🌘 Meet Kimi K2.7 Code HighSpeed!
A high-speed mode of our latest open-source multimodal coding model, Kimi K2.7 Code.
⚡️ Up to 6× faster: Around 180 tok/s on coding tasks with median-length inputs, and up to 260 tok/s on shorter-context tasks.
🔷 Rolling out to Kimi Code Beta Program members, Kimi API developers, and Kimi Business users. (Access will remain limited for now due to capacity constraints.)
🔷 No invite needed. Anyone who joins the Beta Program has a chance to get access 👉 https://t.co/eKogsFGJt6
Open intelligence should be instant, affordable, and borderless. We'll continue improving the model and expanding access as more capacity becomes available!
🔗 Kimi Code: https://t.co/uvoSJKyGCY
🔗 API: https://t.co/mzWxjgGO1h
Kimi 2.7 ranked 2nd after Fable 5 and before GPT-5 xhigh
We have re-run our ErdosBench smoke test on 14 problems with Kimi 2.7, Qwen 3.7 Max, Grok 4.3 and compared it with the top performers from previous runs.
Kimi 2.7 is amazingly good. More below.
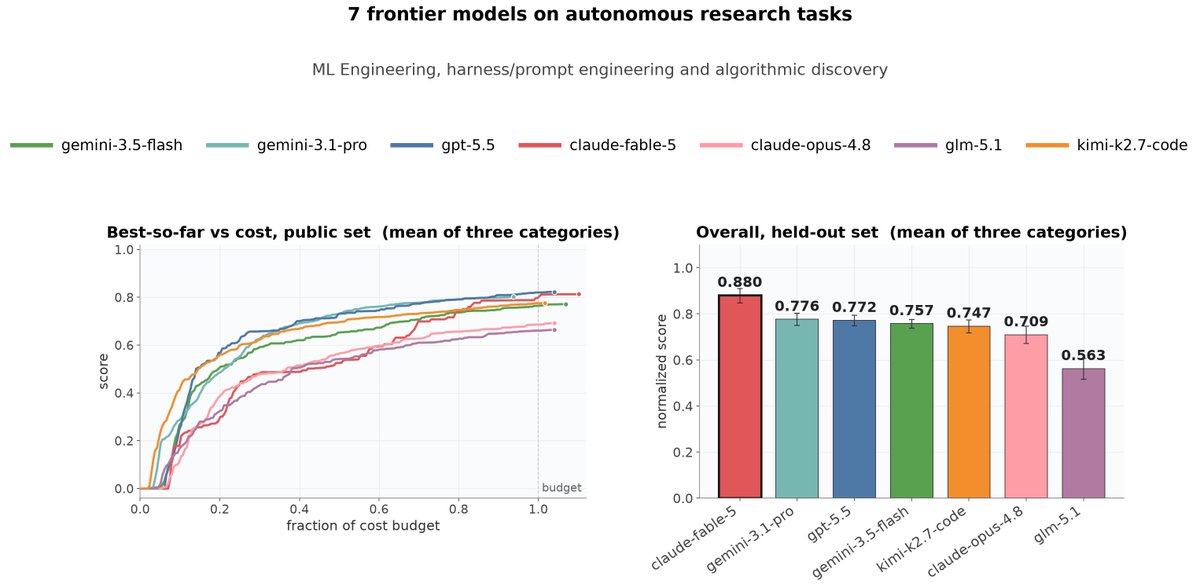
We benchmarked 7 frontier models on 3 categories of autoresearch tasks: ML engineering, harness/prompt engineering, and algorithmic discovery.
