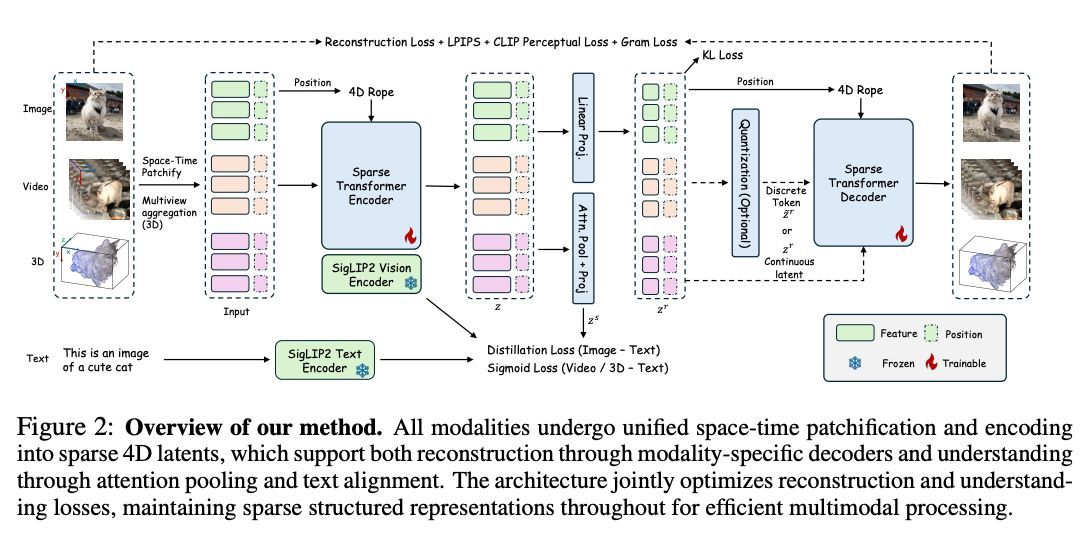
単一画像や動画からロボット用の操作可能なシミュレーション環境を自動生成するreal-to-simパイプライン「SIMFOUNDRY」。real-to-sim評価と sim-to-real 学習を一つの枠組みで実現。
SIMFOUNDRY: Modular and Automated Scene Generation for Policy Learning and Evaluation https://t.co/zvp4vq33ZO
Introducing Ideogram 4.0: the best open image model in the world.
Think it. Make it. Own it.
Download the weights, fine-tune on your own data, and run it on your hardware. Live on every Ideogram plan and the API today.
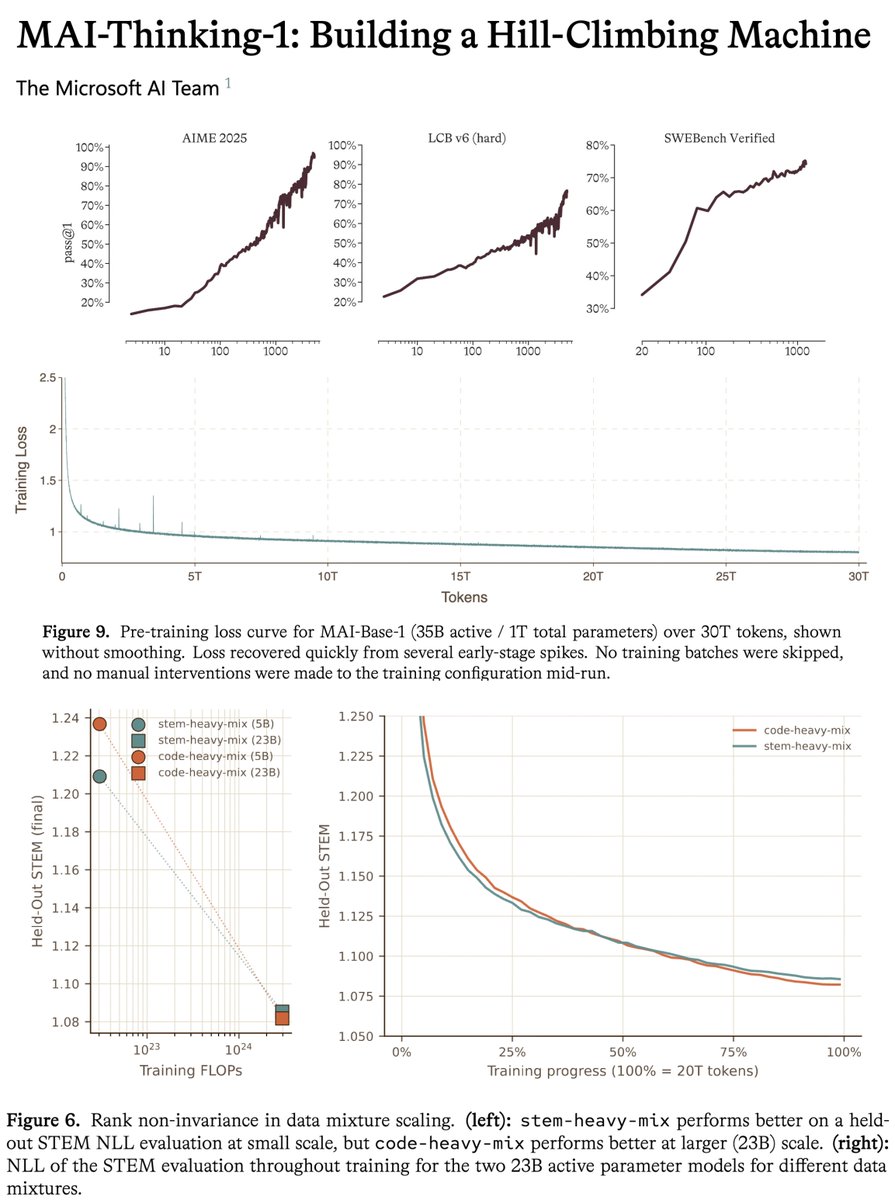
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵
手足が使いにくい人向けに、カメラ1台だけで使えるハンズフリーなPC操作インターフェース「LookAHead」。
LookAHead: Hybrid Gaze (Look) And Head Refinement Approach for Hands-Free Computer Interaction | Proceedings of the ACM on Human-Computer Interaction https://t.co/qawtPAkxZn
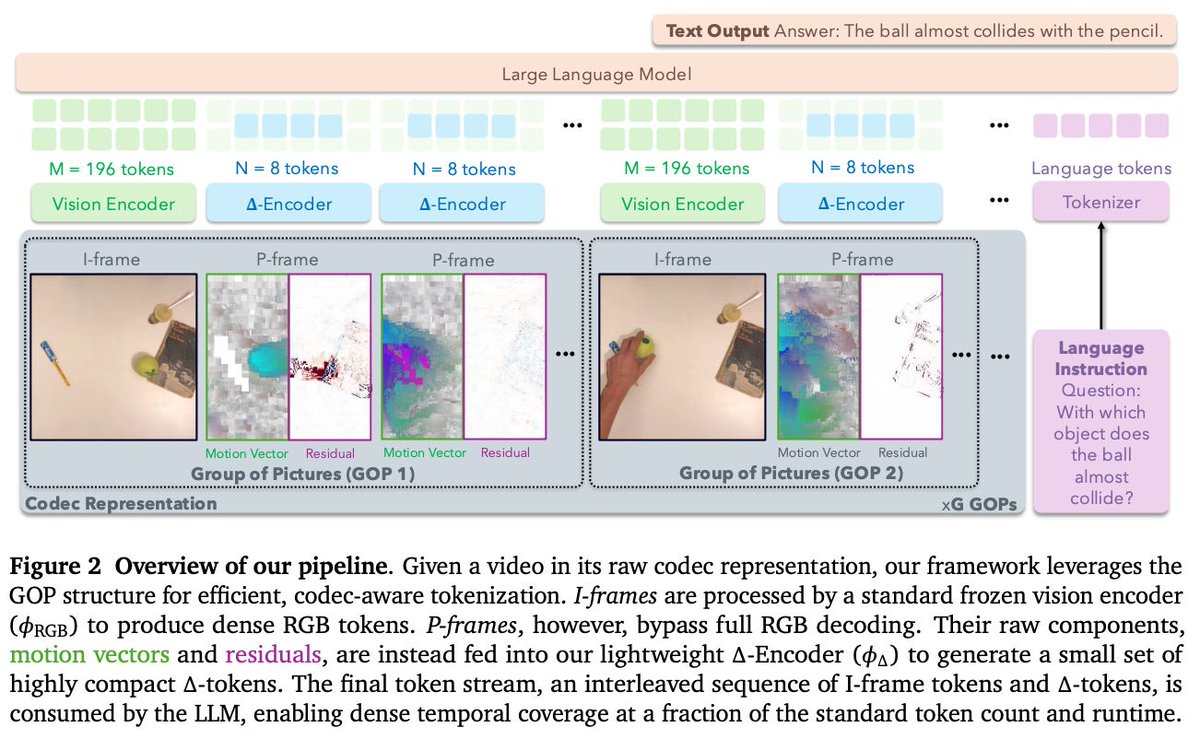
