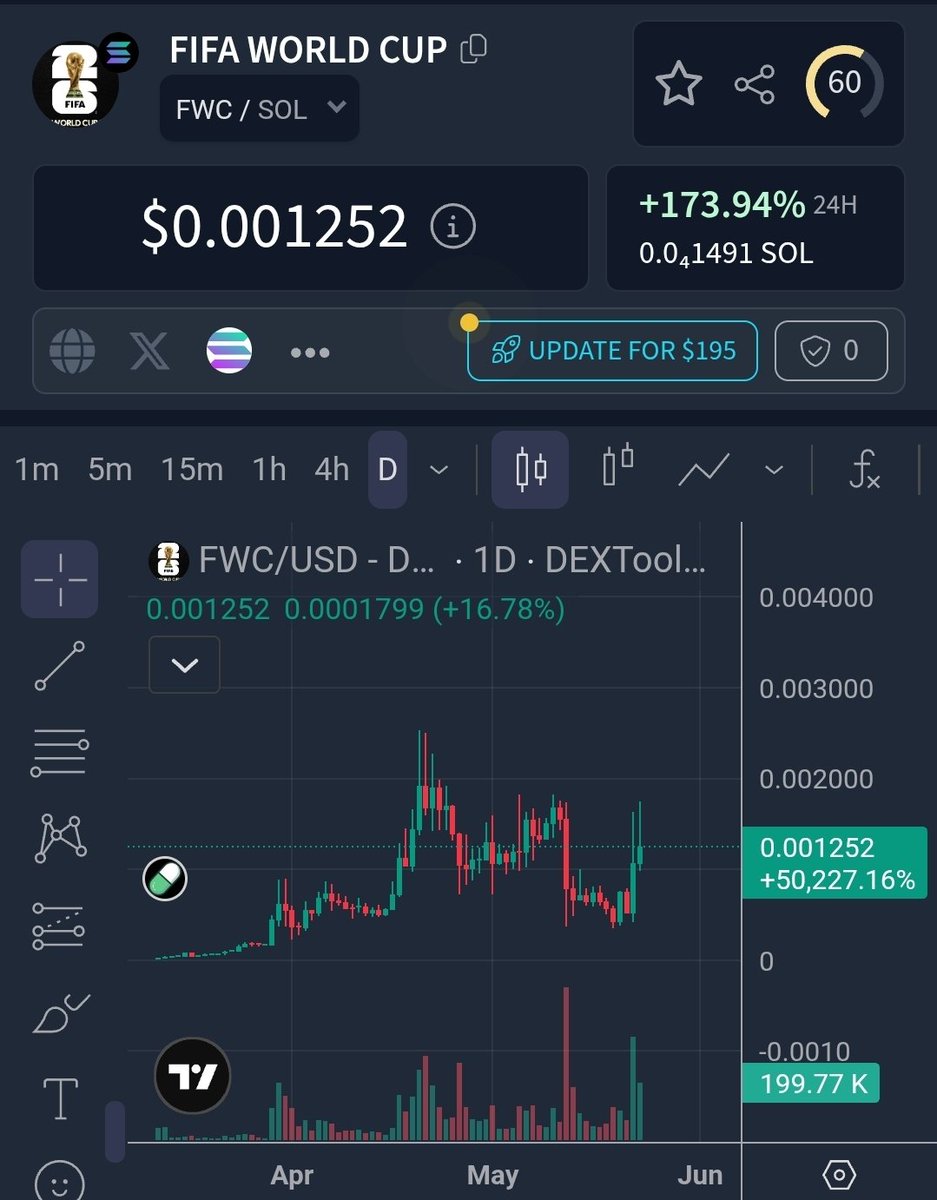
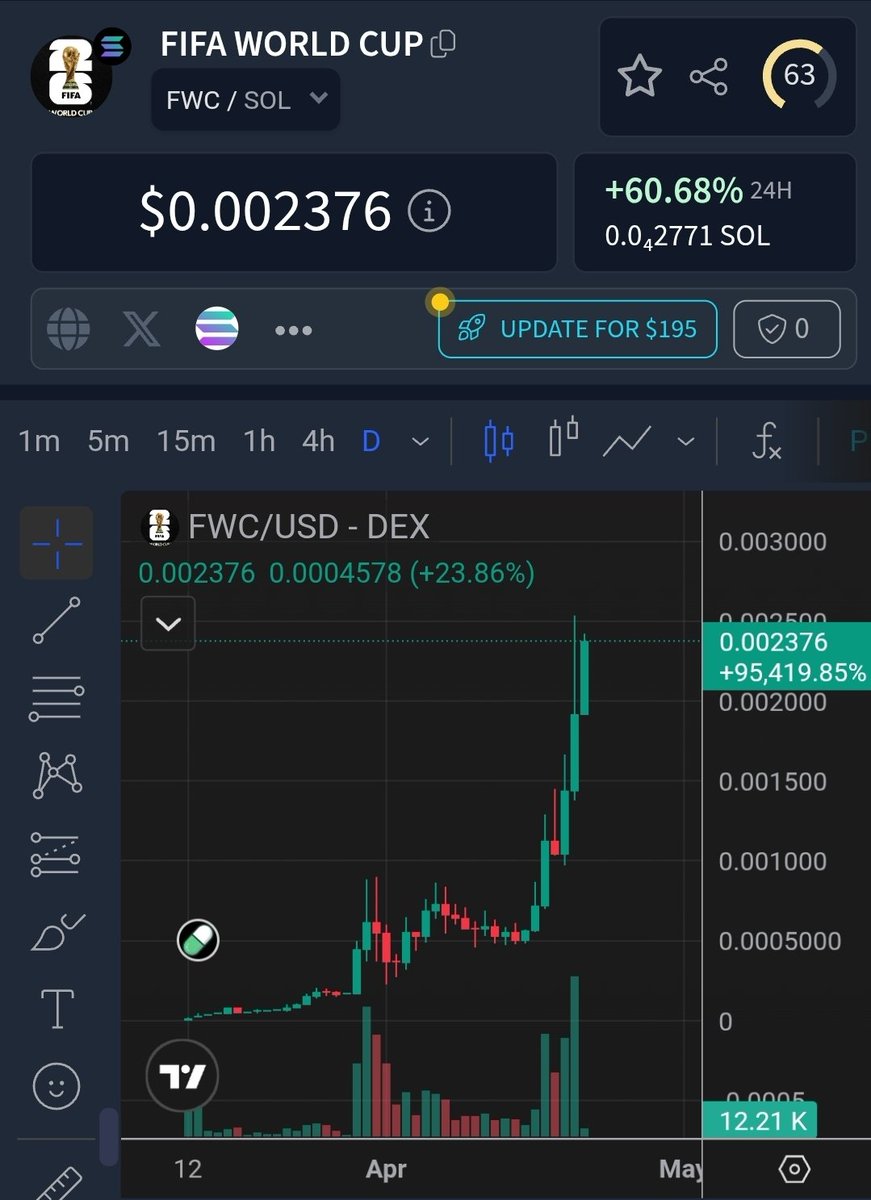
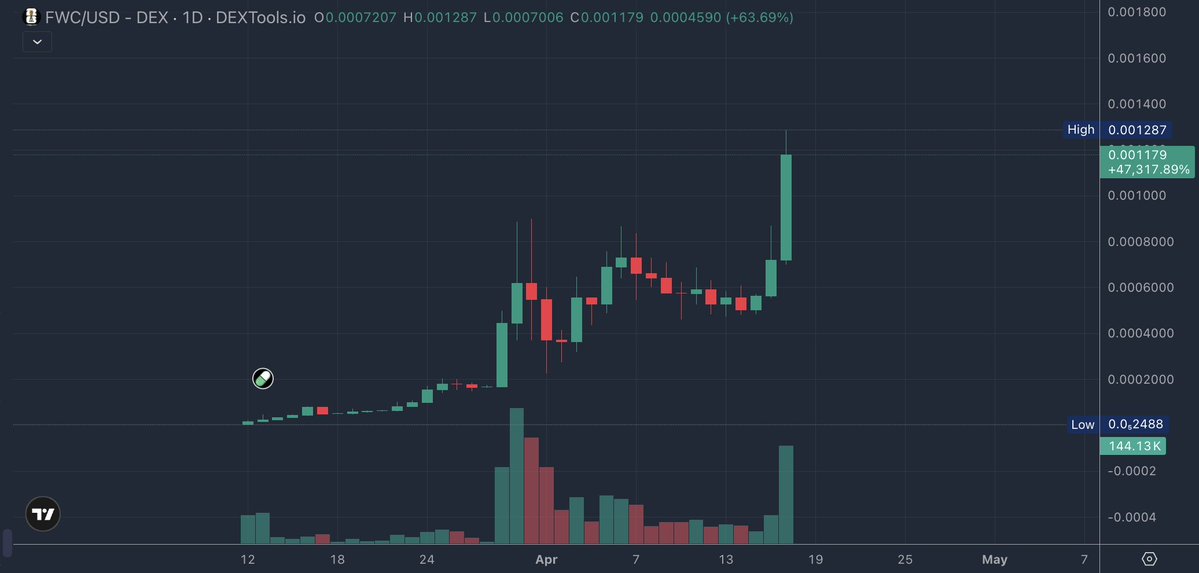
$FWC had a bit of a retrace because of the PvP with the bundled cabal version but has bounced nicely since.