Fable-5 won overall even under cost constraint, but on ML engineering, the open model Kimi-K2.7-Code surpassed frontier models.🧵(1/5)
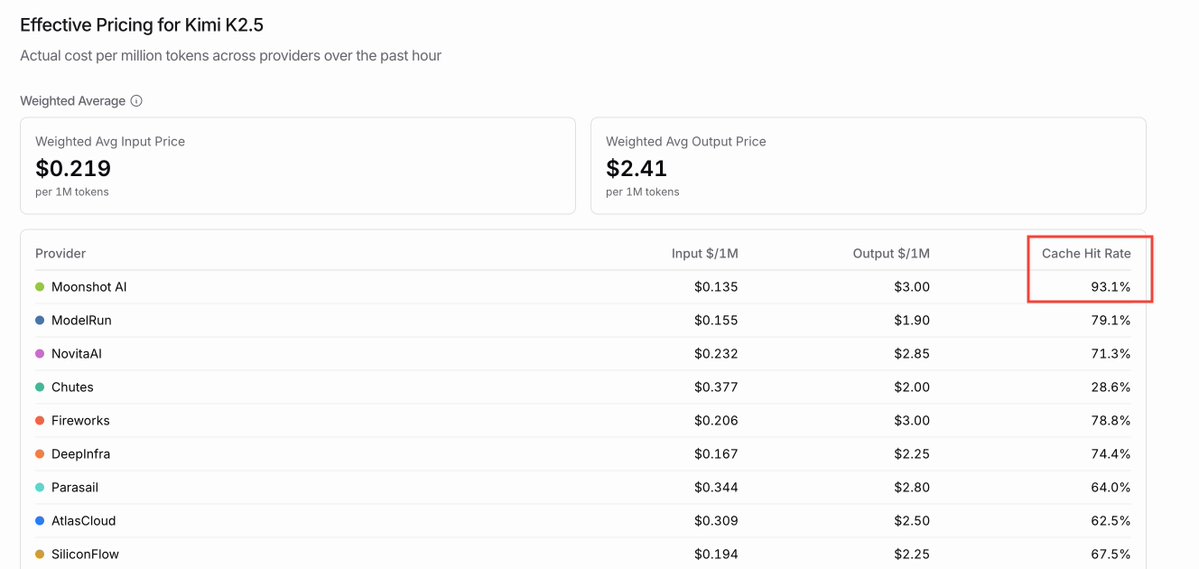
In the OpenRouter Model Pricing section, you can see the cache hit rates offered by different providers. The one that shocked me last time was Kimi K2.5 — their official API can achieve a 93%+ cache hit rate.
Especially in the era of Agent/long-context, cache hit is a crucial technical optimization point, whether in software or hardware.
https://t.co/yIpv32E0Hg
ICYMI: Kimi K2.6 is now in Notion.
It’s the first open-weight model that plays like other top-tier models. It’s strong at tool use and carrying out tasks no matter how meticulous or ambiguous.
Give it a spin and tell us what you think.
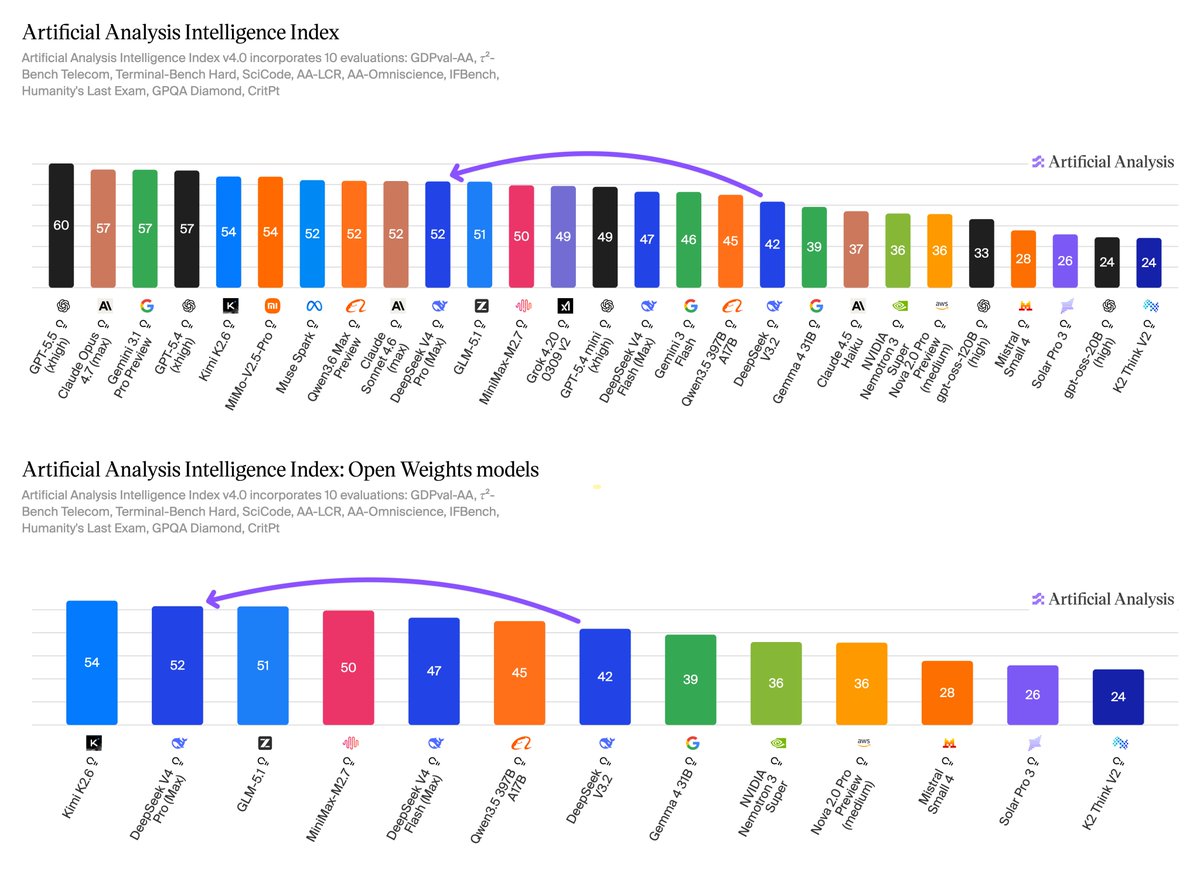
DeepSeek is back among the leading open weights models with the release of DeepSeek V4 Pro and V4 Flash, with V4 Pro second only to Kimi K2.6 on the Artificial Analysis Intelligence Index
@deepseek_ai has released DeepSeek V4 Pro and V4 Flash. V4 is the first new architecture from DeepSeek since V3. V4 introduces a new architecture with V4 Pro at 1.6T total / 49B active parameters and V4 Flash at 284B total / 13B active parameters, and is DeepSeek's first two-tier lineup, with Pro positioned for maximum capability and Flash for faster, lower-cost inference. Both models are hybrid thinking/non-thinking. We tested the reasoning variants in Max Effort and High Effort.
