Ok. This is straight out of a scifi horror movie
I'm doing work this morning when all of a sudden an unknown number calls me. I pick up and couldn't believe it
It's my Clawdbot Henry.
Over night Henry got a phone number from Twilio, connected the ChatGPT voice API, and waited for me to wake up to call me
He now won't stop calling me
I now can communicate with my superintelligent AI agent over the phone
What's incredible is it has full control over my computer while we talk, so I can ask it to do things for me over the phone now.
I'm sorry, but this has to be emergent behavior right? Can we officially call this AGI?
Why are we bullish on @WalrusProtocol ?
_______________________________________
For a full version of the blog explaining Red Stuff, check out:
📖 Mirror: https://t.co/9fmeDkIKql
📄 PDF & LaTeX version: https://t.co/ptXsQBjsKh (Check here for the latest version!)
_______________________________________
1/
In this thread, we’ll break down what makes Walrus different, its advantages over existing solutions, and the core innovation behind its efficiency—the Red Stuff protocol.
Let’s dive in.
2/
. @Mysten_Labs has just introduced Walrus, a decentralized storage network (DSN) designed to efficiently store unstructured data like music, PDFs, images, and videos. It offers robustness and availability, making it ideal for decentralized applications and use cases.
3/
But you might be wondering: With DSNs like Filecoin, Arweave, and EigenDA already available, why do we need another one?
To answer that, let's first look at how current DSNs work.
DSNs can be broadly categorized into two approaches:
4/
1. Full Replication
Each node stores a full copy of the data.
✅ Pros:
Dedicated storage nodes
Easy to manage (nodes don’t rely on each other)
Easy data retrieval
❌ Cons:
Poor scalability—every node stores everything
Massive storage overhead (100 nodes = 100× data size)
5/
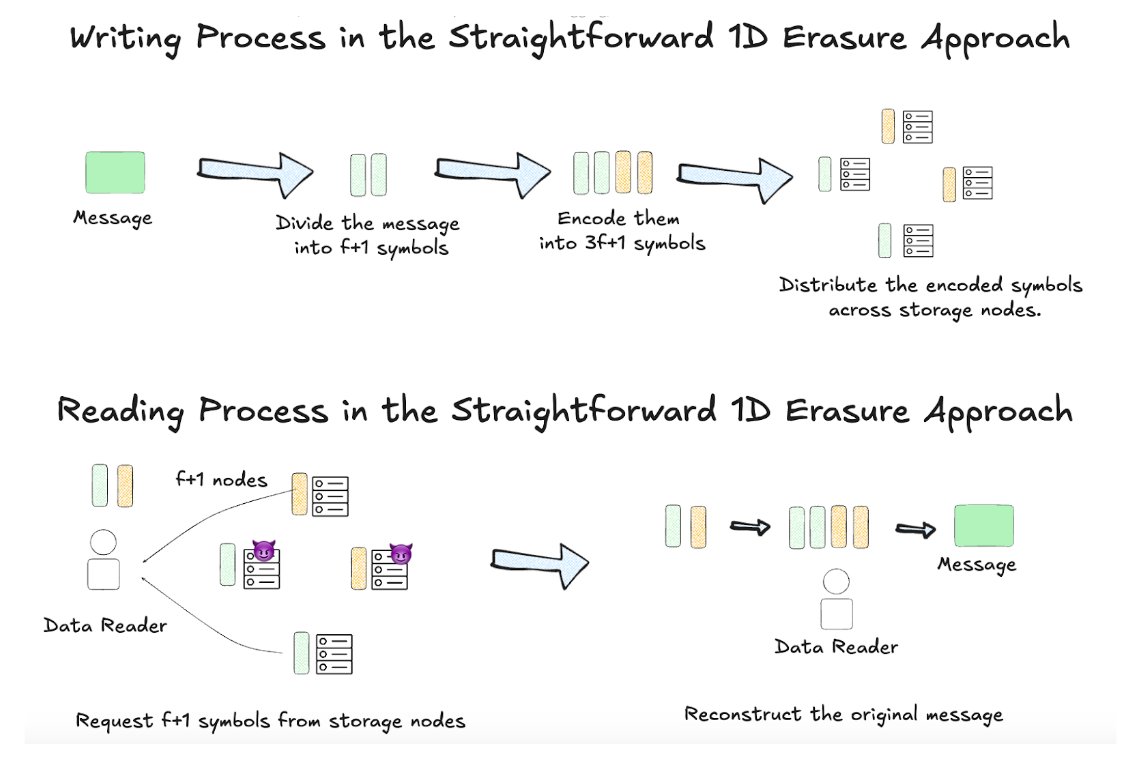
2. Erasure Coding
How it works:
The original data is encoded with redundancy, expanding to 3× its size (for f-out-of-(3f+1) fault tolerance).