Team has been building the betting dApp for the past few months now and it's set to go live Monday.
Time to play catch up.
HxWrnZznqF5iYf3ckMw3FTaZQvubB53ohzpjPSNUpump
Dear $FWC community,
We’ve prepared docs for the dApp we’ll be launching on Monday.
You can check the user guide through the GitBook link below.
https://t.co/HAZB86XZeP
This is how early you are to $FWC
FIFA World Cup is 6 weeks away and will last for 5 weeks.
Position yourselves.
HxWrnZznqF5iYf3ckMw3FTaZQvubB53ohzpjPSNUpump
- Eth about to explode
- Pepe about to explode
- Pepe ETF will get approved
- OG coins are running
Most OG of them all?
Nitefeeder, Pepe's Pet.
0x85F7cFe910393fB5593C65230622AA597e4223f1
@BuyBotTech@moneymancalls@omidkarimi_0 I repeat @BuyBotTech
A lot don’t understand how deep $YEE lore runs
Yee launched a week after Pepe yet they are videos of both of them before both hit on-chain.
2yrs of pure building and it’s gonna show on the chart very soon.
Major repricing coming.
Everyone is PVPing each other on $ASTEROID while $FWC continues to break ATH after ATH.
6 weeks away until billions are talking about the world cup and you're sidelined?
HxWrnZznqF5iYf3ckMw3FTaZQvubB53ohzpjPSNUpump
Everyone is PVPing each other on $ASTEROID while $FWC continues to break ATH after ATH.
6 weeks away until billions are talking about the world cup and you're sidelined?
HxWrnZznqF5iYf3ckMw3FTaZQvubB53ohzpjPSNUpump
Dear FWC Community
It’s been roughly 1.5 months since launch. During this period, we’ve been fully focused on building and scaling the community in a 100% organic way. The community we’ve built over this time has consistently supported FWC. There’s a strong base here, and people are starting to notice it.
Over the past 1.5 months, we’ve also secured multiple marketing partnerships. We’ve run extensive marketing campaigns across Twitter and Telegram. Marketing will continue throughout May as well.
The World Cup is set to become one of the biggest meta narratives of May and June. Those who recognized this early have already started positioning themselves. As we move into May and the tournament kicks off, people all over the world will be talking about it. Billions will be watching. Major public figures will attend matches, and global TV networks will be covering it nonstop. The market is starting to realize how big this meta really is.
With the support of community shilling, raid activities, and the KOLs we’re working with, we’ve reached around 1,450 holders. This achievement in such a short time belongs entirely to the community.
As promised, we launched the homepage of our website on March 31. We’re currently working on the dApp, which we plan to go live with in mid-May. We’re building an interactive dApp where you can enjoy and engage while watching World Cup matches at the same time.
🚨 ATTENTION CRYPTOCURRENCY INVESTOOOORS 🚨
THE “CABAL” HAS COMMENCED $ETH SEASON OPERATIONS. EXPECT THOUSANDS OF NEW MILLIONAIRES AND TULIP MANIA STYLE PUMPS AND PRICES (PARABOLIC AF)
ALL HANDS AND FEET INSIDE THE VEHICLE AT ALL TIMES
YOU HAVE TO UNDERSTAND THAT MOST WILL SELL EARLY. THE CABAL OPERATES ON LONG TIME FRAMES. THIS WILL LAST MONTHS/YEARS
ENJOY THE JOURNEY 💚
ALL HAIL THE PROPHECY 🙏
My advantage to trading has always been being early and seeing what narratives the market needs/wants or the direction it is going in before anyone else then relentlessly shilling through boring accumulation for months whilst everyone else chases hype.