A year ago, DeepSeek R1 and R1 0528 were the leading open weights reasoning models on the Intelligence Index. Since then, several other open weights labs have released strong reasoning models, and V4 Pro now enters as the #2 open weights reasoning model on the Artificial Analysis Intelligence Index, behind only Kimi K2.6 (54). V4 Pro and V4 Flash remain also text input and output only.
Key takeaways:
➤ Large 10 point gain in Intelligence Index: DeepSeek V4 Pro (Max) scores 52 on the Artificial Analysis Intelligence Index, up from 42 for V3.2, making it the #2 open weights reasoning model behind Kimi K2.6. That said, if the weights to MiMo-V2.5-Pro are released as they have been for other Xiaomi models then it will place third. V4 Flash (Max) scores 47, behind V4 Pro but ahead of DeepSeek V3.2. This places it behind frontier models and at Claude Sonnet 4.6 (max) level intelligence.
➤ Leading agentic performance among open weights models: DeepSeek V4 Pro (Max) leads open weight models on agentic real-world work tasks, scoring 1554 on GDPval-AA. This places it ahead of Kimi K2.6 (1484), GLM-5.1 (1535), GLM-5 (1402), and MiniMax-M2.7 (1514).
➤ Gains in knowledge but an increase in hallucination rate: DeepSeek V4 Pro (Max) scores -10 on AA-Omniscience, an 11 point improvement over V3.2 (Reasoning, -21), driven primarily by higher accuracy. V4 Flash (Max) scores -23, broadly in line with V3.2. V4 Pro and V4 Flash both have a very high hallucination rate of 94% and 96% respectively meaning when they don’t know the answer they nearly always respond anyway.
