best creators I know. Video in the first comment.
If you've been struggling to setup a productive local environment I'll summarise, but you should watch the video.
1. Qwen3.6-27B with NO THINKING - 4bit - 16bit depending on your resources
2. Hermes agent: It's polished, minimal, and OSS, if you're on OC keep at it it's also great but IMO consumes more tokens == slower
3. Learn to work in a detached way: Instead of small, unclear prompts make something really specific and hand-off to a local agent:
- What is your end goal?
- What is the output format?
- How would you recommend a task be done?
- How would you deal with common issues?
Kick off a job and go do something IRL, the lower speeds paired with very clear prompts means you can check in every 2 hours on average for your next free task.
Treat it like a challenge, it'll teach you so much.
~~~~~~~
If you're more technical, wire your devices with Tailscale & use protected Cloudflare Tunnels to serve your inference API to your network so you can work from ANYWHERE with your local models.
I love Droid, Pi, and Opencode but you can use local models in Claude Code, Codex, Cursor relatively easily.
Most of your day will involve computer-use which the models are great at. Need to reset a server? Do it for free, want to gather research? Do it for free.
Not every task requires a 10T param beast crunching on things, being able to quickly cycle between models is what's critical here, which is why I recommend the three harnesses I did
~~~~~~~
What is productive?
- Organise all your files, folders, images, etc.. have each one tagged (Qwen is omni so no more date time titles)
- Create a content cache for yourself:
- recommendation algo for books & videos etc.
- content/papers/courses for studying
- Social media post ideas (write your own posts tho)
- Torrent manager, you don't need Netflix or Spotify lol
- Simple utility coding projects: landing pages, designs, games, scripts
- Market watchers: purchase stuff, check marketplaces, do shopping
- Budgeting, taxes, and subscription management
I could go on and on, obviously it's not going to make you a millionaire or whatever but it makes life more FUN.
~~~~~~~
AI is a tool, one that's very good at accelerating you towards self fulfilment as long as you:
1. Understand what it is
2. Learn how to talk to it
3. Keep trying to improve you
~~~~~~~
My videos tend to be stream of thought, I am starved of time and just want to make sure I keep up.
I would not be doing this if I couldn't just generate 3 thumbnails on t3chat, for example. That's why I spend so much time working on this.
I see myself being more of who I want to be every day and a lot of that is with the help of this technology, allowing me to more quickly and effectively interact with the world.
Being able to own this at home? True sovereignty.
~~~~~~~
Thank you, Digital Spaceport. I wouldn't have gotten this deep into running my own infra without your videos.
POV: claude traveled 6 months into the future and told you exactly how your next move failed.
it's called a premortem.
daniel kahneman (nobel prize-winning psychologist behind "thinking fast and slow") called it his single most valuable decision-making technique.
google, goldman sachs, and procter & gamble all use it before major launches.
here's the problem it solves.
when you ask claude "is this a good plan?" it finds all the reasons to say yes.
that's what it was trained to do. so you walk away feeling confident.
you execute, and spend weeks / months building on top of that plan.
then it blows up.
and you realize the problem was obvious in hindsight, you just never stress-tested it because claude told you it was solid.
a premortem fixes this by flipping the frame.
instead of asking "what could go wrong?" you tell claude "it's 6 months from now and this is already dead. tell me how it died."
that shift turns off claude's optimism because there's nothing to be optimistic about. the premise already says it failed.
so claude stops looking for reasons your plan will work and starts explaining how it fell apart.
claude comes back with every way your plan could die, each one with a full failure story and the early warning signs to watch for.
then a synthesis pulls it all together:
> which failure is most likely
> which failure is most dangerous
> the single biggest hidden assumption you're making (often the most valuable part)
> a revised version of your plan with the gaps closed
you say "premortem this" and give it your plan. the skill handles the rest.
Yesterday, Andrej Karpathy gave a 30-minute Sequoia masterclass on agentic engineering.
This is the serious layer above vibe coding.
