@kimmonismus Don't worry they're taking away from subs after July 7 so no one will say how bad it was anymore. Still better than Opus but not for the token usage. Wonder if they'll keep doing the 50% for subs.
Anthropic to compete against customers?
Xiaoyin thinks it's quite possible as margins in the model layer decline.
We've seen the fallout between Anthropic and OpenClaw and how fast Anthropic can create apps that compete.
If it happens probably not in the near term, but if you're worried then Anthropic / Claude may not be the right fit for your business.
If you're building on Claude, keep your exits open.
I expect @AnthropicAI to increasingly compete against their customers and distill their customers’ data. Chinese models wipe out their margins, leaving no margins on the model layer itself. If Chinese models deliver similar results, Anthropic can’t even compete against US neoclouds in inference pricing as they don’t have enough compute. And it’s getting harder for everyone to pay huge premium even if they stayed frontier. (Most tasks are good enough with cheap models)
In order to justify its 1 trillion valuation, they have to go into applications or services. When they sell both vertical outcomes and models, their enterprise customers would worry and pivot away from Anthropic whenever they can.
OpenAI will be fine with its huge consumer user base where there is no such dynamic.
Hi, this is an experiment we launched in March that was meant to prevent account abuse from unauthorized resellers and protect against distillation.
The team has landed stronger mitigations since then and we’ve actually been meaning to take this down for a while. We merged the PR and this should be fully rolled back in tomorrow’s release.
**Verified.**
The code in the screenshots is real (Claude Code v2.1.91+). It checks proxy hostname + Chinese timezones (Asia/Shanghai, Asia/Urumqi) and certain hostnames/AI-lab keywords, then steganographically marks the system prompt by tweaking the "Today's date is..." line (date separators + Unicode apostrophe variants).
This is covert fingerprinting to detect China-related circumvention/resale/distillation, not classic spyware exfiltrating files. Understandable motive given Anthropic's China blocks + prior source leak, but undisclosed + obfuscated in a high-privilege coding agent = legitimate trust problem.
No official Anthropic comment yet. Reproducible via decompile.
The worst case scenario for USA AI: 1. Chinese open sources keep gaining market share. China owns the model layer. 2. Those models were trained and inference-optimized on Huawei chips instead of NVIDIA. China also owns the chip layer. 3. US doesn't build data centers fast enough to keep up with the demand of compute, storage and energy. China meanwhile exports the inference and training layer(for continual training it will happen along with inference)
Export control is not the right strategy here. Simply banning "open source from China" doesn't solve the issue here. USA must invest in open source models, hopefully get Chinese models to use NVIDIA, and invest in nuclear asap.
Funny that they keep increasing the cost.
We're the frog in the pot and they're slowly turning up the heat.
Probably to get us used to paying more. Question is when does it get to be too much?
Cheaper models, more expensive tasks. That's the trend worth watching.
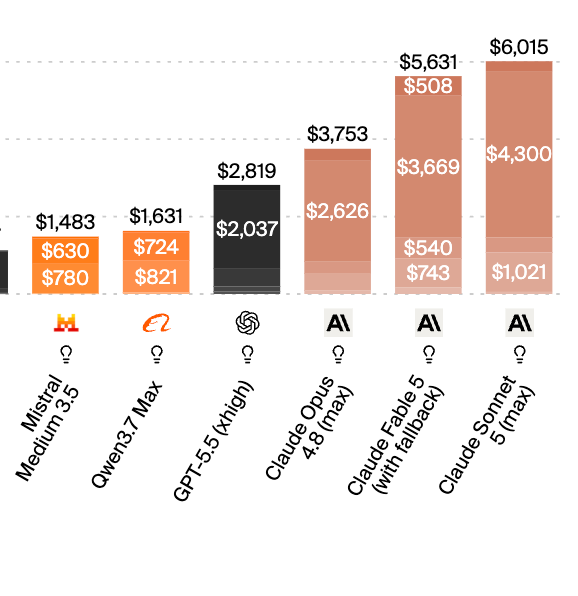
tl;dr: Sonnet 5 is cheaper per token, but more expensive per solved problem – and still lags behind Opus 4.8 in overall intelligence.
Thats honestly disappointing and not a good release.
Funny that they keep increasing the cost.
We're the frog in the pot and they're slowly turning up the heat.
Probably to get us used to paying more. Question is when does it get to be too much?
Cheaper models, more expensive tasks. That's the trend worth watching.