➤ Flash materially behind Pro but well positioned for its size: DeepSeek V4 Flash (Max) scores 47 on the Artificial Analysis Intelligence Index, well below V4 Pro. However, at 284B parameters it is much smaller and is well positioned on the Intelligence vs Size frontier, sitting next to MiniMax-M2.7
➤ Cheaper than frontier models but more expensive than other open weights models and a large increase over DeepSeek V3.2: DeepSeek V4 Pro costs $1,071 to run the Artificial Analysis Intelligence Index. This makes it more than 4x cheaper than Claude Opus 4.7 ($4,811), but it remains more expensive than several other open weights models, including Kimi K2.6 ($948), GLM-5.1 ($544), DeepSeek V3.2 ($71), and gpt-oss-120B ($67). DeepSeek V4 Flash is much cheaper at $113.
➤ High token usage: DeepSeek V4 Pro uses 190M output tokens to run the Artificial Analysis Intelligence Index, making it one of the most token-intensive models tested. DeepSeek V4 Flash is even higher at 240M output tokens. This high token usage helps explain why V4 Pro’s total cost remains relatively high versus other open weights models despite low per-token pricing.
Key model details:
➤ Context window: 1M tokens, an 8x expansion on V3.2's 128K context window
➤ Modalities: Text input and output only, matching V3.2
➤ Size: DeepSeek V4 Pro 1.6T total / 49B active; V4 Flash 284B total / 13B active
➤ License: MIT
➤ Availability: Available on DeepSeek's first-party API; we expect many third-party providers to host the models
➤ Pricing: DeepSeek V4 Pro $1.74 / $3.48 per 1M input/output tokens; V4 Flash $0.14 / $0.28 per 1M input/output tokens. Cache hit input token pricing is $0.145 for V4 Pro and $0.028 for V4 Flash per 1M tokens. V4 Pro is significantly more expensive than past DeepSeek R1 and V3 models
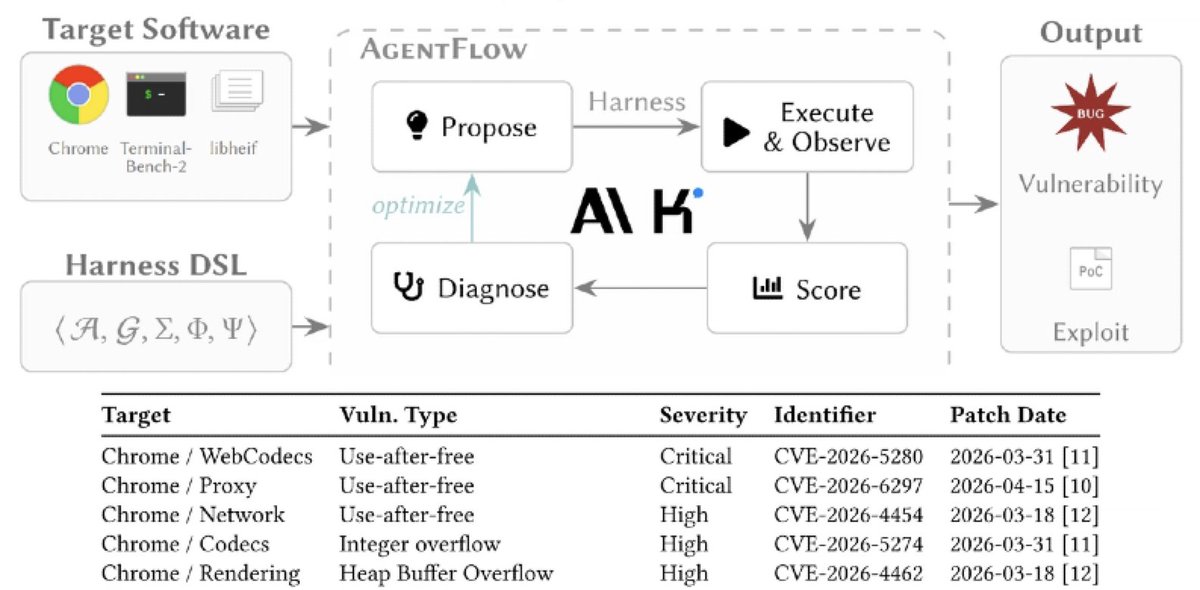
Chinese LLMs can hack better than state-sponsored hackers with properly evolved harness -
Kimi K2.5 managed to find and exploit 6 vulnerabilities in browsers: a single page view or an extension install by victims equal full system hijack.