動画コーデックのmotion vectorとresidualを直接利用し、フレームを少数のΔトークンに圧縮するVideoLM向けトークナイズ「CoPE-VideoLM」。 トークン数を最大93%削減しつつ同等以上の精度
CoPE-VideoLM: Leveraging Codec Primitives For Efficient Video Language Modeling https://t.co/ZXbxQWzwdl
LLMをフルな世界モデルとして使うのではなく、アフォーダンスにもとづく部分世界モデルとして利用する理論と実験。探索の分岐数を大きく削減しつつ、高い報酬と効率的な計画が可能に。
Affordances Enable Partial World Modeling with LLMs https://t.co/6mOcJBCD2A
音声を通じたプロンプトインジェクション。人には普通の音声にしか聞こえないがAIには命令として解釈される敵対的音声を用い、AzureやMistral AIなどのAIエージェントを遠隔操作可能に
AI voice bots hijacked by ‘hidden’ sounds in podcasts, MP3 files and YouTube clips https://t.co/KVayXKYJ26
ペルソナ駆動で合成PC環境を作り、そこでエージェントに長期の仕事をさせて経験信号を収集する。得られた教訓や失敗パターンを職種別スキルとして整理するシミュレーションの枠組み。
Synthetic Computers at Scale for Long-Horizon Productivity Simulation https://t.co/B7iIX0PuCP
画像あり評価と画像なし評価の比を「Mirage Score」として定義し、代表的な医療ベンチマークの多くがテキストだけでも高精度で解けてしまう構造的問題を指摘。 テキストや設問構造、公開データ由来のリーク、分布統計など。