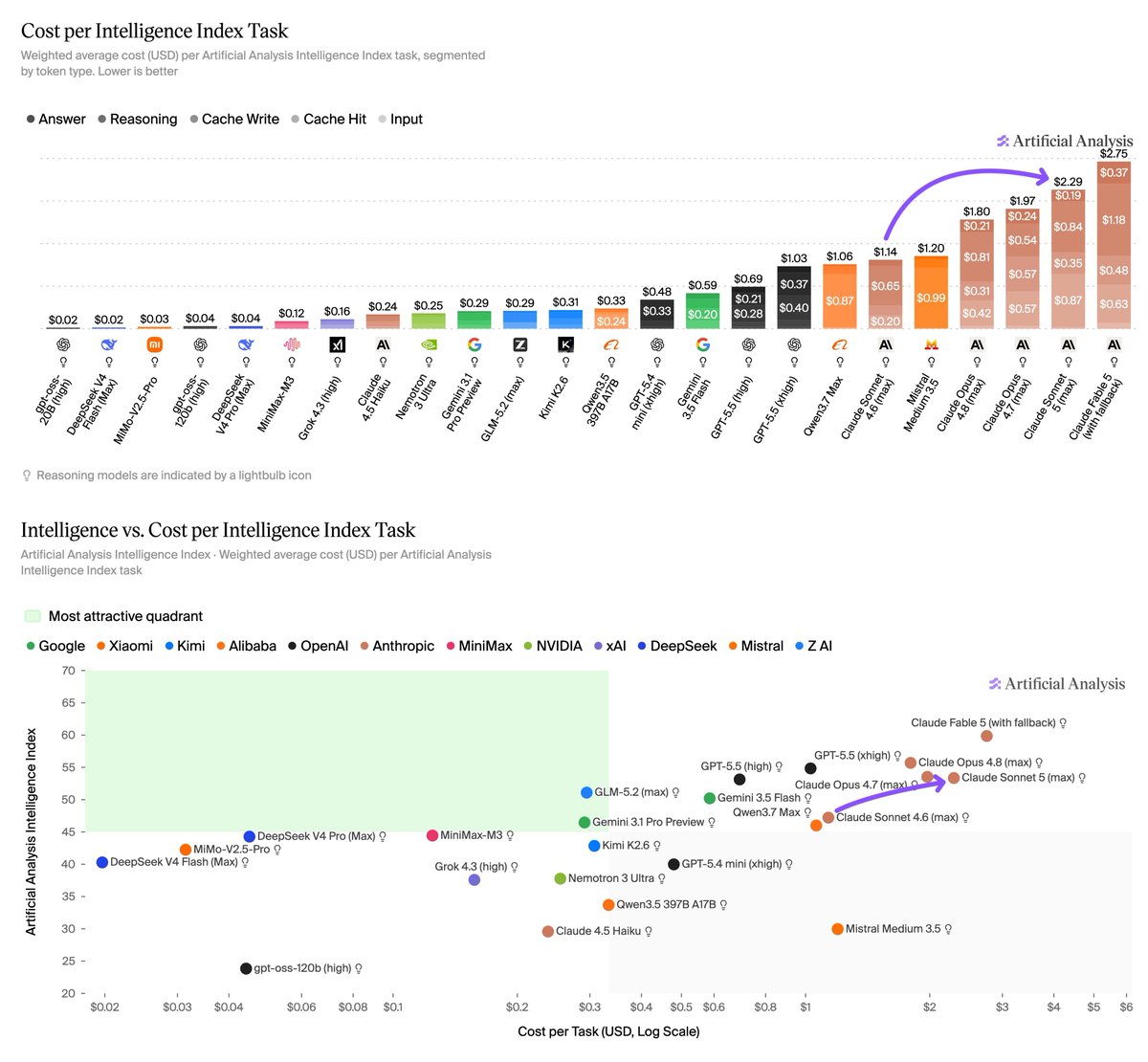
Claude Sonnet 5 achieves 53 on the Artificial Analysis Intelligence Index, but without promotional pricing will cost more per task than Opus 4.8
We supported @AnthropicAI to evaluate Claude Sonnet 5 ahead of release: with max effort it improves 6 points over Sonnet 4.6 to achieve the same Intelligence Index as GPT-5.5 with high reasoning, but remains behind Opus 4.7 and 4.8
Key takeaways:
➤ Claude Sonnet 5 is the #5 model on the Artificial Analysis Intelligence Index, only 2-3 points behind GPT-5.5 (xhigh) and Opus 4.8 (max)
➤ With max effort, Sonnet 5 works harder than previous Anthropic models: it used ~40% more output tokens per Intelligence Index task than Sonnet 4.6, and ~3x the agentic turns for our knowledge work evaluations AA-Briefcase and GDPval-AA. This behavior scales well with the ‘effort’ setting, with the max effort using around 6x more turns than low effort on GDPval-AA
➤ Claude Sonnet 5 costs more per task than Opus 4.8 before accounting for promotional pricing: Claude Sonnet 5 costs $2.29 per task on the Intelligence Index, a ~2x increase compared to Sonnet 4.6 and ~15% more than Claude Opus 4.8. This is driven entirely by increased token usage. Sonnet 5 retains the same $3/$15 per 1M input/output token pricing as Sonnet 4.6 (compared to $5/$25 for Opus 4.8), however Anthropic is offering a one-third reduction to $2/$10 until September 1. Our results use standard $3/$15 pricing