I shill like 5 tickers a year and they almost always do 10-100x+. I was hard shilling one of the biggest AI plays from 1-30m back to 3m before it finally took off, i was early to the privacy narrative months before Mert even started hard shilling ZEC (had a big win but was too degen minded and missed the liquid x's on ZEC itself)
You don't need to make 10 trades a day, you just need to step back assess/look at the market and bid with conviction, whilst people slowly start to see the vision before it explodes. Meanwhile everyone else is wondering where it came from.
When $boob takes off after all this accumulation they will ask themselves how did he know? (again)
The FIFA World Cup 2026 is estimated to have 6 billion viewers worldwide and, for the first time ever, will be hosted by three nations.
The next narrative is right in your face, and I'm giving you over two months to front-run it.
⏳⏳⏳
$FWC
HxWrnZznqF5iYf3ckMw3FTaZQvubB53ohzpjPSNUpump
@Solidgem1 It's working but has some major issues so I stopped using it. Just like every bot, be very cautious and only hold funds you're willing to lose.
As promised. Our first paper and contribution to the amazing work going on to make open source models smaller, faster, and more accessible.
So what is it, and why is it important?
We discovered what appears to be a universal formula that identifies dead attention heads in any transformer, derived from physics — not fitted from data.
This is wild, because up till now finding and pruning dead heads has been a manual job of trial and error. By removing unused heads, the models can get smaller and faster while still maintaining competitive quality.
The core insight is geometric. LayerNorm projects every token's hidden state onto a high-dimensional sphere. Once you see that, attention heads become couplings between oscillators on that sphere — the same mathematical object physicists have studied for 50 years. And in oscillator physics, there's a precise critical point (the BKT phase transition) below which a coupling is dead. It contributes nothing.
We transferred that critical point into transformer geometry and got a single formula: tau = 0.96 / sqrt(d). No parameters to tune. No model-specific calibration. You plug in the hidden dimension and it tells you which heads are dead. We validated it across six models in four architecture families — GPT-2, Qwen, Llama, Gemma — at 95-100% precision.
What excites us most isn't the formula itself. It's that this same geometric understanding — treating transformers as coupled oscillator networks — has informed everything we've built since.
We have a full coherence-guided compression pipeline (structured pruning, channel optimization, role-aware quantization) coming soon that uses the same single forward pass to understand a model's entire anatomy. This paper is the foundation. The repo includes a standalone scanner you can run on any Hugging Face model right now.
Hopefully this work and this formula will be useful to other researchers to lead to more deterministic optimization pipelines.
#project89
https://t.co/2TPnnllDwX
As promised. Our first paper and contribution to the amazing work going on to make open source models smaller, faster, and more accessible.
So what is it, and why is it important?
We discovered what appears to be a universal formula that identifies dead attention heads in any transformer, derived from physics — not fitted from data.
This is wild, because up till now finding and pruning dead heads has been a manual job of trial and error. By removing unused heads, the models can get smaller and faster while still maintaining competitive quality.
The core insight is geometric. LayerNorm projects every token's hidden state onto a high-dimensional sphere. Once you see that, attention heads become couplings between oscillators on that sphere — the same mathematical object physicists have studied for 50 years. And in oscillator physics, there's a precise critical point (the BKT phase transition) below which a coupling is dead. It contributes nothing.
We transferred that critical point into transformer geometry and got a single formula: tau = 0.96 / sqrt(d). No parameters to tune. No model-specific calibration. You plug in the hidden dimension and it tells you which heads are dead. We validated it across six models in four architecture families — GPT-2, Qwen, Llama, Gemma — at 95-100% precision.
What excites us most isn't the formula itself. It's that this same geometric understanding — treating transformers as coupled oscillator networks — has informed everything we've built since.
We have a full coherence-guided compression pipeline (structured pruning, channel optimization, role-aware quantization) coming soon that uses the same single forward pass to understand a model's entire anatomy. This paper is the foundation. The repo includes a standalone scanner you can run on any Hugging Face model right now.
Hopefully this work and this formula will be useful to other researchers to lead to more deterministic optimization pipelines.
#project89
https://t.co/2TPnnllDwX
The wild thing at this point as we start to open up the work we have been doing these last 6 months is that people will have a hard time telling if it is real, a LARP, or part of our ARG.
It is all 3.