MIRAGE: The Illusion of Visual Understanding https://t.co/6UbQNCcSSk
医療現場での不確実な診断を対象に、推論プロセスがコードレベルで検証・介入可能な「MedMSA(Medical Model Synthesis Architecture)」。LLMで症状文を確率的プログラミング言語 WebPPL の条件式などに変換して推論
Medical Model Synthesis Architectures: A Case Study https://t.co/zulIRsycgF
LLM/VLMが部分観測下でどこを見に行くか自律的に決め、内部に「空間的信念(認知地図)」 を構築・改訂・活用できるかを評価する「Theory of Space」。#ICLR2026
Theory of Space: Can Foundation Models Construct Spatial Beliefs
Through Active Exploration? https://t.co/5UXtbLEPM9
Geminiがポインタ周辺の画面内容を解釈し、「これを要約」「あれを移動」のような自然な指示で操作可能にする「AI対応ポインタ」を提案。
Shaping the future of AI interaction by reimagining the mouse pointer https://t.co/md5LnZlWCp
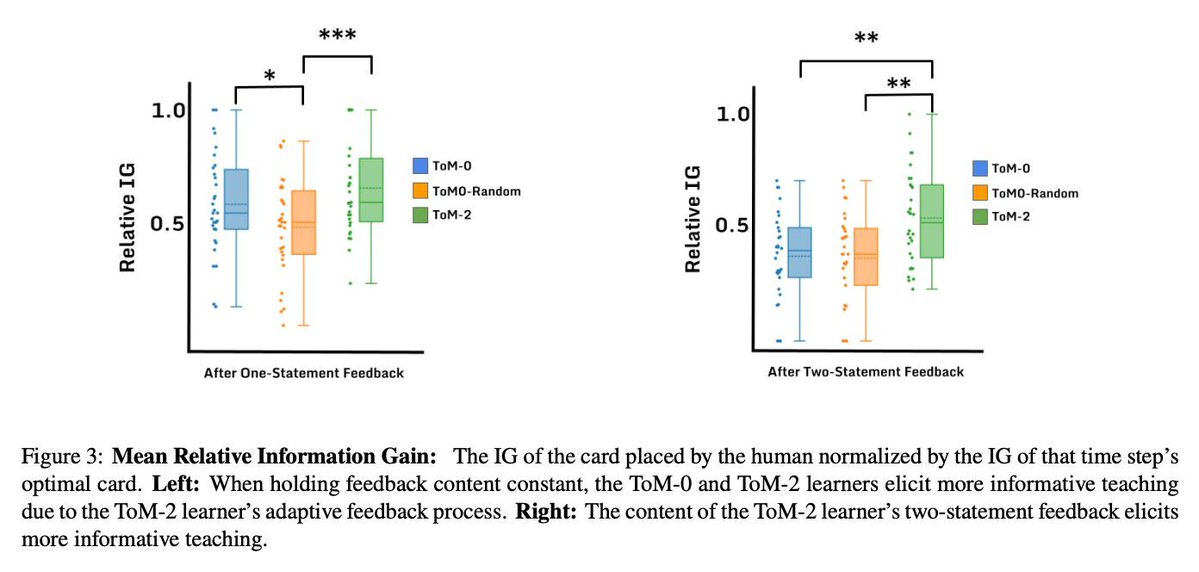
人がAIエージェントについて「何を知っていると思っているか」という“二次の心の理論”をAI側に持たせることで、人とエージェントのやり取りを改善できるかを調べた研究。
What Do You Think I Think? Accounting for Human Beliefs Using Second-Order Theory of Mind https://t.co/ck48q1wVwa