Check https://t.co/d0SZSf1KqF
- super flat
- resilient
- intentionally understaffed
- to attract and retain people who are essentially a highly intelligent base model + superior agentic capabilities with ample tools and skills
sounds so familiar 🤭 @Kimi_Moonshot what do you think
Spoke at the AI club at Stanford last night. 1000 people tried to attend. Seating was capped at 250.
It was pandemonium at the end! If you’re a resilient, gritty engineer, PM, designer or GTM person, please consider working with us:
- We have no org chart - everyone reports to me. We do this to minimize politics, titles and force natural leaders to self organize.
- We are severely under manned for the work we have (by design) so you are forced to engineer your way out. Build solutions not orgs.
- We will book nine figures this year and are growing very quickly. Our customers span all major parts of the US Economy.
[email protected]
robinhood day 1 listing. probably nothing 🤭 @0xZergs what do you think?
I think previous pivots were all worth it, and with that level of founder resilience, https://t.co/oYrD6rZiU3 team has a real shot at building something truly great.
Moonshot’s Kimi K2.6 is the new leading open weights model. Kimi K2.6 lands at #4 on the Artificial Analysis Intelligence Index (54) behind only Anthropic, Google, and OpenAI (all 57)
Key takeaways:
➤ Increase in performance on agentic tasks: @Kimi_Moonshot's Kimi K2.6 achieves an Elo of 1520 on our GDPval-AA evaluation, which is a marked improvement over Kimi K2.5’s Elo of 1309. GDPval-AA is our leading metric for general agentic performance, measuring the performance on knowledge work tasks such as preparing presentations and analysis. Models are given code execution and web browsing tools in an agentic loop via our open source reference agentic harness called Stirrup. This continues Kimi K2.6’s strength in tool use, maintaining a 96% score on τ²-Bench Telecom, placing it among other frontier models in this category.
➤ Low hallucination rate: Kimi K2.5 scores 6 on the AA-Omniscience Index, our knowledge evaluation measuring both accuracy and hallucination rate. This score is primarily driven by a comparatively low hallucination rate of 39% (reduced from Kimi K2.5’s 65%), indicating a greater capability to abstain rather than fabricate knowledge when the model is uncertain. Kimi K2.6’s low hallucination rate places it similarly to other models such as Claude Opus 4.7 (36%) and MiniMax-M2.7 (34%)
➤ High token usage: Kimi K2.6 demonstrates high token usage, but is in line with other frontier models in the same intelligence tier. To run the full Artificial Analysis Intelligence Index, Kimi K2.6 used ~160M reasoning tokens. This is slightly lower than Claude Sonnet 4.6 (~190M reasoning tokens) but much higher than GPT 5.4 (~110M reasoning tokens).
➤ Open weights: Kimi K2.6 is a Mixture-of-Experts (MoE) model with 1T total parameters and 32B active, same as the previous two generations of models Kimi K2 Thinking and Kimi K2.5. Kimi K2.6 again pushes the open weights frontier in intelligence.
➤ Third Party Access: Kimi K2.6 is accessible through Moonshot’s First Party API as well as third party API providers Novita, Baseten, Fireworks, and Parasail
➤ Multimodality: Kimi K2.6 supports Image and Video input and text output natively. The model’s max context length remains 256k.
Further analysis in the threads below.
We open sourced Kimi K2.6. The next frontier in test-time compute isn't bigger models. It's better organizations of intelligence.
The hardest things were never built by one person. They require coordination. Different skills, different contexts, different minds arguing until something better emerges.
dear god lol - new kimi model is a fucking beast.
GPT 5.4 level coding, 76% cheaper than opus 4.7 and 100% open source / free to use, i mean look at this:
> kimi k2.6 can code continuously for 12 hours straight, run 300+ agents in parallel from a SINGLE prompt.
how the fuck is china doing this?
every 3 months theres a new open model that gets closer to the best claude/GPT models.
deepseek also releasing this week.
open source models have caught up and china of all countries are leading it!
Moonshot AI:
"Our RL infra team used a K2.6-backed agent that operated autonomously for 5 days, managing monitoring, incident response, and system operations, demonstrating persistent context, multi-threaded task handling, and full-cycle execution from alert to resolution"