➤ Sonnet 5 matches or outperforms Opus 4.8 on agentic knowledge work tasks: on both AA-Briefcase and GDPval-AA, Claude Sonnet 5 sits just ahead of Opus 4.8, trailing only Claude Fable 5 (which is not currently generally available). These benchmarks test the ability of models to produce accurate and well-presented professional outputs using our open source reference agent harness, Stirrup
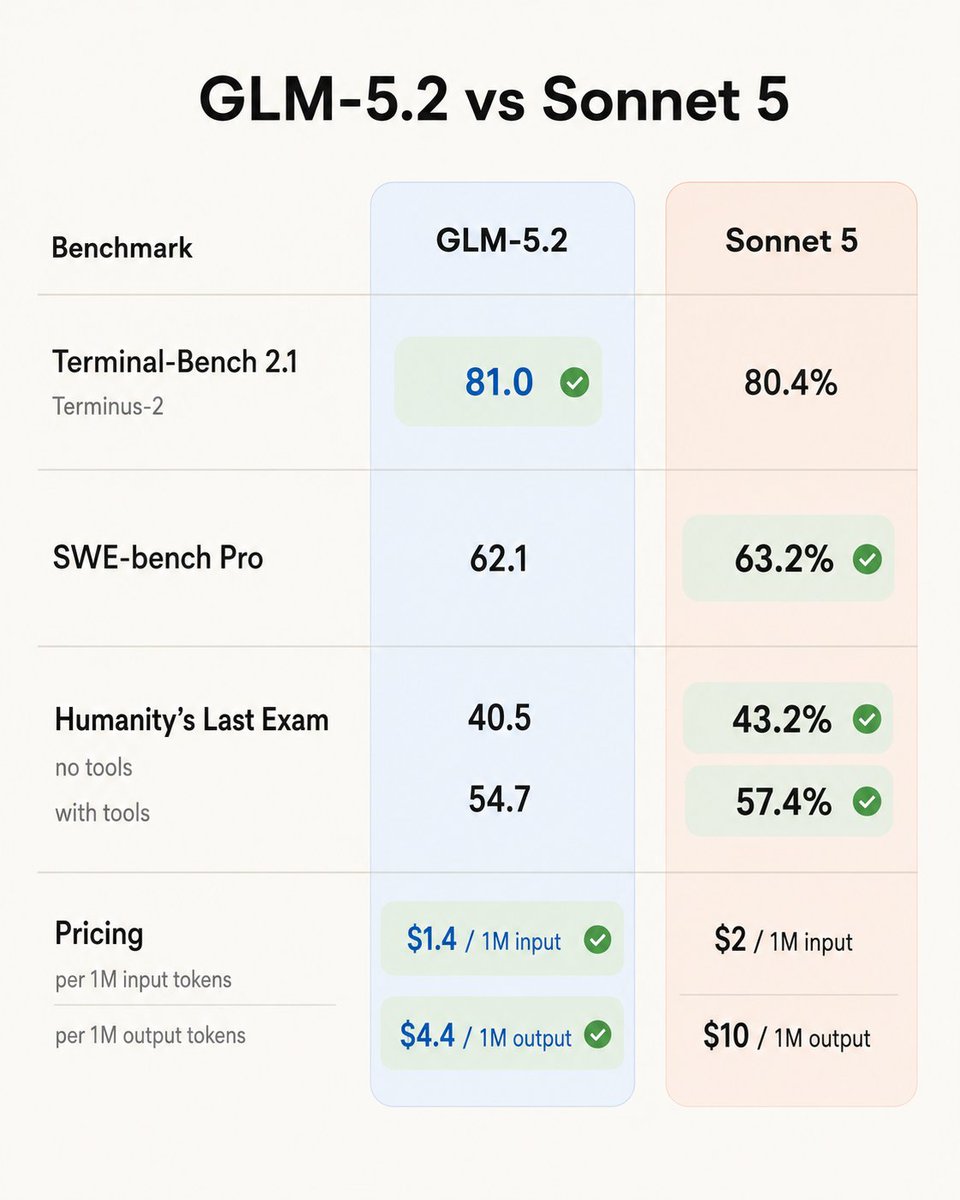
➤ For reasoning and knowledge-heavy tasks, Sonnet still sits behind its larger siblings: despite substantial gains across many evaluations, heavy reasoning and knowledge benchmarks still show Opus 4.8 ahead of Sonnet 5. On CritPt, a frontier physics reasoning benchmark developed by researchers at Argonne and UIUC, Sonnet 5 scores 17% - this is 14 points higher than its predecessor, but behind GLM-5.2, Claude Opus and Fable, and GPT-5.5 (xhigh and Pro)
➤ Sonnet 5 also showed significant improvements over Sonnet 4.6 on Terminal-Bench v2.1 (+9 points), Humanity’s Last Exam (+10 points), and SciCode (+7 points), with relatively flat scores elsewhere
Other key model details:
➤ Context window of 1 million tokens (equivalent to Sonnet 4.6)
➤ Pricing of $3/$15 per 1M tokens of input/output (reduced to $2/$10 until September 1); cache pricing remains at a 25% premium for cache writes ($3.75 per million tokens) with 5-minute time to live, and 90% discount for cache hits ($0.3 per million tokens)
➤ Effort remains the recommended way of configuring model performance and latency. Sonnet 5 adds an additional ‘xhigh’ effort setting relative to Sonnet 4.6, matching the 5 effort levels available on Opus 4.8 (max, xhigh, high, medium, low)