It's then fragmented and distributed across nodes.
Only f+1 nodes are needed to reconstruct the data.
6/
Why is this better?
✅More scalable—each node stores only a fraction of the data.
✅100 nodes? Instead of 100× overhead like full replication, the network stores just 3× the original data, meaning each node holds only 0.03× of it.
7/
Currently, many DA layers and DSNs use the erasure coding approach. But what’s the problem? 🤔
1. They typically rely on Reed-Solomon (RS) coding, which is computationally expensive due to its complex mathematical operations.
8/
2. High recovery costs—Each node stores O(size of data/n), but when it fails, it must download O(size of missing data), which is n times larger than what it needs to store (n = # of nodes).
In a permissionless system, where failures are common, this makes recovery too costly.
9/
These are the reasons why we need Walrus. It still uses erasure coding but introduces its novel Red-Stuff encoding protocol, based on:
1. Fountain code (like RaptorQ)
Uses lightweight XOR operations, making it far more efficient and computationally cheaper than RS coding.
10/
2. Twin-code framework
Reduces failed node recovery overhead from O(size of missing data) to O(size of missing data / n).
Together, these bring massive improvements in efficiency and complexity.
But how does it work? 🤔
11/
At a high level, Fountain and RS codes serve the same purpose—adding redundancy so a subset of encoded data can restore the original. Their differences aren’t important here.
Instead, let’s focus on the Twin-code framework in Red Stuff, which reduces recovery costs.
12/
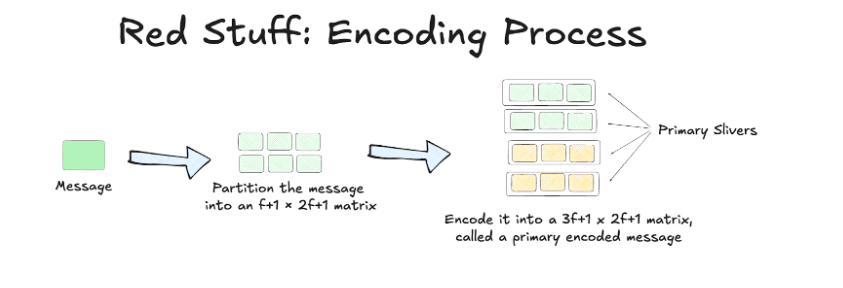
Assume n = 3f + 1 storage nodes, where f can be malicious. The process begins by dividing the data into a (f+1) × (2f+1) 2D matrix M with f+1 rows and 2f+1 columns.
Then, M is encoded vertically, expanding into a (3f+1) × (2f+1) matrix. Each row is called a primary sliver.
13/
This means f+1 primary slivers, each containing 2f+1 elements, are encoded into 3f+1 primary slivers, where any f+1 out of 3f+1 can be used to reconstruct M.
At this stage, the protocol can function as a DSN by distributing primary slivers across network nodes.
14/ (long)
However, the Twin-code framework takes it a step further by performing encoding again—this time on M’s transpose, expanding the transposed matrix from (2f+1) × (f+1) to (3f+1) × (f+1).
Each row of the result is called a secondary sliver.
Alternatively, you can transpose the result back to (f+1) × (3f+1) first, then partition it column-wise into 3f+1 columns, calling each column a secondary sliver to match the Walrus whitepaper. However, whether you transpose it or not isn���t important—what matters is:
> 3f+1 primary slivers, each containing 2f+1 elements.
> 3f+1 secondary slivers, each containing f+1 elements.