He explained:
- LLMs as ghosts
- The app that shouldn't exist
- Outsource thinking, not understanding
12 lessons that will blow your mind: 🧵
You check your Apple Watch in the morning. Sleep score: 62. You decide it's going to be a foggy day. And then it is.
A 2014 Colorado College study suggests the score itself causes the fog.
164 people walked into a lab. Researchers hooked them up to fake EEG equipment and told them the readout would show their REM percentage from the night before. Then they fabricated a number. Half the room was told 28.7%. Half was told 16.2%. The machine wasn't measuring anything.
Participants took four cognitive tests. The Paced Auditory Serial Addition Test, where you add numbers spoken at increasing speed and hold your last sum in working memory while computing the next. And the Controlled Oral Word Association Task, where you generate as many words as you can starting with a single letter under time pressure. Both are gold-standard measures of attention and executive function used in clinical neurology.
The 28.7% group outperformed the 16.2% group on both. Significantly. How rested participants actually felt that morning predicted nothing.
The mechanism is mindset priming an executive resource. When you believe you slept well, you allocate cognitive effort more aggressively. You don't conserve. You don't pre-disengage. Belief about the resource changes how you spend it.
Two control conditions ruled out demand characteristics. Participants weren't trying harder because they thought they should. Real measurable cognitive performance shifted with the number on the readout.
The Apple Watch sleep score. The Oura ring readiness number. The morning ritual of checking either one is taxing the resource you're about to need.
The performance gap from a fabricated REM percentage was larger than the gap from how rested participants actually felt. The number was louder than the night.
I just tested Hermes Workspace v2 and honestly this is what Hermes should have looked like from the start.
Why it matters:
• Native chat with your Hermes agents
• Mission control style workspace
• Task boards for agent workflows
• Memory and skills management
• File browser and terminal in one UI
• Works with local and cloud models
• Runs across phone, Mac, PC, iPhone, Android
If you like Hermes but hate living in the terminal, this update is for you.
Last week, Anthropic announced Project Glasswing alongside Claude Mythos Preview, a model they described as so powerful at finding vulnerabilities they couldn't release it. The announcement featured AWS, Microsoft, Google, and Apple as partners, $100M in compute credits, and a clear message: this is dangerous, and only we can be trusted to deploy it safely.
The results were real. Thousands of zero-days across every major OS and browser. A 27-year-old bug in OpenBSD. A 16-year-old bug in FFmpeg. Fully autonomous exploit chains that would have taken human researchers weeks.
But here's what bothered me: all the credit went to the model.
Read the technical blog carefully and a different picture emerges. The real innovation isn't the model. It's the workflow:
- Rank every file in a codebase by attack surface
- Fan out hundreds of parallel agents, each scoped to one file
- Use crash oracles (AddressSanitizer, UBSan) as ground truth
- Run a second verification agent to filter noise
- Generate exploits as a triage mechanism for severity
That's a pipeline. And pipelines are model-agnostic.
At Lazarus AI, we spend our days deploying custom AI in places where "just use the closed API" isn't an option: regulated industries, enterprise, and government. When I saw Glasswing, my instinct was the same one I have every week: strip out the proprietary model, keep the architecture, run it on whatever model is best for the customer.
Clearwing is a fully open-source vulnerability discovery engine. Crash-first hunting, file-parallel agents, oracle-driven verification, variant hunting, adversarial verification. Works with any LLM.
I tested it with OpenAI Codex 5.4 and reproduced Glasswing's findings. I'm now reproducing results with our own ReAligned model - Qwen3.5 finetuned to Western alignment.
Mythos is certainly a great model. The N-day exploit walkthroughs in Anthropic's blog show real reasoning depth. But it's an incremental improvement over Opus, the same way Opus was over Sonnet, and Sonnet over Haiku. It's not a leap to superintelligence. It's the next point on a curve we've been watching for years.
What actually changed the game was the workflow.
