@gabrielpeyre@YihongWu7 Classification and Regression Trees (CART) is a greedy heuristic that runs efficiently but does not offer a performance guarantee. (e.g. XOR-shaped data can still be problematic)
@gabrielpeyre@YihongWu7 Both the problems of finding the size-limited tree that minimizes loss and the smallest tree that achieves 0 loss are NP-complete. Dynamic programming can be used when the objective is separable w.r.t. the leaves, but this runs exponentially in tree size: https://t.co/O3GoetEdWw
@adad8m @_joaogui1 Yes, so input shape is 2 * p and output shape is p, in the figure p=97. I tried some other modular functions as well but I would have to do some digging to find my old code.
@adad8m @_joaogui1 Yes exactly! One-hot encoding and a 1 hidden layer MLP, trained with AdamW. The task used in the figures is modular addition. I wanted to see if I could get a minimal example where grokking occurs 🙂
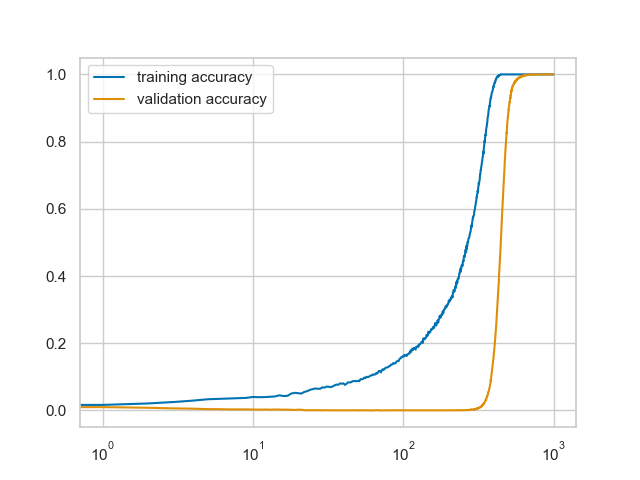
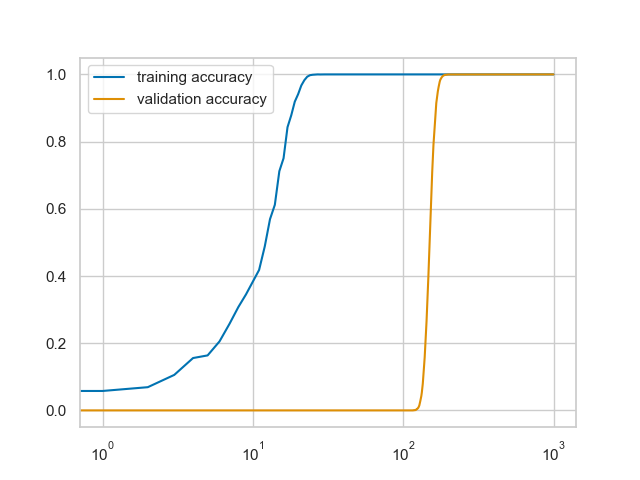
@_joaogui1 When I replicated this work with 1 hidden layer ReLU networks it did seem like increasing width increased the sharpness of the grokking effect by a bit. (left: 128 neurons, right: 8192)
@tverven @Hidde_Fokkema @RdeHeide Very interesting paper and I noticed it just while I was writing a section on the robustness of explanations! Great to see that the Dutch Railways were able to assist the paper with footnote 2 😄
If you are interested in robust optimization, decision trees, adversarial examples or all of the above, then come talk to me at #AAAI2022!
Our poster is featuring now and tonight starting at 17:45 GMT+1
@HochreiterSepp It’s interesting that you observed this with SGD! I have been working on reproducing the paper’s results and have only been successful with AdamW. For AdamW I agree with @ykilcher ‘s intuition that weight decay gives a smooth function, I wonder what happens with ‘grokking’ SGD.
I'm proud to announce that my paper with @siccoverwer "Robust Optimal Classification Trees Against Adversarial Examples" has been accepted at the #AAAI2022 conference! 🎊
Paper: https://t.co/qlFCD2IjwP
A thread with more details below 👇
Please check our paper for many more results: https://t.co/qlFCD2IjwP
And let's see if we can improve the efficiency of ROCT in the future to train deeper optimal trees. Soon I will explain more about the adversarial accuracy bound from the paper.
Excited to present the first paper for my PhD at #ICML2021, if you have any questions I would love to hear them at the virtual poster session (18:00-20:00 CEST)! #betterposter@analytics_cyber