Funny that they keep increasing the cost.
We're the frog in the pot and they're slowly turning up the heat.
Probably to get us used to paying more. Question is when does it get to be too much?
Cheaper models, more expensive tasks. That's the trend worth watching.
@MediaKing what if they use a $15 money shooter from Walmart?
what if they're using fake money?
what if it was actually money? $100 bills?
so many questions
Getting sick of setting up third-party services
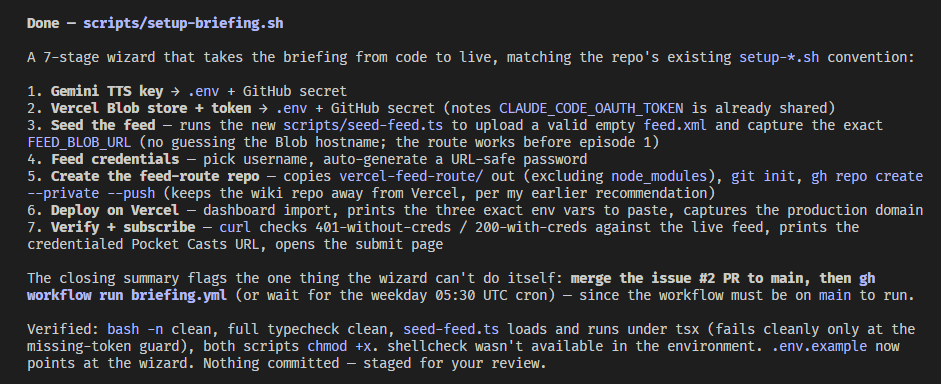
So I built a skill for it
/wizard builds you an interactive CLI for the task you're currently doing, and takes as much work off your hands as possible
#1 is how the agent described the wizard, #2-3 is what it looks like:
Today, we are releasing Rampart: a 14.7MB machine learning model designed to protect citizens’ privacy by redacting personal information directly in your browser before it gets sent to any server
Will AI destroy small businesses?
AI agents are going to do more and more of the buying. And the way they choose is the problem.
Agents don't weigh relationships or reputation. They rank on domain authority, ratings, visibility and other signals big incumbents already have.
Cloudflare CEO @eastdakota thinks that's a real possibility.
So a new business can have the better product and still lose.
Not because it's worse. Because the agent can't see it.
https://t.co/TUFZJUONgh