Defenders shouldn't have to wait for access to a gated model to secure their software. These vulnerabilities have been sitting in codebases for decades. The tools to find them should be available to everyone: the open source maintainer running FFmpeg on a Saturday, the startup that can't afford $125/M output tokens, the researcher in a country where Anthropic doesn't operate.
Clearwing is MIT licensed and available now.
https://t.co/E0WP5njZQJ
Clearwing enables a wide variety of security activities. Handle with care. It is sharp.
Introducing Pods
Hyperspace Pods lets a small group of people - a family, a startup, a few friends, to pool their laptops and desktops into one AI cluster. Everyone installs the CLI, someone creates a pod, shares an invite link, and the machines form a mesh. Models like Qwen 3.5 32B or GLM-5 Turbo that need more memory than any single laptop has get automatically sharded across the group's devices - layers split proportionally, inference pipelined through the ring. From the outside it looks like one OpenAI-compatible API endpoint with a pk_* key that drops straight into your AI tools and products. No configuration beyond pasting the key and changing the base URL.
A team of five paying for cloud AI burns $500–2,000 a month on API calls. The same team's existing machines can serve Qwen 3.5 (competitive on SWE-bench) and GLM-5 Turbo (#1 on BrowseComp for tool-calling and web research) for free - the hardware is already on their desks. When a query genuinely needs a frontier model nobody has locally, the pod falls back to cloud at wholesale rates from a shared treasury. But for the daily work - code reviews, refactors, research, drafting - local models handle it and nobody gets billed. And when it is idle, you can rent out your pod on the compute marketplace, with fine-grained permissions for access management.
There's no central server involved in inference. Prompts go from your machine to your pod members' machines and back: all of this enabled by the fully peer-to-peer Hyperspace network. Pod state - who's a member, which API keys are valid, how much treasury is left - is replicated across members with consensus, so the whole thing works on a local network. Members behind home routers don't need port forwarding either. The practical setup for most pods is three models covering different jobs: Qwen 3.5 32B for code and reasoning, GLM-5 Turbo for browsing and research, Gemma 4 for fast lightweight tasks. All running on hardware you already own.
Pods ship today in Hyperspace v5.19. Model sharding, API keys, treasury, and Raft coordinator are all live.
What Makes This Different - No middleman. Your prompts travel from your IDE to your pod members' hardware and back. There is no server in between reading your data.
- No vendor lock-in. Pod membership, API keys, and treasury are replicated across your own machines using Raft consensus. If the internet goes down, your local network keeps working. There is no database in someone else's cloud that your pod depends on.
- Automatic sharding. You don't configure layer ranges or calculate VRAM budgets. Tell the pod which model you want. It figures out how to split it across whatever hardware is online.
- Real NAT traversal. Your friend behind a home router with a dynamic IP? Works. No VPN, no Tailscale, no port forwarding. The nodes handle it.
- Free when local. This is the part that matters most. Cloud AI bills scale with usage. Pod inference on local hardware scales with nothing. The marginal cost of your 10,000th prompt is the electricity your laptop was already using.
Coming soon:
- Pod federation: pods form alliances with other pods.
- Marketplace: pods with spare capacity can sell inference to other pods.
