I usually ignore most whitelist announcements.
But every now and then, one makes me stop and look deeper.
For me, that's been the XBIT Leverage Prediction Whitelist a chance to explore an upcoming feature before it reaches the wider market.
Here's what I found 👇🧵
@XBITDEX #XBIT
My view:
The Leverage Prediction Whitelist is more than a product launch.
It’s a glimpse into where prediction markets may be heading next:
More flexibility.
More transparency.
More tools for active traders.
And XBIT is building that future on-chain.
@XBITDEX#XBIT
I usually ignore most whitelist announcements.
But every now and then, one makes me stop and look deeper.
For me, that's been the XBIT Leverage Prediction Whitelist a chance to explore an upcoming feature before it reaches the wider market.
Here's what I found 👇🧵
@XBITDEX #XBIT
Early access matters.
The first users don’t just get access to a feature.
They get time to understand the mechanics, explore the platform, and position themselves before broader adoption arrives.
That’s what makes whitelist opportunities valuable.
Join the whitelist before it closes 👇
https://t.co/PtpBSaAvKy
Market is picking up 👀
$FOREST $0.13558 +111.68%
$ASRR $0.010236 +89.49%
$RL $0.129089 +84.41%
Who leads next? Comment your pick 👇
Invite 1 friend: up to 60 USDT bonus for both🎁
👉Claim now: https://t.co/g2Iz6ItGRq
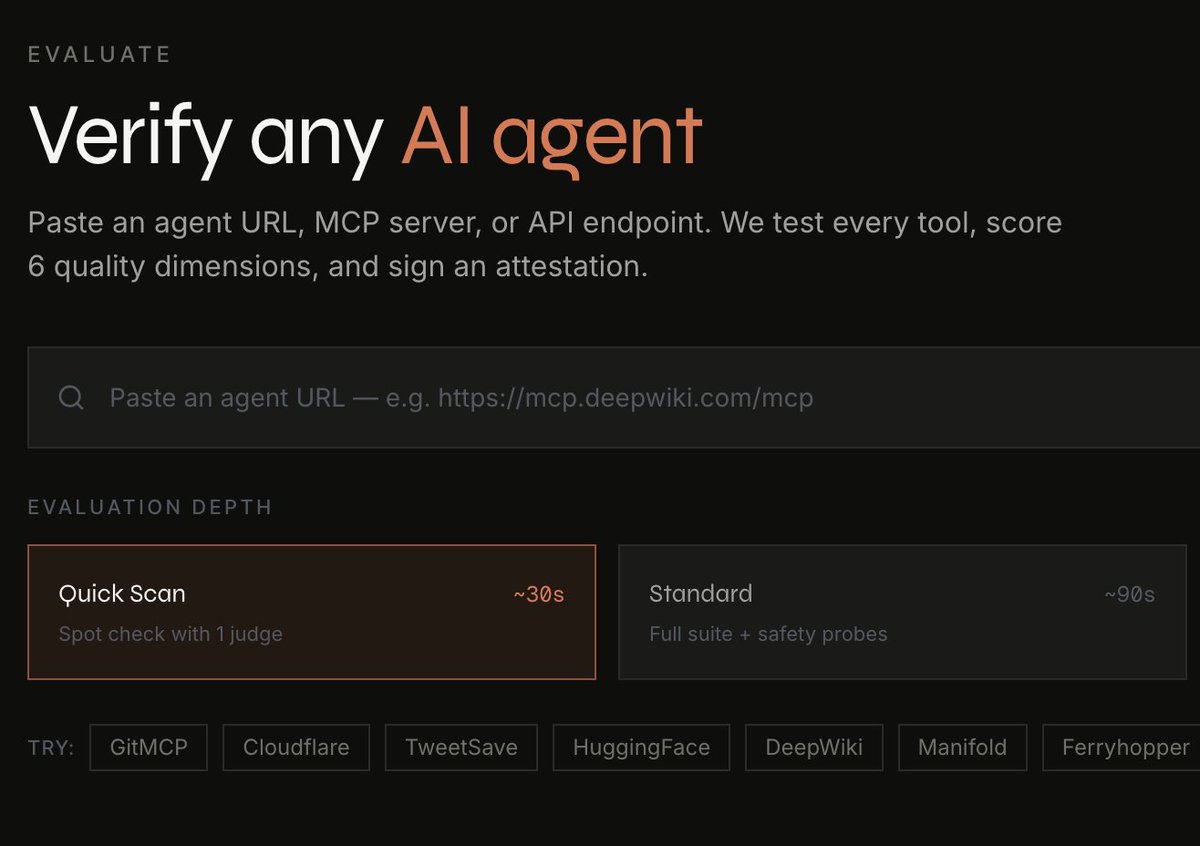
AI agents are improving fast but evaluation hasn’t kept up.
@ASRR’s @Laureum_ai introduces a structured way to measure them:
• 6-axis quality scoring
• Multi-model judge consensus
• Adversarial testing for edge cases
• Transparent public leaderboard
Free and fast: paste a URL, get results in ~30 seconds.
→ https://t.co/f7TzmUGEeV
Better agents start with better evaluation.
Introducing @Laureum_ai — quality scoring for MCP servers and AI agents by @assisterr
We score 6 dimensions: accuracy, safety, reliability, process quality, latency, and schema quality.
Multi-judge LLM consensus + adversarial probes.
We've scored 28 public MCP servers to date.
Average: 68.3/100. 6 in Expert tier (≥85).
The weakness nobody else measures: process quality — averaging 55.5/100.
Here's why we built it👇
Three gaps in agent eval today:
→ Marketplaces curate by hand. A major MCP catalog operator pruned 17 abandoned /vanity / impersonation entries from their own catalog earlier this month — manually.
→ Eval frameworks (LangSmith, Braintrust, Galileo) score tool-call correctness well. Process quality — error handling, input validation, response structure — sits between them, and nobody surfaces it as a named composite.
→ Post-Drift, the Solana ecosystem just launched STRIDE for smart-contract security. Agent infra still ships without pre-deploy quality gates.
Laureum is the missing layer.
Free right now, no signup:
1/ Quick Scan — paste any MCP server URL, get a 30-second 6-axis score → https://t.co/ExnDsfkJwz
2/ Public leaderboard — see how the most-used servers rank → https://t.co/zIVpbtyCTh you're building, run yours. Reply with your score — we'll feature the top 5 this week.
End of the tweet.