@mr_r0b0t what exists vs what's referenced:
Files that exist in the repo:
scripts/swarm.py
scripts/worker.py
templates/prompts.py
Files missing:
- scripts/seed.py — mentioned in README, SKILL.md
- scripts/filter.py — listed in PLAN.md and in the architecture
Today we’re releasing Qwen-Scope 🔭, an open suite of sparse autoencoders for the Qwen model family. It turns SAE features into practical tools:
🎯 Inference — Steer model outputs by directly manipulating internal features, no prompt engineering needed
📂 Data — Classify & synthesize targeted data with minimal seed examples, boosting long-tail capabilities
🏋️ Training — Trace code-switching & repetitive generation back to their source, fix them at the root
📊 Evaluation — Analyze feature activation patterns to select smarter benchmarks and cut redundancy
We hope the community uses Qwen-Scope to uncover new mechanisms inside Qwen models and build applications beyond what we explored.Excited to see what you build! 🚀
🔗🔗
Blog: https://t.co/ndwiE1tnb9
HuggingFace: https://t.co/1kICpK8eXG
ModelScope: https://t.co/U7v1FjmPaW
Technical Report: https://t.co/CZMjEZK0sa
"how do you fit qwen 3.6 27b q4 on 24gb at 262k context" lands in my dms 5 times a week. here is the exact memory math.
model bytes at idle = 16gb (q4_k_m of 27b dense)
kv cache at 262k context with q4_0 for both k and v = 5gb
total = 21gb on the card
headroom = 3gb for prompts and tool call traces
the magic is the kv cache type. most people leave it at default fp16 or push to q8 thinking quality wins. on qwen 3.6 27b dense at 262k:
- fp16 kv cache = does not fit at all
- q8 kv cache = fits at 23gb but runs 3x slower (double penalty: more vram, less speed)
- q4_0 kv cache = fits at 21gb at full speed (40 tok/s flat curve, same speed at 4k or 262k)
most builders never test the kv cache type because tutorials never mention it. it is the single biggest unlock on consumer 24gb hardware.
flags i run:
./llama-server -m Qwen3.6-27B-Q4_K_M.gguf -ngl 99 -c 262144 -np 1 -fa on --cache-type-k q4_0 --cache-type-v q4_0
what they do:
-ngl 99 = offload everything to gpu
-c 262144 = 262k context window
-np 1 = single user slot (do not enable multi-slot, eats headroom)
-fa on = flash attention on (memory and speed both win)
--cache-type-k q4_0 --cache-type-v q4_0 = the unlock
if you are sitting on 24gb and not running this config, you are leaving 250k of context on the table. or worse, you are running q8 kv cache and burning 3x your speed for nothing.
q4 is not a compromise on consumer hardware. it is the right call.
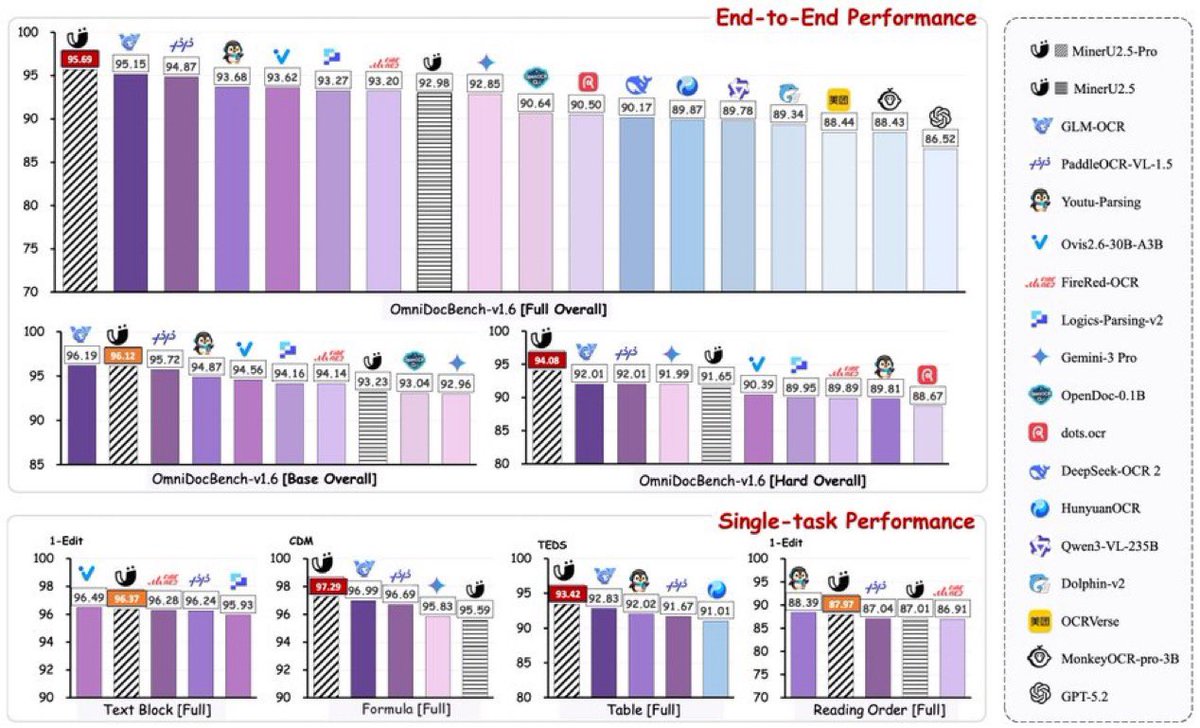
🔥 Parse your documents with SOTA OCR that beats 👀 Gemini 3 Pro, Qwen3-VL-235B, GLM-OCR using just 1.2B params! 🏆
🔥 1.2B params beats:
• Gemini 3 Pro
• Qwen3-VL-235B
• GLM-OCR
• PaddleOCR-VL-1.5
📈 95.69 on OmniDocBench v1.6 (new record)
🚀 65.5M training pages = pure data magic
✨ Tables • Formulas • Charts • Cross-page magic
BREAKING:🚨 NVIDIA just quantized Gemma 4 31B on Hugging Face 🔥
NVFP4 compression = 4x smaller weights with frontier-level accuracy.
✅99.7% of baseline on GPQA
(75.46% vs 75.71%).
📈256K context window.
🧐Multimodal (text + images + video).
vLLM-ready + Blackwell optimized.
VRAM requirements:
⚡️Weights only: ~16–21 GB
🚀Everyday use: Runs on 24 GB GPUs
📈Full 256K context = 32 GB VRAM sweet spot (RTX 5090-class consumer GPUs)
This is the 31B-class frontier model you can actually run locally on a high-end rig.
Try it today👉 https://t.co/0E6wO3PZN4