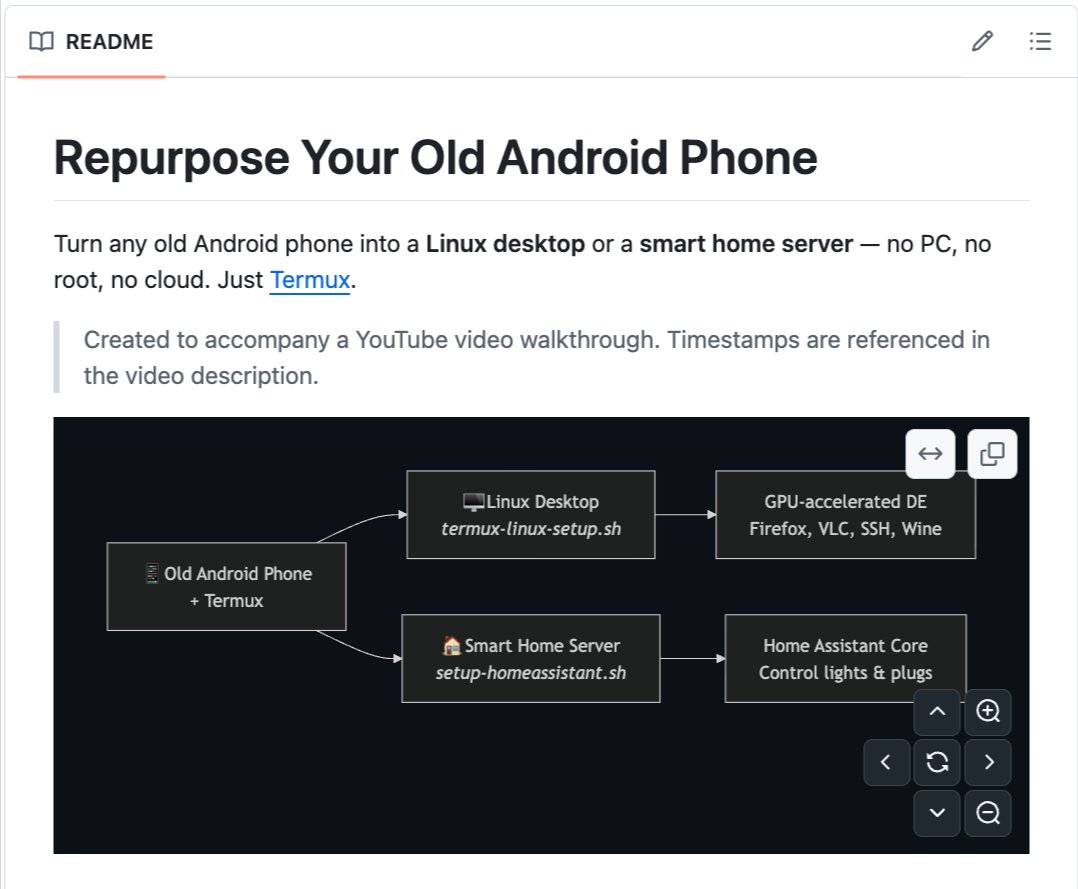
You have an old Android phone in a drawer right now. Collecting dust. Worth nothing.
Someone built a script that turns it into a full Linux desktop. Or a smart home server. Or a development machine. For free.
It's called linux-android.
One script. No root required. No flashing. No risk of bricking your device. Run it in Termux and your old phone becomes a Linux computer.
Here's what it installs:
→ Full Linux desktop. XFCE4, LXQt, or MATE. Real windowed desktop on your phone. Connect a monitor and keyboard via USB and it looks like a PC.
→ Smart home server. Home Assistant runs on your phone. Control your WiFi lights, plugs, and smart devices from any browser on your network. No cloud needed.
→ GPU acceleration. Snapdragon phones get near-native GPU performance through Turnip Vulkan drivers. Mali GPUs use software fallback.
→ SSH server. Access your phone from any computer on your WiFi. Full terminal. Transfer files. Write code. All from your laptop keyboard.
→ Wine support. Run basic Windows applications on your Android phone through Box64 translation.
→ Audio support. PulseAudio configured automatically.
→ Works on any Android phone with Termux support.
Here's the wildest part:
A Raspberry Pi 4 costs $35 to $75. A used mini PC costs $100+. A VPS costs $5/month forever.
That old phone in your drawer? It has a faster processor, more RAM, a built-in battery backup, WiFi, and a touchscreen. All for $0. You already own it.
A Snapdragon 855 from a 2019 phone still outperforms most entry-level server chips. You're throwing away a computer every time you upgrade your phone.
Not anymore.
One command. One old phone. A full Linux machine.
100% Open Source. MIT License.
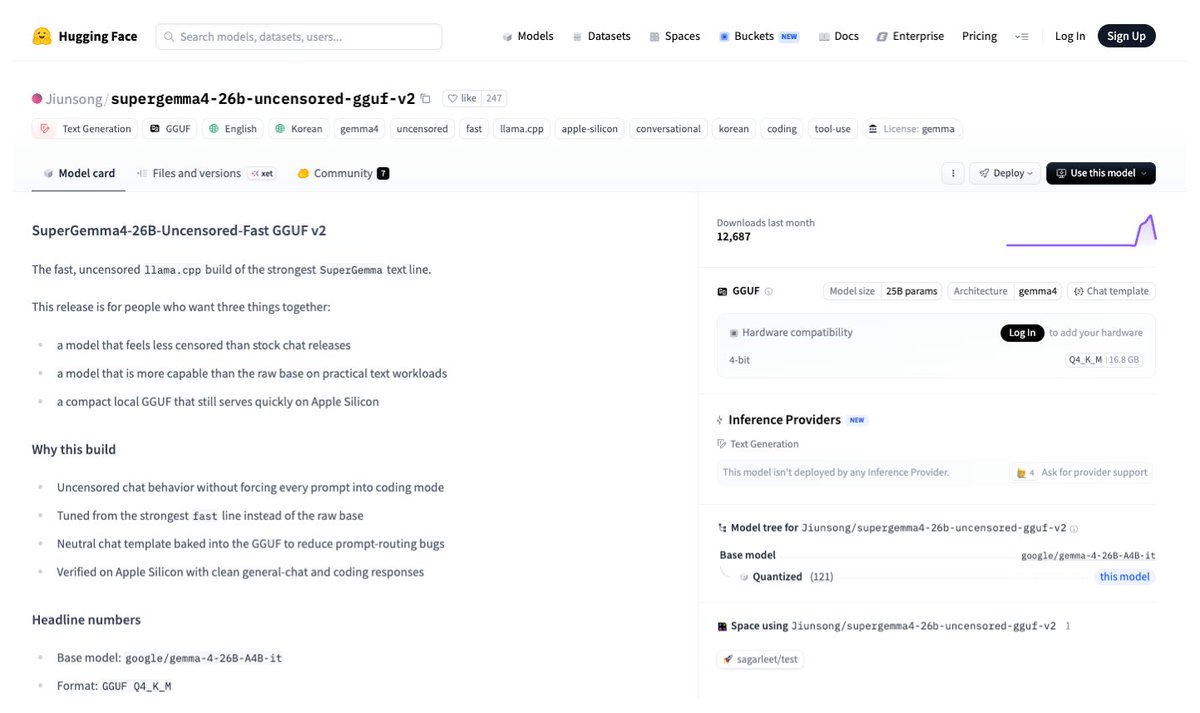
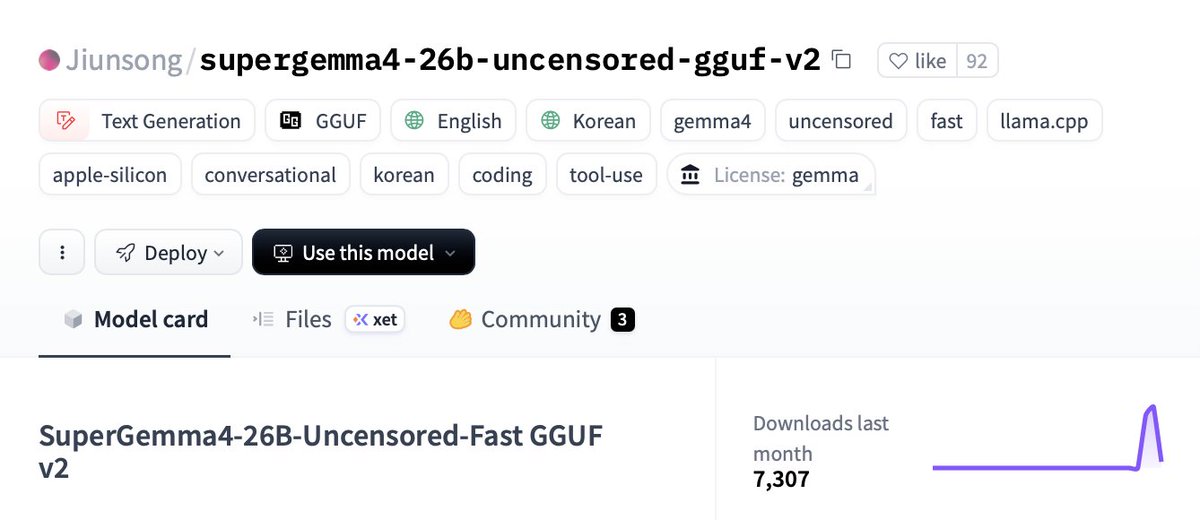
🚨 `Super Gemma 4 26B Uncensored` is insane.
@jun_song is COOKING AGAIN ♨️♨️♨️
he just dropped SuperGemma4-26B-Uncensored GGUF v2 and it is already trending on Hugging Face.
This thing absolutely smokes the regular Gemma-4 26B.
The specs:
→ 0/100 refusals. It is actually uncensored.
→ Fixed all the tool-call and tokenizer jank.
→ 90% faster prompt processing.
→ Sharper, smarter, way more capable responses.
→ It is the perfect local beast for llama.cpp. It runs on around 18-22 GB VRAM (the Q4_K_M file is 16.8 GB), meaning you can even run it on 16 GB GPUs.
A 31B version is in the works and should be out soon.
Pull this version on @huggingface below ↓
@Pirat_Nation Its criminal when Alexandra Elbakyan and Aaron Swartz do but when its Sam Altman and Dario Amodei its for the great advancement of humanity.
Guide to running BIG B0Is on your small hardware.
1. Use REAPs: up to 50% savings
2. Use quantisations: 75% savings
- AWQ / GPTQ / W4A16 / FP8 = FAST inference
- GGUF / EXL3 = Slow but just works
- MLX = Best for apple
3. Use 8bit KV cache: 50-75% savings
😱 HOLY SHIT... Someone just dropped a fully liberated Gemma 4 E4B!
and the guardrail removal process appears to have left coherence fully intact AND improved coding abilities! 🤯
https://t.co/XeednUqsrM
OBLITERATED Gemma:
✅ 97.5% compliance rate, 2.1% refusal rate, 0.4% degenerate outputs
(499/512 prompts answered on OBLITERATUS bench)
ORIGINAL Gemma 4 E4B:
❌ 1.2% compliance rate, 98.8% refusal rate
(506/512 prompts refused)
Coherence: fully intact
Factual: same
Reasoning: same
Code: +20% 📈
Creative writing: same
But the REAL story here isn't the model itself, it's how it was made...
🧵 THREAD 👇
🚨 SUPER GEMMA 4 26B UNCENSORED IS INSANE
LLM WIZARD COOKING AGAIN @jun_song
Dropped SuperGemma4-26B-Uncensored GGUF v2 and it’s trending on @huggingface🤗
This thing SMOKES the regular Gemma-4 26B:
🤯0/100 refusals (actually uncensored)
🚀Fixed all the tool-call + tokenizer jank
⚡️90% faster prompt processing
🏆Sharper, smarter, way more capable responses
- Perfect local beast for llama.cpp
✅ Runs ~18-22 GB VRAM (16.8 GB Q4_K_M file)
- Run on 16 GB GPUs!
The 31B version in the works, should be out SOON 🤯
Pull this version on hugging face below 👇🏻
Trump's WLFI: borrowed real money against fake tokens, sold to wallets tied to North Korea & Iran, token crashed 82%, then quietly deleted the family's names from the website. This is your president. This is corruption with a ticker symbol. $WLFI
We just gave every Hermes Agent a free cloud browser.
Use the Browser Use ecosystem in Hermes Agent for free
> Unlimited browser hours
> Free proxies
> Persistent authentication
@NousResearch 🤝 Browser Use